AGI=lim(x->0)AIHype(x)
where x=length of winter
Is this certain? Are Agents the right direction to AGI?
I'm surprised that any of these companies consider what they are working on to be Artificial General Intelligences. I'm probably wrong, but my impression was AGI meant the AI is self aware like a human. An LLM hardly seems like something that will lead to self-awareness.
"Artificial General Intelligence (AGI) refers to a theoretical form of artificial intelligence that possesses the ability to understand, learn, and apply knowledge across a wide range of tasks at a level comparable to that of a human being."
Altman says AGI could be here in 2025: https://youtu.be/xXCBz_8hM9w?si=F-vQXJgQvJKZH3fv
But he certainly means an LLM that can perform at/above human level in most tasks rather than a self aware entity.
For example, in this article it says it can't do coding exercises outside the training set. That would definitely be on the "AGI checklist". Basically doing anything that is outside of the training set would be on that list.
So the models' accuracies won't grow exponentially, but can still grow linearly with the size of the training data.
Sounds like DataAnnotation will be sending out a lot more LinkedIn messages.
Where do these large "AI" companies think the mass amounts of data used to train these models come from? People! The most powerful and compact complex systems in existence, IMO.
The "hard problem", to which you may be alluding, may never matter. It's already feasible for an 'AI/AGI with LLM component' to be "self-aware".
EDIT: here's the paper https://arxiv.org/abs/2404.04125
Depends on how you define “self awareness” but knowing that it doesn't know something instead of hallucinating a plausible-but-wrong is already self awareness of some kind. And it's both highly valuable and beyond current tech's capability.
IMO this will require not just much more expansive multi-modal training, but also novel architecture, specifically, recurrent approaches; plus a well-known set of capabilities most systems don't currently have, e.g. the integration of short-term memory (context window if you like) into long-term "memory", either episodic or otherwise.
But these are as we say mere matters of engineering.
Is that "intelligent" or "understanding"? It's probably close enough for pop science, and regardless, it looks good in headlines and sales pitches so why fight it?
https://openai.com/index/introducing-simpleqa/
especially this section Using SimpleQA to measure the calibration of large language models
The best engineering minds have been focused on scaling transformer pre and post training for the last three years because they had good reason to believe it would work, and it has up until now.
Progress has been measured against benchmarks which are / were largely solvable with scale.
There is another emerging paradigm which is still small(er) scale but showing remarkable results. That's full multi-modal training with embodied agents (aka robots). 1x, Figure, Physical Intelligence, Tesla are all making rapid progress on functionality which is definitely beyond frontier LLMs because it is distinctly different.
OpenAI/Google/Anthropic are not ignorant of this trend and are also reviving or investing in robots or robot-like research.
So while Orion and Claude 3.5 opus may not be another shocking giant leap forward, that does not mean that there arn't giant shocking leaps forward coming from slightly different directions.
https://paperswithcode.com/paper/most-language-models-can-be...
The appearance of improvements in that capability are due to the vocabulary of modern LLMs increasing. Still only putting lipstick on a pig.
We use the term self-awareness as an all encompassing reference of our cognizant nature. It's much more than just having an internal model of self.
Or did you mean consciousness? How would one demonstrate that an AGI is conscious? Why would we even want to build one?
My understanding is an AGI is at least as smart as a typical human in every category. That is what would be useful in any case.
Isn't that literally the cause of the success of deep learning? It's not quite "free", but as I understand it, the big breakthrough of AlexNet (and much of what came after) was that running a larger CNN on a larger dataset allowed the model to be so much more effective without any big changes in architecture.
This is supported by both general observations and recently this tweet from an OpenAI engineer that Sam responded to and engaged ->
"scaling has hit a wall and that wall is 100% eval saturation"
Which I interpert to mean his view is that models are no longer yielding significant performance improvements because the models have maxed out existing evaluation metrics.
Are those evaluations (or even LLMs) the RIGHT measures to achieve AGI? Probably not.
But have they been useful tools to demonstrate that the confluence of compute, engineering, and tactical models are leading towards signifigant breathroughts in artificial (computer) intelligence?
I would say yes.
Which in turn are driving the funding, power innovation, public policy etc needed to take that next step?
I hope so.
With my user hat on, I'm quite pleased with the current state of LLMs. Initially, I approached them skeptically, using a hackish mindset and posing all kinds of Turing test-like questions. Over time, though, I shifted my focus to how they can enhance my team's productivity and support my own tasks in meaningful ways.
Finally, I see LLMs as a valuable way to explore parts of the world, accommodating the reality that we simply don’t have enough time to read every book or delve into every topic that interests us.
"Most people" naturally associate AGI with the sci-tropes of self-aware human-like agents.
But industries want something more concrete and prospectively-acheivable in their jargon, and so that's where AGI gets redefined as wide task suitability.
And while that's not an unreasonable definition in the context of the industry, it's one that vanishingly few people are actually familiar with.
And the commercial AI vendors benefit greatly from allowing those two usages to conflate in the minds of as many people as possible, as it lets them suggest grand claims while keeping a rhetorical "we obviously never meant that!" in their back pocket
A crucial element of AGI would be the ability to self-train on self-generated data, online. So it's not really AGI if there is a hard distinction between training and inference (though it may still be very capable), and it's not really AGI if it can't work its way through novel problems on its own.
The ability to immediately solve a problem it's never seen before is too high a bar, I think.
And yes, my definition still excludes a lot of humans in a lot of fields. That's a bullet I'm willing to bite.
What does this mean? If I have a blind, deaf, paralyzed person, who could only communicate through text, what would the signs be that they were self aware?
Is this more of a feedback loop problem? If I let the LLM run in a loop, and tell it it's talking to itself, would that be approaching "self aware"?
Meanwhile, the existing tech is such a step change that industry is going to need time to figure out how to effectively use these models. In a lot of ways it feels like the "digitization" era all over again - workflows and organizations that were built around the idea humans handled all the cognitive load (basically all companies older than a year or two) will need time to adjust to a hybrid AI + human model.
They are driving the shoveling of VC money into a furnace to power their servers.
Should that money run dry before they hit another breakthrough "AI" popularity is going to drop like a stone. I believe this to be far more likely an outcome than AGI or even the next big breakthrough.
I will get excited for/scared of LLMs when they can tackle this kind of problem. But I don't believe they can because of the fundamental nature of their design, which is both backward looking (thus not better than the human state of the art) and lacks human intuition and self awareness. Or perhaps rather I believe that the prompt that would be required to get an LLM to produce such a program is a problem of at least equivalent complexity to implementing the program without an LLM.
And if your "lipstick on a pig" argument is that even when they generate haikus, they aren't really writing haikus, then I'll link to this other gwern post, about how they'll never really be able to solve the rubik's cube - https://gwern.net/rubiks-cube
AlphaGo - self-play
AlphaFold - PDB, the protein database
ChatGPT - human knowledge encoded as text
These models are all machines for clever interpolation in gigantic training datasets.
They appear to be intelligent, because the training data they've seen is so vastly larger than what we've seen individually, and we have poor intuition for this.
I'm not throwing shade, I'm a daily user of ChatGPT and find tremendous and diverse value in it.
I'm just saying, this particular path in AI is going to make step-wise improvements whenever new large sources of training data become available.
I suspect the path to general intelligence is not that, but we'll see.
Sure, that's tautologically true but that doesn't imply that beyondness will lead to significant leaps that offer notable utility like LLMs. Deep Learning overall has been a way around the problem that intelligent behavior is very hard to code and no wants to hire many, many coders needed to do this (and no one actually how to get a mass of programmers to actually be useful beyond a certain of project complexity, to boot). People take the "bitter lesson" to mean data can do anything but I'd say a second bitter lesson is that data-things are the low hanging fruit.
Moreover, robot behavior is especially to fake. Impressive robot demos have been happening for decades without said robots getting the ability to act effectively in the complex, ad-hoc environment that human live in, IE, work with people or even cheaply emulate human behavior (but they can do choreographed/puppeteered kung fu on stage).
Yes, because we understand the rough biological processes that cause this, and they are not remotely similar to this technology. We can also observe it. There is no evidence that current approaches can make LLM's achieve AGI, nor do we even know what processes would cause that.
Nah, at best we found a way to make one part of a collection of systems that will, together, do something like thinking. Thinking isn’t part of what this current approach does.
What’s most surprising about modern LLMs is that it turns out there is so much information statistically encoded in the structure of our writing that we can use only that structural information to build a fancy Plinko machine and not only will the output mimic recognizable grammar rules, but it will also sometimes seem to make actual sense, too—and the system doesn’t need to think or actually “understand” anything for us to, basically, usefully query that information that was always there in our corpus of literature, not in the plain meaning of the words, but in the structure of the writing.
LLMs already outperform humans in a huge variety of tasks. ML in general outperform humans in a large variety of tasks. Are all of them AGI? Doubtful.
[0] https://www.metaculus.com/questions/5121/date-of-artificial-...
When I read stuff like this it makes me wonder if people are actually using any of the LLMs...
Sometimes other outlets do copycat reporting of theirs, and those submissions are ok, though they wouldn't be if the original source were accessible.
Right. If you generate some code with ChatGPT, and then try to find similar code on the web, you usually will. Search for unusual phrases in comments and for variable names. Often, something from Stack Overflow will match.
LLMs do search and copy/paste with idiom translation and some transliteration. That's good enough for a lot of common problems. Especially in the HTML/Javascript space, where people solve the same problems over and over. Or problems covered in textbooks and classes.
But it does not look like artificial general intelligence emerges from LLMs alone.
There's also the elephant in the room - the hallucination/lack of confidence metric problem. The curse of LLMs is that they return answers which are confident but wrong. "I don't know" is rarely seen. Until that's fixed, you can't trust LLMs to actually do much on their own. LLMs with a confidence metric would be much more useful than what we have now.
Up to a certain point, a conditional fluency stores knowledge, in the sense that semantically correct sentences are more likely to be fluent… but we may have tapped out in that regard. LLMs have solved language very well, but to get beyond that has seemed, thus far, to require RLHF, with all the attendant negatives.
https://plato.stanford.edu/entries/chinese-room/
Yet, one common assumption of many people running these companies or investing in them, or of some developers investing their time in these technologies, is precisely that some sort of explosion of superintelligence is likely, or even inevitable.
It surely is possible, but stretching that to likely seems a bit much if you really think how imperfectly we understand things like consciousness and the mind.
Of course there are people who have essentially religious reactions to the notion that there may be limits to certain domains of knowledge. Nonetheless, I think that's the reality we're faced with here.
People who "follow" AI, as the latest fad they want to comment on and appear intelligent about, repeat things like this constantly, even though they're not actually true for anything but the most trivial hello-world types of problems.
I write code all day every day. I use Copilot and the like all day every day (for me, in the medical imaging software field), and all day every day it is incredibly useful and writes nearly exactly the code I would have written, but faster. And none of it appears anywhere else; I've checked.
This seems like the most viable path to me as well (educational background in neuroscience but don't work in the field). The brain is composed of many specialised regions which are tuned for very specific tasks.
LLMs are amazing and they go some way towards mimicking the functionality provided by Broca's and Wernicke's areas, and parts of the cerebrum, in our wetware, however a full brain they do not make.
The work on robots mentioned elsewhere in the thread is a good way to develop cerebellum like capabilities (movement/motor control), and computer vision can mimic the lateral geniculate nucleus and other parts of the visual cortex.
In nature it takes all these parts working together to create a cohesive mind, and it's likely that an artificial brain would also need to be composed of multiple agents, instead of just trying to scale LLMs indefinitely.
I lead a team exploring cutting edge LLM applications and end-user features. It's my intuition from experience that we have a LONG way to go.
GPT-4o / Claude 3.5 are the go-to models for my team. Every combination of technical investment + LLMs yields a new list of potential applications.
For example, combining a human-moderated knowledge graph with an LLM with RAG allows you to build "expert bots" that understand your business context / your codebase / your specific processes and act almost human-like similar to a coworker in your team.
If you now give it some predictive / simulation capability - eg: simulate the execution of a task or project like creating a github PR code change, and test against an expert bot above for code review, you can have LLMs create reasonable code changes, with automatic review / iteration etc.
Similarly there are many more capabilities that you can ladder on and expose into LLMs to give you increasingly productive outputs from them.
Chasing after model improvements and "GPT-5 will be PHD-level" is moot imo. When did you hire a PHD coworker and they were productive on day-0 ? You need to onboard them with human expertise, and then give them execution space / long-term memories etc to be productive.
Model vendors might struggle to build something more intelligent. But my point is that we already have so much intelligence and we don't know what to do with that. There is a LOT you can do with high-schooler level intelligence at super-human scale.
Take a naive example. 200k context windows are now available. Most people, through ChatGPT, type out maybe 1500 tokens. That's a huge amount of untapped capacity. No human is going to type out 200k of context. Hence why we need RAG, and additional forms of input (eg: simulation outcomes) to fully leverage that.
The best minds don't follow the herd.
The theory behind these models so aggressively lags the engineering that I suspect there are many major improvements to be found just by understanding a bit more about what these models are really doing and making re-designs based on that.
I highly encourage anyone seriously interested in LLMs to start spending more time in the open model space where you can really take a look inside and play around with the internals. Even if you don't have the resources for model training, I feel personally understanding sampling and other potential tweaks to the model (lots of neat work on uncertainty estimations, manipulating the initial embedding the prompts are assigned, intelligent backtracking, etc).
And from a practical side I've started to realize that many people have been holding on of building things waiting for "that next big update", but there a so many small, annoying tasks that can be easily automated.
A future of people interacting with humanoid robots seems like cheesy sci-fi dream, same as a future of people flitting about in flying cars. However, if we really did want to create robots like this that took care not to damage themselves, and could empathize with human emotions, then we'd need to build a lot of this in, the same way that it's built into ourselves.
Because I had no idea how these were built until I read the paper, so couldn’t really tell what sort of tree they’re barking up. The failure-modes of LLMs and ways prompts affect output made a ton more sense after I updated my mental model with that information.
(That’s not to say that humans don’t tend to lose some of their flexibility over their individual lifetimes as well.)
If it acts like one, whether you call a machine conscious or not is pure semantics. Not like potential consequences are any less real.
>LLMs already outperform humans in a huge variety of tasks.
Yes, LLMs are General Intelligences and if that is your only requirement for AGI, they certainly already are[0]. But the definition above hinges on long-horizon planning and competence levels that todays models have generally not yet reached.
>ML in general outperform humans in a large variety of tasks.
This is what the G in AGI is for. Alphafold doesn't do anything but predict proteins. Stockfish doesn't do anything but play chess.
>Are all of them AGI? Doubtful.
Well no, because they're missing the G.
[0] https://www.noemamag.com/artificial-general-intelligence-is-...
Nor does it mean that there are! We've gotten into this habit of assuming that we're owed giant shocking leaps forward every year or so, and this wave of AI startups raised money accordingly, but that's never how any innovation has worked. We've always followed the same pattern: there's a breakthrough which causes a major shift in what's possible, followed by a few years of rapid growth as engineers pick up where the scientists left off, followed by a plateau while we all get used to the new normal.
We ought to be expecting a plateau, but Sam Altman and company have done their work well and have convinced many of us that this time it's different. This time it's the singularity, and we're going to see exponential growth from here on out. People want to believe it, so they do, and Altman is milking that belief for all it's worth.
But make no mistake: Altman has been telegraphing that he's eyeing the exit, and you don't eye the exit when you own a company that's set to continue exponentially increasing in value.
https://en.m.wikipedia.org/wiki/Five_Years_(David_Bowie_song...
I’ve noticed this too — I’ve been calling it intellectual deflation. By analogy, why spend now when it may be cheaper in a month? Why do the work now, when it will be easier in a month?
(And by limitations I don’t mean “sorry, I’m not allowed to help you with this dangerous/contentious topic”.)
Action oriented through self exploration? What is your thought for how these systems integrate with the existing world?
Why does the OP's suggested mode of integration make you think of those older systems?
I think there's three things that a 'true' general intelligence has which is missing from basic-type-LLMs as we have now.
1. knowing what you know. <basic-LLMs are here>
2. knowing what you don't know but can figure out via tools/exploration. <this is tool use/function calling>
3. knowing what can't be known. <this is knowing that halting problem exists and being able to recognize it in novel situations>
(1) From an LLM's perspective, once trained on corpus of text, it knows 'everything'. It knows about the concept of not knowing something (from having see text about it), (in so far as an LLM knows anything), but it doesn't actually have a growable map of knowledge that it knows has uncharted edges.
This is where (2) comes in, and this is what tool use/function calling tries to solve atm, but the way function calling works atm, doesn't give the LLM knowledge the right way. I know that I don't know what 3,943,034 / 234,893 is. But I know I have a 'function call' of knowing the algorithm for doing long divison on paper. And I think there's another subtle point here: my knowledge in (1) includes the training data generated from running the intermediate steps of the long-division algorithm. This is the knowledge that later generalizes to being able to use a calculator (and this is also why we don't just give kids calculators in elementary school). But this is also why a kid that knows how to do long division on paper, doesn't seperately need to learn when/how to use a calculator, besides the very basics. Using a calculator to do that math feels like 1 step, but actually it does still have all of initial mechanical steps of setting up the problem on paper. You have to type in each digit individually, etc.
(3) I'm less sure of this point now that I've written out point (1) and (2), but that's kinda exactly the thing I'm trying to get at. Its being able to recognize when you need more practice of (1) or more 'energy/capital' for doing (2).
Consider a burger resturant. If you properly populated the context of a ChatGPT-scale model the data for a burger resturant from 1950, and gave it the kinda 'function calling' we're plugging into LLMs now, it could manage it. It could keep track of inventory, it could keep tabs on the employee-subprocesses, knowing when to hire, fire, get new suppliers, all via function calling. But it would never try to become McDonalds, because it would have no model of the the internals of those function-calls, and it would have no ability to investigate or modify the behaviour of those function calls.
> I suspect the path to general intelligence is not that, but we'll see.
I think there's three things that a 'true' general intelligence has which is missing from basic-type-LLMs as we have now.
1. knowing what you know. <basic-LLMs are here>
2. knowing what you don't know but can figure out via tools/exploration. <this is tool use/function calling>
3. knowing what can't be known. <this is knowing that halting problem exists and being able to recognize it in novel situations>
(1) From an LLM's perspective, once trained on corpus of text, it knows 'everything'. It knows about the concept of not knowing something (from having see text about it), (in so far as an LLM knows anything), but it doesn't actually have a growable map of knowledge that it knows has uncharted edges.
This is where (2) comes in, and this is what tool use/function calling tries to solve atm, but the way function calling works atm, doesn't give the LLM knowledge the right way. I know that I don't know what 3,943,034 / 234,893 is. But I know I have a 'function call' of knowing the algorithm for doing long divison on paper. And I think there's another subtle point here: my knowledge in (1) includes the training data generated from running the intermediate steps of the long-division algorithm. This is the knowledge that later generalizes to being able to use a calculator (and this is also why we don't just give kids calculators in elementary school). But this is also why a kid that knows how to do long division on paper, doesn't seperately need to learn when/how to use a calculator, besides the very basics. Using a calculator to do that math feels like 1 step, but actually it does still have all of initial mechanical steps of setting up the problem on paper. You have to type in each digit individually, etc.
(3) I'm less sure of this point now that I've written out point (1) and (2), but that's kinda exactly the thing I'm trying to get at. Its being able to recognize when you need more practice of (1) or more 'energy/capital' for doing (2).
Consider a burger resturant. If you properly populated the context of a ChatGPT-scale model the data for a burger resturant from 1950, and gave it the kinda 'function calling' we're plugging into LLMs now, it could manage it. It could keep track of inventory, it could keep tabs on the employee-subprocesses, knowing when to hire, fire, get new suppliers, all via function calling. But it would never try to become McDonalds, because it would have no model of the the internals of those function-calls, and it would have no ability to investigate or modify the behaviour of those function calls.
But understanding how likely it is that we will (or will not) see a new models quickly and dramatically improve on what we have "because scaling" seems valuable context for everyone in ecosystem to make decisions.
IMO we've not even exhausted the options for spreadsheets, let alone LLMs.
And the reason I'm thinking of spreadsheets is that they, like LLMs, are very hard to win big on even despite the value they bring. Not "no moat" (that gets parroted stochastically in threads like these), but the moat is elsewhere.
At the very early phase of the boom I was among a very few who knew and predicted this (usually most free and deep thinking/knowledgeable). Then my prediction got reinforced by the results. One of the best examples was with one of my experiments that all today's AI's failed to solve tree serialization and de-serialization in each of the DFS(pre-order/in-order/post-order) or BFS(level-order) which is 8 algorithms (2x4) and the result was only 3 correct! Reason is "limited training inputs" since internet and open source does not have other solutions :-) .
So, I spent "some" time and implemented all 8, which took me few days. By the way this proves/demonstrates that ~15-30min pointless leetcode-like interviews are requiring to regurgitate/memorize/not-think. So, as a logical hard consequence there will.has-to be a "crash/cleanup" in the area of leetcode-like interviews as they will just be suddenly proclaimed as "pointless/stupid"). However, I decided not to publish the rest of the 5 solutions :-)
This (and other experiments) confirms hard limits of the LLM approach (even when used with chain-of-thought). Increasing the compute on the problem will produce increasingly smaller and smaller results (inverse exponential/logarithmic/diminishing-returns) = new AGI approach/design is needed and to my knowledge majority of the inve$tment (~99%) is in LLM, so "buckle up" at-some-point/soon?
Impacts and realities; LLM shall "run it's course" (produce some products/results/$$$, get reviewed/$corrected) and whoever survives after that pruning shall earn money on those products while investing in the new research to find new AGI design/approach (which could take quite a long time,... or not). NVDA is at the center of thi$ and time-wise this peak/turn/crash/correction is hard to predict (although I see it on the horizon and min/max time can be estimated). Be aware and alert. I'll stop here and hold my other number of thoughts/opinions/ideas for much deeper discussion. (BTW I am still "full in on NVDA" until,....)
That’s possible for a highly intelligent, extensively trained, very small subset of humans.
The > 100 P/E ratios we are already seeing can't be justified by something as quotidian as the exceptionally good productivity tools you're talking about.
Going from 10% to 50% (500% more) complete coverage of common sense knowledge and reasoning is going to feel like a significant advance. Going from 90% to 95% (5% more) coverage is not going to feel the same.
Regardless of what Altman says, its been two years since OpenAI released GPT-4, and still no GPT-5 in sight, and they are now touting Q-star/strawberry/GPT-o1 as the next big thing instead. Sutskever, who saw what they're cooking before leaving, says that traditional scaling has plateaeud.
I think Searle's view was that:
- while it cannot be dis-_proven_, the Chinese Room argument was meant to provide reasons against believing it
- the "it can't be proven until it happens" part is misunderstanding: you won't know if it happens because the objective, externally available attributes don't indicate whether self-awareness (or indeed awareness at all) is present
Cool, but we already have robots doing this in 2d space (aka self driving cars) that struggle not to kill people. How is adding a third dimension going to help? People are just refusing to accept the fact that machine learning is not intelligence.
It doesn't matter if that's happening or not. That's the whole point of the Chinese room - if it can look like it's understanding, it's indistinguishable from actually understanding. This applies to humans too. I'd say most of our regular social communication is done in a habitual intuitive way without understanding what or why we're communicating. Especially the subtle information conveyed in body language, tone of voice, etc. That stuff's pretty automatic to the point that people have trouble controlling it if they try. People get into conflicts where neither person understands where they disagree but they have emotions telling them "other person is being bad". Maybe we have a second consciousness we can't experience and which truly understands what it's doing while our conscious mind just uses the results from that, but maybe we don't and it still works anyway.
Educators have figured this out. They don't test students' understanding of concepts, but rather their ability to apply or communicate them. You see this in school curricula with wording like "use concept X" rather than "understand concept X".
For LLMs, we don't even know how to reliably measure performance, much less plan for expected improvements.
Can you think of any specific examples? Not trying to express disbelief, just curious given that this is obviously not what he's intending to communicate so it would be interesting to examine what seemed to communicate it.
However, this is better thought of as "business logic scripting/automation", not the magic employee-replacing AGI that would be the revolution some people are expecting. Maybe you can now build a slightly less shitty automated telephone response system to piss your customers off with.
Certainly not.
But technology is all about stacks. Each layer strives to improve, right up through UX and business value. The uses for 1µm chips had not been exhausted in 1989 when the 486 shipped in 800nm. 250nm still had tons of unexplored uses when the Pentium 4 shipped on 90nm.
Talking about scaling at the the model level is like talking about transistor density for silicon: it's interesting, and relevant, and we should care... but it is not the sole determinent of what use cases can be build and what user value there is.
The scaling laws may be dead. Does this mean the end of LLM advances? Absolutely not.
There are many different ways to improve LLM capabilities. Everyone was mostly focused on the scaling laws because that worked extremely well (actually surprising most of the researchers).
But if you're keeping an eye on the scientific papers coming out about AI, you've seen the astounding amount of research going on with some very good results, that'll probably take at least several months to trickle down to production systems. Thousands of extremely bright people in AI labs all across the world are working on finding the next trick that boosts AI.
One random example is test-time compute: just give the AI more time to think. This is basically what O1 does. A recent research paper suggests using it is roughly equivalent to an order of magnitude more parameters, performance wise. (source for the curious: https://lnkd.in/duDST65P)
Another example that sounds bonkers but apparently works is quantization: reducing the precision of each parameter to 1.58 bits (ie only using values -1, 0, 1). This uses 10x less space for the same parameter count (compared to standard 16-bit format), and since AI operatons are actually memory limited, directly corresponds to 10x decrease in costs: https://lnkd.in/ddvuzaYp
(Quite apart from improvements like these, we shouldn't forget that not all AIs are LLMs. There's been tremendous advance in AI systems for image, audio and video generation, interpretation and munipulation and they also don't show signs of stopping, and there's possibility that a new or hybrid architecture for the textual AI might be developed).
AI winter is a long way off.
What are you basing this on?
IT outsourcing is a $500+ billion industry. If OpenAI et al can run even a 10% margin, that business alone justifies their valuation.
Yes there seems to be lots of potential. Yes we can brainstorm things that should work. Yes there is a lot of examples of incredible things in isolation. But it's a little bit like those youtube videos showing amazing basketball shots in 1 try, when in reality lots of failed attempts happened beforehand. Except our users experience the failed attempts (LLM replies that are wrong, even when backed by RAG) and it's incredibly hard to hide those from them.
Show me the things you / your team has actually built that has decent retention and metrics concretely proving efficiency improvements.
LLMs are so hit and miss from query to query that if your users don't have a sixth sense for a miss vs a hit, there may not be any efficiency improvement. It's a really hard problem with LLM based tools.
There is so much hype right now and people showing cherry picked examples.
I agree that a hypothetical perfectly-functioning Chinese room is, tautologically, impossible to distinguish from a real person who speaks Chinese, but that’s a thought experiment, not something that can actually exist. There’ll remain places where the “behavior” breaks down in ways that would be surprising from a human who’s actually paying as much attention as they’d need to be to have been interacting the way they had been until things went wrong.
That, in fact, is exactly where the difference lies: the LLM is basically always not actually “paying attention” or “thinking” (those aren’t things it does) but giving automatic responses, so you see failures of a sort that a human might also exhibit when following a social script (yes, we do that, you’re right), but not in the same kind of apparently-highly-engaged context unless the person just had a stroke mid-conversation or something—because the LLM isn’t engaged, because being-engaged isn’t a thing it does. When it’s getting things right and seeming to be paying a lot of attention to the conversation, it’s not for the same reason people give that impression, and the mimicking of present-ness works until the rule book goes haywire and the ever-gibbering player-piano behind it is exposed.
I wasn’t able to get it do it with Anthropic or OpenAI chat completion APIs. Can someone explain why? I don’t think the 200K token window actually works, is it looking sequentially or is it really looking at the whole thing at once or something?
Is it just me or does $100 million sound like it's on the very, very low end of how much training a new model costs? Maybe you can arrive within $200 million of that mark with amortization of hardware? It just doesn't make sense to me that a new model would "only" be $100 million when AmaGooBookSoft are spending tens of billions on hardware and the AI startups are raising billions every year or two.
That's not true. Humans can learn.
An LLM is just a tool. If it can't do what you want then too bad.
If I had evidence that it "is true" that AGI will be here in 5 years, I probably would be doing something else with my time than participating in these threads ;)
Most other businesses trying to actually use LLMs are the riskier ones, including OpenAI, IMO (though OpenAI is perhaps the least risky due to brand recognition).
This has been my team's experience (and frustration) as well, and has led us to look at using LLMs for classifying / structuring, but not entrusting an LLM with making a decision based on things like a database schema or business logic.
I think the technology and tooling will get there, but the enormous amount of effort spent trying to get the system to "do the right thing" and the nondeterministic nature have really put us into a camp of "let's only allow the LLM to do things we know it is rock-solid at."
Because of that, the discussion of what AGI means in its broadest sense, will never end.
So in fact such AGI discussion will not make nobody wiser.
I don't know how many team meetings PhD students have, but I do know about software development jobs with 15 minute daily standups, and that length meeting at 120 words per minute for 5 days a week, 48 weeks per year of a 3 year PhD is 1.296.000 words.
- Jim Keller
https://www.youtube.com/live/oIG9ztQw2Gc?si=oaK2zjSBxq2N-zj1...
That doesn't mean this article is irrelevant. It's good to know if LLM improvements are going to slow down a bit because the low hanging fruit has seemingly been picked.
But in terms of the overall effect of AI and questioning the validity of the technology as a whole, it's just your basic FUD article that you'd expect from mainstream news.
It's been 20 months since 4 was released. 3 was released 32 months after 2. The lack of a release by now in itself does not mean much of anything.
That also ignores the fact that the small set of humans capable of building programming languages and compilers is a consequence of specialization and lack of interest. There are plenty of humans that are capable of learning how to do it. LLMs, on the other hand, are both specialized for the task and aren't lazy or uninterested.
Is there an AI tool that can ingest a codebase and locate code based on abstract questions? Like: "I need to invalidate customers who haven't logged in for a month" and it can locate things like relevant DB tables, controllers, services, etc.
Even assuming the recent robot demo was entirely AI, the only single thing they demonstrated that would have been noteworthy was isolating one voice in a noisy crowd well enough to respond; everything else I saw Optimus do, has already been demonstrated by others.
What makes the uncertainty extra sad, is that a remote controllable humanoid robot is already directly useful for work in hazardous environments, and we know they've got at least that… but Musk would rather it be about the AI.
at the end of the day though, it's not exactly reliable or particularly transformative when you get past the party tricks
But even more, maybe consciousness is an invention of our 'explaining self', maybe everything is automatic. I'm convinced this discussion is and will stay philosophical and will never get any conclusion.
Imagine that our current capabilities are like the Model-T. There remains many improvements to be made upon this passenger transportation product, with RAG being a great common theme among them. People will use chatbots with much more permissive interfaces instead of clicking through menus.
But all of that’s just the start, the short term, the maturation of this consumer product; the really scary/exciting part comes when the technology reaches saturation, and opens up new possibilities for itself. In the Model-T metaphor, this is analogous to how highways have (arguably) transformed America beyond anyone’s wildest dreams, changing the course of various historical events (eg WWII industrialization, 60s & 70s white flight, early 2000s housing crisis) so much it’s hard to imagine what the country would look like without them. Now, automobiles are not simply passenger transportation, but the bedrock of our commerce, our military, and probably more — through ubiquity alone they unlocked new forms of themselves.
For those doubting my utopian/apocalyptic rhetoric, I implore you to ask yourself one simple question: why are so many experts so worried about AGI? They’ve been leaving in droves from OpenAI, and that’s ultimately what the governance kerfluffle there was. Hinton, a Turing award winner, gave up $$$ to doom-say full time. Why?
My hint is that if your answer involves less then a 1000 specialized LLMs per unified system, then you’re not thinking big enough.
In general, this is not a good description about what is happening inside an LLM. There is extensive literature on interpretability. It is complicated and still being worked out.
The commenter above might characterize the results they get in this way, but I would question the validity of that characterization, not to mention its generality.
A human doesn’t just confidently spew paragraphs legit-looking but entirely wrong crap, unless they’re trying to deceive or be funny—an LLM isn’t trying to do anything, though, there’s no motivation, it doesn’t like you (it doesn’t like—it doesn’t it, one might even say), sometimes it definitely will just give you a beautiful and elaborate lie simply because its rulebook told it to, in a context and in a way that would be extremely weird if a person did it.
The meaning here is different. What I'm saying is that big companies like OpenAI will always strive to make a generic AI, such that anyone can do basically anything using AI. The big companies therefore will indeed (like you say) have a profitable business, but few others will.
I probably disagree, but I don't want to criticize my interpretation of this sentence. Can you make your claim more precise?
Here are some possible claims and refutations:
- Claim: An LLM cannot output a true claim that it has not already seen. Refutation: LLMs have been shown to do logical reasoning.
- Claim: An LLM cannot incorporate data that it hasn't been presented with. Refutation: This is an unfair standard. All forms of intelligence have to sense data from the world somehow.
Why do you think "they" have run out of data? First, to be clear, who do you mean by "they"? The world is filled with information sources (data aggregators for example), each available to some degree for some cost.
Don't forget to include data that humans provide while interacting with chatbots.
The term itself (AGI) in the industry has always been about wide task suitability. People may have added their ifs and buts over the years but that aspect of it never got 'redefined'. The earliest uses of the term all talk about how well a machine would be able to perform some set number of tasks at some threshold.
It's no wonder why. Terms like "consciousness" and "self-awareness" are completely useless. It's not about difficulty. It's that you can't do anything at all with those terms except argue around in circles.
A lot hangs on what you mean by "significant". Can you define what you mean? And/or give an example of an improvement that you don't think is significant.
Also, on what basis can you say "no significant improvements" have been made? Many major players have published some of their improvements openly. They also have more private, unpublished improvements.
If your claim boils down to "what people mean by a Generative Pre-trained Transformer" still has a clear meaning, ok, fine, but that isn't the meat of the issue. There is so much more to a chat system than just the starting point of a vanilla GPT.
It is wiser to look at the whole end-to-end system, starting at data acquisition, including pre-training and fine-tuning, deployment, all the way to UX.
P.S. I don't have a vested interest in promoting or disparaging AI. I don't work for a big AI lab. I'm just trying to call it like I see it, as rationally as I can.
The Emperor has no clothes.
Even this is insanely hard in my opinion. The one thing that you would assume LLM to excel at is spelling and grammar checking for the English language, but even the top model (GPT-4o) can be insanely stupid/unpredictable at times. Take the following example from my tool:
https://app.gitsense.com/?doc=6c9bada92&model=GPT-4o&samples...
5 models are asked if the sentence is correct and GPT-4o got it wrong all 5 times. It keeps complaining that GitHub is spelled like Github, when it isn't. Note, only 2 weeks ago, Claude 3.5 Sonnet did the same thing.
I do believe LLM is a game changer, but I'm not convinced it is designed to be public-facing. I see LLM as a power tool for domain experts, and you have to assume whatever it spits out may be wrong, and your process should allow for it.
Edit:
I should add that I'm convinced that not one single model will rule them all. I believe there will be 4 or 5 models that everybody will use and each will be used to challenge one another for accuracy and confidence.
I'd love to hear about this. I applied to YC WC 25 with research/insight/an initial researchy prototype built on top of GPT4+finetuning about something along this idea. Less powerful than you describe, but it also works without the human moderated KG.
Then there are those who are simply narcissistic, and cannot and will not admit fault regardless of the evidence presented them.
This exactly. And as history shows, no matter how much effort the current big LLM companies do they won't be able to grasp the best uses for their tech. We will see small players developing it even further. I'm thankful for the legendary blindness of these anticompetitive behemoths. Less than 2 decades ago: IBM Watson.
Nobody knows how things like coding assistants or other AI applications will pan out. Maybe it'll be Oracle selling Meta-licenced solutions that gets the lion's share of the market. Maybe custom coding goes away for many business applications as off-the-shelf solutions get smarter.
A future where all that AI (or some hypothetical AGI) changes is work being done by humans to the same work being done by machines seems way too linear.
Nobody who takes code health and sustainability seriously wants to hear this. You absolutely do not want to be in a position where something breaks, but your last 50 commits were all written and reviewed by an LLM. Now you have to go back and review them all with human eyes just to get a handle on how things broke, while customers suffer. At this scale, it's an effort multiplier, not an effort reducer.
It's still good for generating little bits of boilerplate, though.
What do you mean by novel? Almost all sentences it is prompted on are brand new and it mostly responds sensibly. Surely there's some generalization going on.
Once massively useful AI has been achieved, or it's been determined that LLMs are it, then it becomes a race to the bottom as GOOG/MSFT/AMZN/META/etc design/deploy more specialized accelerators to deliver this final form solution as cheaply as possible.
Doesn’t need to be comprehensive, I just don’t know where to jump off from.
But Goodhart's law; "When a measure becomes a target, it ceases to be a good measure"
Directly applies here, Moore's Law was used to set long term plans at semiconductor companies, and Moore didn't have empirical evidence it was even going to continue.
If you say, arbitrarily decide CPU, or worse, single core performance as your measurement, it hasn't held for well over a decade.
If you hold minimum feature size without regard to cost, it is still holding.
What you want to prove usually dictates what interpretation you make.
That said, the scaling law is still unknown, but you can game it as much as you want in similar ways.
GPT4 was already hinting at an asymptote on MMLU, but the question is if it is valid for real work etc...
Time will tell, but I am seeing far less optimism from my sources, but that is just anecdotal.
> while it cannot be dis-_proven_, the Chinese Room argument was meant to provide reasons against believing it
Yes, like Russell's teapot. I also think that's what Searle means.
> the "it can't be proven until it happens" part is misunderstanding: you won't know if it happens because the objective, externally available attributes don't indicate whether self-awareness (or indeed awareness at all) is present
Yes, agreed, I believe that's what Searle is saying too. I think I was maybe being ambiguous here - I wanted to say that even if you forgave the AI maximalists for ignoring all relevant philosophical work, the notion that "appearing human-like" inevitably tends to what would actually be "consciousness" or "intelligence" is more than a big claim.
Searle goes further, and I'm not sure if I follow him all the way, personally, but it's a side point.
Also we only hear / see the examples that are meant to scale. Startups typically offer up something transformative, ready to soak up a segment of a market. And that’s hard with the current state of LLMs. When you try their offerings, it’s underwhelming. But there is richer, more nuanced hard to reach fruits that are extremely interesting - but it’s not clear where they’d scale in and of themselves.
In theory, yes you could generate an unlimited amount of data for the models, but how much of it is unique or valuable information? If you were to compress all this generated training data using a really good algorithm, how much actual information remains?
Tesla is selling this view for almost a decade now in self-driving - how their car fleet feeding training data is going to make them leaders in the area. I don't find it convincing anymore
If we have robots that operate in 3D, they'll be able to kill you not only from behind or from the side, but also from above. So that's progress!
1. more data gets walled-off as owners realise value
2. stackoverflow-type feedback loops cease to exist as few people ask a public question and get public answers ... they ask a model privately and get an answer based on last visible public solutions
3. bad actors start deliberately trying to poison inputs (if sites served malicious responses to GPTBot/CCBot crawlers only, would we even know right now?)
4. more and more content becomes synthetically generated to the point pre-2023 physical books become the last-known-good knowledge
5. goverments and IP lawyers finally catch up
The big one being I'm not assuming AGI. Low-level coding tasks, the kind frequently outsourced, are within the realm of being competitive with offshoring with known methods. My point is we don't need to assume AGI for these valuations to make sense.
I would argue that learning is The definition of AGI, since everything else comes naturally from that.
The current architectures can't learn without retraining, fine tuning is at the expense of general knowledge, and keeping things in context is detrimental to general performance. Once you have few shot learning, I think it's more of a "give it agency so it can explore" type problem.
Sutskever, recently ex. OpenAI, one of the first to believe in scaling, now says it is plateauing. Do OpenAI have something secret he was unaware of? I doubt it.
FWIW, GPT-2 and GPT-3 were about a year apart (2019 "Language models are Unsupervised Multitask Learners" to 2020 "Language Models are Few-Shot Learners").
Dario Amodei recently said that with current gen models pre-training itself only takes a few months (then followed by post-training, etc). These are not year+ training runs.
So the problem is more in the algorithm.
I think this behavior is being somewhat demonstrated in newer models. I've seen GPT-3.5 175B correct itself mid response with, almost literally:
> <answer with flaw here>
> Wait, that's not right, that <reason for flaw>.
> <correct answer here>.
Later models seem to have much more awareness of, or "weight" towards, their own responses, while generating the response.
Things like drive a car, fold laundry, run an errand, do some basic math.
You'll notice that two of those require some form of robot or mobility. I think that is key -- you can't have AGI without the ability to interact with the world in a way similar to most humans.
I've personally had some mild success getting these UTM variants to output their own children in a meta programming arrangement. The base program only has access to the valid instruction set of ~12 instructions per byte, while the task program has access to the full range of instructions and data per byte (256). By only training the base program, we reduce the search space by a very substantial factor. I think this would be similar to the idea of a self-hosted compiler, etc. I don't think there would be too much of a stretch to give it access to x86 instructions and a full VM once a certain amount of bootstrapping has been achieved.
[0]: https://arxiv.org/abs/2406.19108
That means employees who use LLM are, on average, recognizably bad. Those who are good enough, are also good enough to write the code manually.
To the point I wonder whether this HN thread is generated by OpenAI, trying to create buzz around AI.
We don't have a rough understanding of the biological processes that cause this, unless you literally mean just the biological process and not how it actual impacts learning/intelligence.
There's no evidence that we (brains) have achieved AGI, unless you tautologically define AGI as our brains.
The irony here is astounding.
What gets pushed out isn’t the last version of the document itself (since it’s FIFO), but the important parts of the conversation—things like the rationale, requirements, or any context the model needs to understand why it’s making changes. So, instead of being helpful, that extra capacity just gets filled with old, repetitive chunks that have to be processed every time, muddying up the output. This isn’t just an issue with code; it happens with any kind of document editing where you’re going back and forth, trying to refine the result.
Sometimes I feel the way to "resolve" this is to instead go back and edit some earlier portion of the chat to update it with the "new requirements" that I didn't even know I had until I walked down some rabbit hole. What I end up with is almost like a threaded conversation with the LLM. Like, I sometimes wish these LLM chatbots explicitly treated the conversion as if it were threaded. They do support basically my use case by letting you toggle between different edits to your prompts, but it is pretty limited and you cannot go back and edit things if you do some operations (eg: attach a file).
Speaking of context, it's also hard to know what things like ChatGPT add to it's context in the first place. Many of times I'll attach a file or something and discover it didn't "read" the file into it's context. Or I'll watch it fire up a python program it writes that does nothing but echo the file into it's context.
I think there is still a lot of untapped potential in strategically manipulating what gets placed into the context window at all. For example only present the LLM with the latest and greatest of a document and not all the previous revisions in the thread.
If there is one domain where we're seeing tangible progress from AI, it's in working towards this goal. Difficult projects aren't in scope. But most tech, especially most tech branded IT, is not difficult. Everyone doesn't need an inventory or customer-complaint system designed from scratch. Current AI is good at cutting through that cruft.
I wonder what this would mean for companies raising today on the premise of building on top of these platforms. Maybe the best ones get their ideas copied, reimplemented, and sold for cheaper?
We already kind of see this today with OpenAI's canvas and Claude artifacts. Perhaps they'll even start moving into Palantir's space and start having direct customer implementation teams.
It is becoming increasing obvious that LLM's are quickly becoming commoditized. Everyone is starting to approach the same limits in intelligence, and are finding it hard to carve out margin from competitors.
Most recently exhibited by the backlash at claude raising prices because their product is better. In any normal market, this would be totally expected, but people seemed shocked that anyone would charge more than the raw cost it would take to run the LLM itself.
Are they good enough to replace a human yet? Questionable[0], but they are improving.
[0] You wouldn't believe how low the outsourcing contractors' quality can go. Easily surpassed by current AI systems :) That's a very low bar tho.
The problem is that 99% of theories are hard to scale.
I am not an expert, as I work adjacent to this field, but I see the inverse - dumbing down theory to increase parallelism/scalability.
This might be acceptable for amusing us with fiction and art, and for filling the internet with even more spam and propaganda, but would you trust them to write reliable code, drive your car or control any critical machinery?
The truly exciting things are still out of reach, yet we just might be at the Peak of Inflated Expectations to see it now.
However interpolation isn't reasoning. If we want to understand the motion of planets, we would start with a dataset of (x, y, z, t) coordinates and try to derive the law of motion. Imagine if someone simply interpolated the dataset and presented the law of gravity as an array of million coefficients (aka weights)? Our minds have to work with a very small operating memory that can hardly fit 10 coefficients. This constraint forces us to develop intelligence that compacts the entire dataset into one small differential equation. Btw, English grammar is the differential equation of English in a lot of ways: it tells what the local rules are of valid trajectories of words that we call sentences.
2. I'm not commenting on the quality, because they were writing about something that doesn't exist and therefore that's clearly just a given for the discussion. The only thing I was adding is that humans also need guidance, and quite a lot of it — even just a two-week sprint's worth of 15 minute daily stand-up meetings is 18,000 words, which is well beyond the point where I'd have given up prompting an LLM and done the thing myself.
... that being said I'm sure there is plenty of additional "real data" that hasn't been fed to these models yet. For one thing, I think ChatGPT sucks so bad at terraform because almost all the "real code" to train on is locked behind private repositories. There isn't much publicly available real-world terraform projects to train on. Same with a lot of other similar languages and tools -- a lot of that knowledge is locked away as trade secrets and hidden in private document stores.
(that being said Sonnet 3.5 is much, much, much better at terraform than chatgpt. It's much better at coding in general but it's night and day for terraform)
Name your platform. Linux. C++. The Internet. The x86 processor architecture. We haven't exhausted the options for delivering value on top of those, but that doesn't mean the developers and sellers of those platforms don't try to improve them anyway and might struggle to extract value from application developers who use them.
this gets to the heart of it for me. I think LLMs are an incredible tool, providing advanced augmentation on our already developed search capabilities. What advanced user doesnt want to have a colleague they can talk about their specific domain capacity with?
The problem comes from the hyperscaling ambitions of the players who were the first in this space. They quickly hyped up the technology beyond want it should have been.
It’s not true that any element, when duplicated and linked together will exhibit anything emergent. Neural networks (in a certain sense, though not their usual implementation) are already built out of individual units linked together, so simply having more of these groups of units might not add anything important.
> research is already showing promising results of the performance of agent systems.
…in which case, please show us! I’d be interested.
What's amazing to me to is that no one is throwing accusations of plagiarism.
I still think that if the "wrong people" had tried doing this they would have been obliterated by the courts.
- every time a different result is produced.
- no reasoning capabilities were categorically determined.
So this is it. If you want LLM - brace for different results and if this is okay for your application (say it’s about speech or non-critical commands) then off you are.
Otherwise simply forget this approach, and particularly when you need reproducible discreet results.
I don’t think it gets any better than that and nothing so far implicated it will (with this particular approach to AGI or whatever the wet dream is)
So it's interesting that when AI came along, we threw caution to the wind and started treating it like a silver bullet... Without asking the question of whether it was applicable to this goal or that goal...
I don't think anyone could have anticipated that we could have an AI which could produce perfect sentences, faster than a human, better than a human but which could not reason. It appears to reason very well, better than most people, yet it doesn't actually reason. You only notice this once you ask it to accomplish a task. After a while, you can feel how it lacks willpower. It puts into perspective the importance of willpower when it comes to getting things done.
In any case, LLMs bring us closer to understanding some big philosophical questions surrounding intelligence and consciousness.
The sort of generalization these things can do seems to mostly be the trivial sort: substitution.
Which Apple engineers? Yours is the only reference to the company in this comment section or in the article.
I'm wondering wether it would count, if one would extend it with an external program, that gives it feedback during inference (by another prompt) about the correctness of it's output.
I guess it wouldn't, because these RAG tools kind of do that and i heard no one calling those self aware.
On the other hand, a lot of these frameworks and languages have relatively decent and detailed documentation.
Perhaps this is a naive question, but why can't I as a user just purchase "AI software" that comes with a large pre-trained model to which I can say, on my own machine, "go read this documentation and help me write this app in this next version of Leptos", and it would augment its existing model with this new "knowledge".
What they fail at is code with high cyclomatic complexity. Back in the llama 2 finetune days I wrote a script that would break down what each node in the control flow graph into its own prompt using literate programming and the results were amazing for the time. Using the same prompts I'd get correct code in every language I tried.
Blind scaling sure (for whatever reason)* but this is the same Sutskever who believes in ASI within a decade off the back of what we have today.
* Not like anyone is telling us any details. After all, Open AI and Microsoft are still trying to create a 100B data center.
In my opinion, there's a difference between scaling not working and scaling becoming increasingly infeasible. GPT-4 is something like x100 the compute of 3 (Same with 2>3).
All the drips we've had of 5 point to ~x10 of 4. Not small but very modest in comparison.
>FWIW, GPT-2 and GPT-3 were about a year apart (2019 "Language models are Unsupervised Multitask Learners" to 2020 "Language Models are Few-Shot Learners").
Ah sorry I meant 3 and 4.
>Dario Amodei recently said that with current gen models pre-training itself only takes a few months (then followed by post-training, etc). These are not year+ training runs.
You don't have to be training models the entire time. GPT-4 was done training in August 2022 according to Open AI and wouldn't be released for another 8 months. Why? Who knows.
So if you present a novel problem it would need to be extremely simple, not something that you couldn't solve when drunk and half awake. Completely novel, but extremely simple. I think that's testable.
Yes we do. We know how neurons communicate, we know how they are formed, we have great evidence and clues as to how this evolved and how our various neurological symptoms are able to interact with the world. Is it a fully solved problem? no.
> unless you literally mean just the biological process and not how it actual impacts learning/intelligence.
Of course we have some understanding of this as well. There's tremendous bodies of study around this. We know which regions of the brain correlate to reasoning, fear, planning, etc. We know when these regions are damaged or removed what happens, enough to point to a region of the brain and say "HERE." That's far, far beyond what we know about the innards of LLM's.
> here's no evidence that we (brains) have achieved AGI, unless you tautologically define AGI as our brains.
This is extremely circular because the current definition(s) of AGI always define it in terms of human intelligence. Unless you're saying that intelligence comes from somewhere other than our brains.
Anyway, the brain is not like a LLM, in function or form, so this debate is extremely silly to me.
Yes, LLMs aren't very good at reasoning and have weird failure modes. But why is this evidence that its on the wrong path, and not that it just needs more development that builds on prior successes?
Anyway the novel problems I’m talking about are extremely simple. Basically they’re variations on the “farmer, 3 animals, and a rowboat” problem. People keep finding trivial modifications to the problem that fool the LLMs but wouldn’t fool a child. Then the vendors come along and patch the model to deal with them. This is what I mean by whack-a-mole.
Searle’s Chinese Room thought experiment tells us that enough games of whack-a-mole could eventually get us to a pretty good facsimile of reasoning without ever achieving the genuine article.
Given that this is the case, why can't this be analogously true of “AI” as well? There's plenty of reason to believe that we're hitting a wall, such that, to progress further, said wall must be overcome by means of one or more breakthroughs.
Leaving aside "we're" and "we are" are the same, it is absolutely active voice
Or because the people running companies who have fooled investors into believing it will work can afford to pay said engineers life-changing amounts of money.
Yes - it'll be interesting to see if there are any signs of these plans being adjusted. Apparently Microsoft's first step is to build optical links between existing data centers to create a larger distributed cluster, which must be less of a financial commitment.
Meta seem to have an advantage here in that they have massive inference needs to run their own business, so they are perhaps making less of a bet by building out data centers.
Like, every time an LLM gets something right we assume they've seen it somewhere in the training data, and every time they fail we presume they haven't. But that may not always be the case, it's just extremely hard to prove it one way or the other unless you search the entire dataset. Ironically the larger the dataset, the more likely the model is generalizing while also making it harder to prove if it's really so.
To give a human example, in a school setting you have teachers tasked with figuring out that exact thing for students. Sometimes people will read the question wrong with full understanding and fail, while other times they won't know anything and make it through with a lucky guess. If LLMs (and their vendors) have learned anything it's that confidently bullshitting gets you very far which makes it even harder to tell in cases where they aren't. Somehow it's also become ubiquitous to tune models to never even say "I don't know" because it boosts benchmark scores slightly.
Then on learning how it works, you might realize flapping just isn’t something they’re built to do, and it wouldn’t make much sense if they did flap their wings, given how they work instead.
And yet—damn, they fly fast! That’s impressive, and without a single flap! Amazing. Useful!
At no point did their behavior change, but your ability to understand how and why they do what they do, and why they fail the ways they fail instead of the ways birds fail, got better. No more surprises from expecting them to be more bird-like than they are supposed to, or able to be!
And now you can better handle that guy over there talking about how powerful and scary these “metal eagles” (his words) are, how he’s working so hard to make sure they don’t eat us with their beaks (… beaks? Where?), they’re so powerful, imagine these huge metal raptors ruling the sky, roaming and eating people as they please, while also… trying to sell you airplanes? Actively seeking further investment in making them more capable? Huh. One begins to suspect the framing of these things as scary birds that (spooky voice) EVEN THEIR CREATORS FEAR FOR THEIR BIRD-LIKE QUALITIES (/spooky voice) was part of a marketing gimmick.
I mostly use AIs in writing as a glorified grammar checker that sometimes suggests alternate phrasing. I do the initial writing and send it to an AI for review. If I like the suggestions I may incorporate some. Others I ignore.
The only times I use it to write is when I have something like a status report and I’m having a hard time phrasing things. Then I may write a series of bullet points and send that through an AI to flesh it out. Again, that is just the first stage and I take that and do editing to get what I want.
It’s just a tool, not a creator.
Um.
All the parent post said was:
> then try to find similar code on the web, you usually will.
Not identical code. Similar code.
I think you're really stretching the domain of plausibility to suggest that any code you write is novel enough that you can't find 'similar' code on the internet.
To suggest that code generated from a corpus that is not going to be 'similar' to the code from the corpus is just factually and unambiguously false.
Of course, it depends on what you interpret 'similar' to mean; but I think it's not unfair to say a lot of code is composed of smaller parts of code that is extremely similar to other examples of code on the internet.
Obviously you're not going to find an example similar to your entire code base; but if you're using, for example, copilot where you generate many small snippets of code... welll....
Interesting essay enumerating reasons you may be correct: https://medium.com/@francois.chollet/the-impossibility-of-in...
By that logic what you wrote was also composed that way. After all, you’ve used all words that have been used before! I bet even phrases like “that is extremely similar” and “generated from a corpus” and “unambiguously false”.
Again, I really find it hard to believe that anyone could make an argument like the one you’re making who has actually used these tools in their work for hundreds of hours, vs. for a couple minutes here or there with made up problems.
FYI, I find this line of reasoning to be unconvincing both logically and by counter-example ("why are so many experts so worried about the Y2K bug?")
Personally, I don't find AI foom or AI doom predictions to be probable but I do think there are more convincing arguments for your position than you're making here.
If it were one of many, I think you would name something better.
More realistically it’s like a really great sidekick for doing very specific mundane but otherwise non deterministic tasks.
I think we’ll start to see AI permeate into nearly every back office job out there, but as a series of tools that help the human work faster. Not as one big brain that replaces the human.
I feel like this is unfair. That's the only thing it got wrong? But we want it to pass all of our evals, even ones the perhaps a dictionary would be better at solving? Or even an LLM augmented with a dictionary.
That's an interesting angle. Though of course we're not surprised by human behavior because that's where our expectations of understanding come from. If we were used to dealing with perfectly-correctly-understanding super-intelligences, then normal humans would look like we don't understand much and our deliberate thinking might be no more accurate than the super-intelligence's absent-minded automatic responses. Thus we would conclude that humans are never really thinking or understanding anything.
I agree that default LLM output makes them look like they're thinking like a human more than they really are. I think mistakes are shocking more because our expectation of someone who talks confidently is that they're not constantly revealing themselves to be an obvious liar. But if you take away the social cues and just look at the factual claims they provide, they're not obviously not-understanding vs humans are-understanding.
Am I missing something? I thought general consensus was that Moore's Law in fact did die:
https://cap.csail.mit.edu/death-moores-law-what-it-means-and...
The fact that we've still found ways to speed up computations doesn't obviate that.
We've mostly done that by parallelizing and applying different algorithms. IIUC that's precisely why graphics cards are so good for LLM training - they have highly-parallel architectures well-suited to the problem space.
All that seems to me like an argument that LLMs will hit a point of diminishing returns, and maybe the article gives some evidence we're starting to get there.
There’s a whole classification of tasks where a human can look at a body of work and determine whether it’s correct or not in far less time than it would take for them to produce the work directly.
As a random example, having LLMs write unit tests.
But when I hear that models are failing to meet expectations, I imagine what they're saying is that the researchers had some sort of eval in mind with room to grow and a target, and that the model in question failed to hit the target they had in mind.
Honestly, problem with sentiments like these is on Twitter is that you can't tell if they're being sincere or just making a snarky, useless remark. Probably a mix of both.
I mean, it's pretty clear to me they're a potentially great human-machine interface, but trying to make LLMs - in their current fundamental form - a reliable computational tool.. well, at best it's an expensive hack, but it's just not the right tool for the job.
I expect the next leap forward will require some orthogonal discovery and lead to a different kind of tool. But perhaps we'll continue to use LLMs as we knownthem now for what they're good at - language.
For us optimistic doomers, the AI conversation seems similar to the (early-2000s) climate change debate; we see a wave of dire warnings coming from scientific experts that are all-to-often dismissed, either out of hand due to their scale, or on the word of an expert in an adjacent-ish field. Of course, there’s more dissent among AI researchers than there was among climate scientists, but I hope you see where I’m coming from nonetheless — it’s a dynamic that makes it hard to see things from the other side, so-to-speak.
At this point I’ve pretty much given up convincing people on HackerNews, it’s just cathartic to give my piece and let people take it or leave it. If anyone wants to bring the convo down from industry trends into technical details, I’d love to engage tho :)
While LLMs do plenty of awful things, people make the most incredibly stupid mistakes too, and that is what LLMs needs to be benchmarked against. The problem is that most of the people evaluating LLMs are better educated than most and often smarter than most. When you see any quantity of prompts input by a representative sample of LLM losers, you quickly lose all faith in humanity.
I'm not saying LLMs are good enough. They're not. But we will increasingly find that there are large niches where LLMs are horrible and error prone yet still outperform the people companies are prepared to pay to do the task.
In other words, on one hand you'll have domain experts becoming expert LLM-wranglers. On the other hand you'll have public-facing LLMs eating away at tasks done by low paid labour where people can work around their stupid mistakes with process or just accepting the risk, same as they currently do with undertrained labor.
LLMs are in my opinion hamstrung at the starting gate in regards to replacing software teams, as they would need to be able to understand complex business requirements perfectly, which we know they cannot. Humans can't either. It takes a business requirements/integration logic/code generation pipeline and I think the industry is focused on code generation and not that integration step.
I think there needs to be a re-imaging of how software is built by and for interaction with AI if it were to ever take over from human software teams, rather than trying to get AI to reflect what humans do.
You won't get an LLM outputting "wait, that's not right" halfway through their original output (unless you prompted them in a way that would trigger such a speech pattern), because no re-evaluation is taking place without further input.
Kant describes two human “senses”: the intensive sense of time, and the extensive sense of space. In this paradigm, spatial experience would be inextricably tied to all forms of logic, because it helps train the cognitive faculties that are intrinsically tied to all complex (discriminative?) thought.
Yes, existing LLMs are useful. Yes, there are many more things we can do with this tech.
However, existing SOTA models are large, expensive to run, still hallucinate, fail simple logic tests, fail to do things a poorly trained human can do on autopilot, etc.
The performance of LLMs is extremely variable, and it is hard to anticipate failure.
Many potential applications of this technology will not tolerate this level of uncertainty. Worse solutions with predictable and well understood shortcomings will dominate.
And there's a number of reasons why, mostly likely being that they've found other ways to get improvements out of AI models, so diminishing returns on training aren't that much of a problem. Or, maybe the leakers are lying, but I highly doubt that considering the past record of news outlets reporting on accurate leaked information.
Still though, it's interesting how basically ever frontier lab created a model that didn't live up to expectations, and every employee at these labs on Twitter has continued to vague-post and hype as if nothing ever happened.
It's honestly hard to tell whether or not they really know something we don't, or if they have an irrational exuberance for AGI bordering on cult-like, and they will never be able to mentally process, let alone admit, that something might be wrong.
To be clear, I don't think a near-term bubble collapse is likely but I'm going from 3% to maybe ~10%. Also, this doesn't mean I doubt there's real long-term value to be delivered or money to be made in AI solutions. I'm thinking specifically about those who've been speculatively funding the massive build out of data centers, energy and GPU supply expecting near-term demand to continue scaling at the recent unprecedented rates. My understanding is much of this is being funded in advance of actual end-user demand at these elevated levels and it is being funded either by VC money or debt by parties who could struggle to come up with the cash to pay for what they've ordered if either user demand or their equity value doesn't continue scaling as expected.
Admittedly this scenario assumes that these investment commitments are sufficiently speculative and over-committed to create bubble dynamics and tipping points. The hypothesis goes like this: the money sources who've over-committed to lock up scarce future supply in the expectation it will earn outsize returns have already started seeing these warning signs of efficiency and/or progress rates slowing which are now hitting mainstream media. Thus it's possible there is already a quiet collapse beginning wherein the largest AI data center GPU purchasers might start trying to postpone future delivery schedules and may soon start trying to downsize or even cancel existing commitments or try to offload some of their future capacity via sub-leasing it out before it even arrives, etc. Being a dynamic market, this could trigger a rapidly snowballing avalanche of falling prices for next-year AI compute (which is already bought and sold as a commodity like pork belly futures).
Notably, there are now rumors claiming some of the largest players don't currently have the cash to pay for what they've already committed to for future delivery. They were making calculated bets they'd be able to raise or borrow that capital before payments were due. Except if expectation begins to turn downward, fresh investors will be scarce and banks will reprice a GPU's value as loan collateral down to pennies on the dollar (shades of the 2009 financial crisis where the collateral value of residential real estate assets was marked down). As in most bubbles, cheap credit is the fuel driving growth and that credit can get more expensive very quickly - which can in turn trigger exponential contagion effects causing the bubble to pop. A very different kind of "Foom" than many AI financial speculators were betting on! :-)
So... in theory, under this scenario sometime next year NVidia/TSMC and other top-of-supply-chain companies could find themselves with excess inventories of advanced node wafers because a significant portion of their orders were from parties who no longer have access to the cheap capital to pay for them. And trying to sue so many customers for breach can take a long time and, in a large enough sector collapse, be only marginally successful in recouping much actual cash.
I'd be interested in hearing counter-arguments (or support) for the impossibility (or likelihood) of such a scenario.
The lack of progress with self driving seems to indicate that Tesla has a serious problem with scaling. The investment in enormous compute resources is another red flag (if you run out of ideas, just use brute force). This points to a fundamental flaw in model architecture.
If indeed the "GPT 5!" Arms race has calmed down, it should help everyone focus on the possible, their own goals, and thus what AI capabilities to deploy.
Just as there won't be a "Silver Bullet" next gen model, the point about Correct Data In is also crucial. Nothing is 'free' not even if you pay a vendor or integrator. You, the decision making organization, must dedicate focus to putting data into your new AI systems or not.
It will look like the dawn of original IBM, and mechanical data tabulation, in retrospect once we learn how to leverage this pattern to its full potential.
As a developer, I'm making much more progress using the SOTA (Claude 3.5) as a Socratic interrogator. I'm brainstorming a project, give it my current thoughts, and then ask it to prompt me with good follow-up questions and turn general ideas into a specific, detailed project plan, next steps, open questions, and work log template. Huge productivity boost, but definitely not replacing me as an engineer. I specifically prompt it to not give me solutions, but rather, to just ask good questions.
I've also used Claude 3.5 as (more or less) a free arbitrator. Last week, I was in a disagreement with a colleague, who was clearly being disingenuous by offering to do something she later reneged on, and evading questions about follow up. Rather than deal with organizational politics, I sent the transcript to Claude for an unbiased evaluation, and it "objectively" confirmed what had been frustrating me. I think there's a huge opportunity here to use these things to detect and call out obviously antisocial behavior in organizations (my CEO is intrigued, we'll see where it goes). Similarly, in our legal system, as an ultra-low-cost arbitrator or judge for minor disputes (that could of course be appealed to human judges). Seems like the level of reasoning in Claude 3.5 is good enough for that.
My mental model is always "low-risk search". https://muldoon.cloud/2023/10/29/ai-commandments.html
It's possible, but it's not at all obvious and requires a slightly skewed way of looking at them.
Watch this be a power move to break from Microsofts investment when ready rather than true agi. Sam is laying the foundations here.
It's not even close to fully solved. We're still figuring out basic things like the purpose of dreams. We don't understand how memories are encoded or even things like how we process basic emotions like happiness. We're way closer to understanding LLMs than we are the brain, and we don't understand LLMs all that well still either. For example, look at the Golden Gate Bridge work for LLMs -- we have no equivalent for brains today. We've done much more advanced introspection work on LLMs in this short amount of time than we've done on the human brain.
It's almost like saying "we've already visited every place on Earth, surely Mars is just around the corner now"
This smells like it’s mostly based on OAI having a bit of bad luck with next model rather than a fundamental slowdown / barrier.
They literally just made a decent sized leap with o1
At CoRL last week, the progress has noticeably plateaued. Roboticists notably were pessimistic that scaling laws will apply to robotics because of the embodiment issues.
The Information reporting was a bit more clear on this. Orion is better than GPT-4, it's just that they were expecting a leap in capabilities comparable to what we saw going from GPT-3 to GPT-4. In other words, they were expecting essentially a GPT-5, and Orion wasn't that good.
I know we absolutely have not, but I think we have reached the limit in terms of the Chatbot experience that ChatGPT is. For some reason the industry keeps trying to force the chatbot interface to do literally everything to the point that we now have inflated roles like "Prompt Engineers". This is to say that people suck at knowing what they want off the rip, and LLMs can't help with that if they're not integrated in technology in such a way where a solid foundation is built to allow the models to generate good output.
LLMs and other big data models have incredible potential for things like security, medicine, and the power industry to name a few fields. I mean I was recently talking with a professor about his research in applying deep learning to address growing security concerns in cars on the road.
The application is far from reaching the ceiling.
Learning from data is not enough; there is a need for the kind of system-two thinking we humans develop as we grow. It is difficult to see how deep learning and backpropagation alone will help us model that. For tasks where providing enough data is sufficient to cover 95% of cases, deep learning will continue to be useful in the form of 'data-driven knowledge automation.' For other cases, the road will be much more challenging. https://www.lycee.ai/blog/why-sam-altman-is-wrong
It works disturbingly well. But because it doesn’t have any actual intrinsic knowledge it has no way of knowing when it made a “good“ hallucination versus a “bad“ one.
I’m sure people are working at piling things on top to try and influence what gets generated or catch and move away from errors errors other layers spot… but how much effort and resources will be needed to make it “good enough“ that people don’t worry about this anymore.
In my mind the core problem is people are trying to use these for things they’re unsuitable for. Asking fact-based questions is asking for trouble. There isn’t much of a wrong answer if you wanted to generate a bedtime story or a bunch of test data that looks sort of like an example you give it.
If you ask it to find law cases on a specific point you’re going to raise a judge‘s ire, as many have already found.
1. Find more data.
2. Make the weights capture the data and reproduce.
In that sense we have reached a limit. So in my opinion we can do a couple of things.
1. App developers can understand the limits and build within the limits.
2. Researchers can take insights from these large models and build better AI systems with new architectures. It's ok to say transformers have reached a limit.
I see these statements often here about “I’ve never seen an effective commercial use of LLMs,” which tells me you aren’t working with very creative and competent people in areas that are amenable to LLMs. In my professional network beyond where I work now I know at least a dozen people who have successful commercial applications of LLMs. They tend to be highly capable people able to build the end to end tool chains necessary (which is a huge gap) and understand how to compose LLMs in hierarchical agents with effective guard rails. Most ineffectual users of LLMs want them to be lazy buttons that obviate the need to think. They’re not - like any sufficiently powerful tool they require thought up front and are easy to use wrong. This will get better with time as patterns and tools emerge to get the most use out of them in a commercial setting. However the ability to process natural language and use an emergent (if not actual) abductive reasoning is absurdly powerful and was not practically possible 4 years ago - the assertion such an amazing capability in an information or decisioning system is not commercially practical is on the face absurd.
LLM has its place and it will forever change how we think about UX and other things, but we need to realize you really can't create a public facing solution without significant safe guards, if you don't want egg on your face.
I am 100% not blaming the LLM, but rather VCs and the media for believing the VCs. Once we get over the hype and people realize there isn't a golden goose, the better off we will be. Once we accept that LLM is not perfect and that it is not what we are being sold, I believe we will find a place for it that will make a huge impact. Unfortunately for OpenAI and others, I don't believe they will play as big of a role as they would like us to believe/will.
Apps that use LLMs or apps made with LLMs? In either case can you share them?
>which tells me you aren’t working with very creative and competent people
> In my professional network beyond where I work now I know at least a dozen people who have successful commercial applications of LLMs.
Apps that use LLMs or apps made with LLMs? In either case can you share them?
No one doubts that you can integrate LLMs into an application workflow and get some benefits in certain cases. That has been what the excitement and promise was about all along. They have a demonstrated ability to wrangle, extract, and transform data (mostly correctly) and generate patterns from data and prompts (hit and miss, usually with a lot of human involvement). All of which can be powerful. But outside of textual or visual chatbots or CRUD apps, no one wants to "put up or shut" a solid example that the top management of an existing company would sign off on. Only stories about awesome examples they and their friends are working on ... which often turn out to be CRUD apps or textual or visual chatbots. One notable standout is generative image apps can be quite good in certain circumstances.
So, since you seem to have a real interest and actual examples of this, I am curious to see some that real companies would gamble that company on. And I don't mean some quixotic startup, I mean a company making real money now with customers that is confident on that app to the point they are willing to risk big. Because that last part is what companies do with other (non LLM) apps. I also know that people aren't perfect and wouldn't expect an LLM to be, just want to make sure I am not missing something.
The article you pointed out says the end came in 2016: Eight years ago.
My point is those types of articles have been popping up every few years since the 1990s. Sure, at some point these sort of predictions will be proven correct about LLMs as well. Probably in a few decades.
On the other hand, selling to customers who can't pay but who look solvent to public investors sounds like the kind of short-termism nobody should be too surprised to be reading a book about in a few years...
It's been a while though, we've had great models now for a 18 months plus. Why are we still yet to see these type of applications rolling out on a wide scale?
My anecdotal experience is that almost universally, 90-95% type accuracy you get from them is just not good enough. Which is to say, having something be wrong 10% or even 5% of the time is worse than not having at all. At best, you need to implement applications like that in an entirely new paradigm that is designed to extract value without bearing the costs of the risks.
It doesn't mean LLMs can't be useful, but they are kind of stuck with applications that inherently mesh with human oversight (like programming etc). And the thing about those is that they don't really scale, because the human oversight has to scale up with whatever the LLM is doing.
The lifetime is the context window, the model/training is the DNA. A human in the moment isn't general intelligent, but a human over his lifetime is, the first is so much easier to try to replicate though but that is a bad target since humans aren't born like that.
Amazon and Google didn't mess with their core business by competing with the players using it until they REALLY ran out of ways to make money.
What's true and what's not true is not related to what you personally believe.
It is factually and unambiguously false to state that generated code is, in general, not similar to other code from the corpus it is trained on.
> And none of it appears anywhere else; I've checked.
^ Even if this statement, is not false (I'm skeptical, but whatever), in general, it would be false for most users of copilot.
None of it appears anywhere else? None of it? Really?
That's not true of the no-AI code base I'm working on.
That's very difficult to believe it would be true on a code base heavily written by copilot and the like.
It's probably not true, in general, for AI generated code bases.
We can have a different conversation about verbatim copied code, where an AI model generates a large body of verbatim copy from a training source. That's very unusual.
...but to say the generated code wouldn't even be similar? Come on.
That's literally what LLMs do.
This means that on one hand firms are demanding RTO for culture and team work improvements. While on the other they will be ok with a tool that makes unpredictable errors like humans, but can never be impacted by culture and team work.
These two ideas lie in odd juxtaposition to each other.
Anything that has more memory and adequate compute will win the coming AI wars.
At the rate at which power consumption is growing now that the shortage of current gen cards has started to work itself out people are realizing they need a fleet of nuclear reactors to keep the data centers running. This is not something that's getting fix with the coming generation, if anything it's worse.
There was another one that claimed to get rid of hallucinations. They also said it takes 50-100 epochs for regular architectures to actually memorize something. Their paper is below in case people qualified to review it want to.
https://arxiv.org/abs/2406.17642
Like the brain, I believe the problem will be solved by a mix of specialized components working together. One of those components will be a memory (or series of them) that the others reference to keep processing grounded in reality.
I have had good luck using an LLM as a "sanity checking" layer for transcription output, though. A simple prompt like "is this paragraph coherent" has proven to be a pretty decent way to check the accuracy of whisper transcriptions.
I tried building a whole codebase inspector, essentially what you are referring to with Gemini's 2 million token context window but had troubles with their API when the payload got large. Just 500 error with no additional info so...
https://app.gitsense.com/?doc=905f4a9af74c25f&model=Claude+3...
Claude 3.5 Sonnet will now misinterpret "GitHub as "Github"
https://chrisfrewin.medium.com/why-llms-will-never-be-agi-70...
Still have like 2-3 big posts to publish.
Long story short its easy to get enamored with an agent spitting out tokens out but reality and engineering are far far more complex than that (orders of magnitude)
> You can have it craft an email, or to review your email, but I wouldn't trust an LLM with anything mission-critical
My point is that an entire world lies between these two extremes.
For example recently I asked it to generate some phrases for a list of words, along with synonym and antonym lists.
The phrases were generally correct and appropriate (some mistakes but that’s fine). The synonyms/antonyms were misaligned to the list (so strictly speaking all wrong) and were often incorrect anyway. I imagine it would be the same if you asked for definitions of a list of words.
If you ask it to correct it just generates something else which is often also wrong. It’s certainly superficially convincing in many domains but once you try to get it to do real work it’s wrong in subtle ways.
This ofc implies local models and that you have a decent cpu + min 64gb of ram to run above 7b-sized model.
https://github.com/oobabooga/text-generation-webui
https://huggingface.co/models?pipeline_tag=text-generation&s...
And while Qwen2.5-Coder-32B-Instruct is a pretty advanced finetune — it was trained on an extra 5 trillion tokens — even smaller finetunes have done really well. For example, Dracarys-72B, which was a simpler finetune of Qwen2.5-72B using a modified version of DPO on a handmade set of answers to GSM8K, ARC, and HellaSwag, significantly outperforms the base Qwen2.5-72B model on the aider coding benchmarks.
There's a lot of intelligence we're leaving on the floor, because everyone is just prompting generic chat-tuned models! If you tune it to do something else, it'll be really good at the something else.
I.e. can it ruminate on the data it's ingested, and rather than returning the response of highest probability, return something original?
I think that's the key. If LLMs can't ultimately do that, there's still a lot to be gained from utilising the speed and fluidly scalable resources of computers.
But like all the top tech companies know, it's not quantity of bodies in seats that matters but talent, the thing that's going to prevail is raw intelligence. If it can't think better than us, just process data faster and more voluminously but still needing human verification, we're on an asymptotic path.
I believe the above suggested that this type of email likely doesn't need to be sent. Is anyone really reading the status report? If they read it, what concrete decisions do they make based on it. We all get in this trap of doing what people ask of us but it often isn't what shareholders and customers really care about.
AI will always have a specific narrow focus and will never ever be creative, the best AI proponents can hope for is that the hallucinations will drop to a more unnoticable level.
In education at least, we've actively improved efficiency by ~25% across a large swath of educators (direct time saved) - agentic evaluators, tutors and doubt clarifiers. The wins in this industry are clear. And this is that much more time to spend with students.
I also know from 1-1 conversation with my peers in large-finance world, and there too the efficiency improvements on multiple fronts are similar.
It will be like StableDiffusion 1.5. This model can now run on low end devices, lots of open research use this model to build something else and inspire by this.
These LLMs can be used as a foundation to keep improving and building new things.
Of course Waymo needs money but if the car made fewer trips compared to Uber/Taxi, it is not suffering the same consequences.
We need to consider human factor and the severe lacking of that in these robot/self driving/LLM and drawing parallels is not a direction I am feeling comfortable.
End of the day, Tesla also sold half baked self drive that killed people, we should not forget.
What they are measuring, it seems, is whether LLMs can be built which will retrieve a reliable known correct answer on request. That's an information retrieval problem, and, in fact, they solve it by adding "Memory Experts" which are basically data storage.
It's not clear that this helps either replies which require synthesizing disparate information, or detecting that the training data does not contain info needed to construct a reply.
I've seen a deer on a road maybe once. I've seen a rabbit on a road zero times. But I know what to do if I see one.
Is that because the "video" of my perception has many "frames"? Even if that's true at some level, I think it's massively missing the point. Yeah, so I saw that one deer from a lot of angles. But current AI training is like the equivalent of taking every deer that has ever been on camera in the history of the human species.
Somehow I'm still dramatically better at generalization than the AI. Surely that's an algorithm difference.
[0] https://transformer-circuits.pub/2024/scaling-monosemanticit...
everyone is looking at llm scores & strawberry gotchas while ignoring the trillions of market potential in replacing existing systems and (yes) people with the current capabilities. identifying the use cases, finetuning the models and (most importantly) actually rolling this out in existing organizations/processes/systems will be the challenge long before the base models' capabilities will be
it is worth working on those issues now and get the ball rolling, switching out your models for future more capable ones will be the easy part later on.
Then you can go ultra-wide in terms of cores, dispatchers and vectors (essentially building bigger and bigger chips), but an algorithm which can't exploit that will be little faster on today's chips than on a 4790K from ten years ago.
This methodological growth could make LLMs more reliable, consistent, and aligned with specific use cases.
The skepticism surrounding this vision mirrors early doubts about the early internet fairly concisely.
Initially, the internet was seen as fragmented collection of isolated systems without a clear structure or purpose. It really was. You would gopher somewhere and get a file, and eventually we had apps like like pine for email, but as cool as it was it has limited utility.
People doubted it could ever become the seamless, interconnected web we know today.
Yet, through protocols, shared standards, and robust frameworks, the internet evolved into a powerful network capable of handling diverse applications, data flows, and user needs.
In the same way, LLM orchestration will mature by standardizing interfaces, improving interoperability, and fostering cooperation among varied AI models and support systems.
Just as the internet needed HTTP, TCP/IP, and other protocols to unify disparate networks, orchestrated AI systems will require foundational frameworks and “rules of the road” that bring cohesion to diverse technologies.
We are at the veeeeery infancy of this era and have a LONG way to go here. Some of the progress looks clear and a linear progression, but a lot, like the Internet, will just take a while to mature and we shouldn’t forget what we learned the last time we faced a sea change technological revolution.
Here are the docs for an example of how it can look: https://news.ycombinator.com/item?id=42039895
But we have seen from AlphaGo that when training data is extensive, it can rediscover strategy on its own and even surpass us. It's not inherently worse than human learning.
That's literally Zucc's entire play, in 5 years this stuff is going to be so abundant you'll get access to good enough models for pennies and he'll win because he can slap ads on it, and openAI sits there on its gargantuan research costs.
If you have an external program, then by defining it's not self-awareness ;). Also, it's not about correctness per se, but about the model's ability to assess its own knowledge (making a mistake because the model was exposed to mistakes in the training data is fine, hallucinating isn't).
- Vast cost reduction (>10x)
- Performance parity of several open source models to GPT4, including some with far fewer parameters
- Much better performance, much larger context window in state-of-the-art closed source LLMs (Claude 3.5 Sonnet)
- Multimodality (audio and vision)
- Prototypes for semi-autonomous agents and chain-of-thought architectures showing promising avenues for progress
There, you don't need to invoke Turing or compiler bootstrapping. You just need one example of a use case where the accuracy of responses is mission critical
https://www.cnbc.com/2024/10/30/microsoft-cfo-says-openai-in...
If we're back to curating it by hand and imparting it by writing code manually, how exactly are these systems an improvement on the 80's idea of building expert systems?
I think that, too, is a UX problem.
If you present the output as you do, as simple text on a screen, the average user will read it with the voice of an infallible Star Trek computer and be irritated by every mistake.
But if you present the same thing as a bunch of cartoon characters talking to each other, users might not only be fine with "egg in your face moments", as you put it, they will laugh about them.
The key is to move the user away from the idealistic mental model of what a computer is and does.
Now, neural nets that have a copy of themselves, can look back at what nodes were hit, and change through time... then maybe we are getting somewhere
But the knowledge system here is doing the grunt of the work, and progressing past it's own limitations goes right hack to the pitfalls of the rules based AI winter. That's not a engineering problem, it's a foundational mathematics problems that only a few people are seriously working on.
ChatGPT and Claude seem to be pretty good at maintaining an implicit understanding of the codebase based on a subset of files.
LLM investors will be reviewing their portfolios and will likely begin declining further investments without clear evidence of profits in the very near future. On the other side, LLM companies will likely try to downplay this and again promise the Moon.
And on and on the market goes
I don't know much about LLMs, but that seems to indicate a sort of dead-end. The models are still useful, but limited in their abilities. So now the developers and researchers needs to start looking for new ways to use all this data. That in some sense resets the game. Sucks to be OpenAI, billions of dollars spend on a product that has been match or even outmatched by the competition in a few short years, not nearly enough time to make any of it back.
If there is a take away, it might be that it takes billions, if not trillions of dollars, to develop an AI and the result may still be less than what you hope for, and the investment really hard to recoup.
I don't think anyone doubted the nature of the technology. The bits were being sent. It's not like we were unsure of the fundamental possibility of transmitting information. The potential was shown very, very early on (Mother of all demos was in 1968). What we were and to some extent still are unsure of is the practical impact on society.
AI and LLMs in particular are not even at the mother of all demos level yet notwithstanding the grandiose claims and demos. There is no consensus on what these models are even doing. There is (IMO) justified skepticism surrounding the claims of reasoning and ability to abstract. We are in my opinion not yet at the "bits are being sent" stage.
Look behind the veil and see LLMs for what they really are and you will maximise their utility, temper your expectations and save you disappointment
I'm surprised to hear someone say that O1 and new Sonnet are "leaps", though. My impression of them is that they're qualitatively similar to GPT-4. Incremental improvements at best. I don't think the gap between GPT-4 and the new Sonnet is anywhere near as large as the gap between GPT-3 and GPT-4, for instance.
For coding LLMs certainly are helpful, but I prefer local models instead of anything on offer right now. There is just much more potential here.
Among other things: it writes new, useful code daily in our local DSL, which appears nowhere on the internet and in fact didn't exist a few months ago.
My masters was text-to-sql and I can tell you hundreds of papers conclude that seq2seq and the transformer dérivâtes suck at logic even when you approach logic the symbolic way.
We’d love to figure production rules of any sort emerge with scale of the transformer, but I’m get to read such paper.
https://chatgpt.com/share/67373737-04a8-800d-bc57-de74a415e2...
I think the parent comment's challenge is more appropriate.
From there, you need multiple layers building on info it contains to synthesize a reply that might be good. Alternatively, an iterative process going a few rounds through a model, re-presenting the combo of results together, and it fuses them. All based on known data or what’s in the prompt with nothing else.
This is speculative based on a few things our own minds do.
This more marginal labor is going to be more easy to replace. Also plenty of the more "elite" type labor will too, as it turns out it is more marginal. Already glue and boilerplate programming work is going this way, there is just so much more to do, and the important work of figuring out what should be done, that it hasn't displaced programmers yet. But it will for some fraction. WYSIWG type websites for small business has come a long way and will only get better, so there will be less need for customization on the margin. Or light design work (like take my logo and plug into into this format for this charity tournament flyer).
And with that there is a body work on "groundedness" that basically post-processes output to compare it against its source material. It still can result in logic errors and has a base error it self, but can ensure you at least have clear citations for factual claims that match real documents, but doesn't fully ensure they are being referenced correctly (though that is already the case even with real papers produced by humans).
Also consider the baseline isn't perfection, it is a benchmark against real humans. Accuracy is getting much better in certain domains where we have a good corpora. Part of assessing the accuracy of a system is going to be about determining if the generated content is "in distribution" of its training data. There is progress being made in this direction, so we could perhaps do a better job at the application level of making use of a "confidence" score of some kind maybe even taking that into account in a chain of thought like reasoning step.
People keep finding "obviously wrong" hallucinates that seem like proof things are still crap. But these system keep getting better on benchmarks looking at retrieval accuracy. And the benchmarks keep getting better as people point out deficiencies it them. Perfection might not be possible, but consistently better than average human seems in reach, and better than that seems feasible too. The challenge is the class of mistakes might look different even if the error rate overall is lower.
Which pre-human animals evolved instincts for swerving a car to avoid a deer?
Oh, you just asked it to make a trivia app that feeds on JSON. Cute, but that's not what I meant. The web is full of tutorials for basic stuff like that.
To be clear I meant that LLMs can't write trivia questions and answers, thus proving that they can't produce trustworthy outputs.
And a trivia app is a toy (one might even say... a trivial example), but it's a useful demonstration of why you wouldn't put an LLM into a system on which lives depend on, let alone invest billions on it.
If you don't trust my words just go back to fiddling with your models and ask them to write a trivia quiz about a topic that you know very well. Like a TV show.
If you look at the Wikipedia article 'History of artificial intelligence' for now it has 'AI boom' and '2004 Nobel Prizes' but everything earlier is kind of meh.
I remember sitting down with pen and paper to try to write a ChatGPT type chatbot 44 years ago and of course totally failing to get anywhere, but I've followed the goings on since and this is the first time this stuff is working well.
Not quite that wording. More we know which way to head. I think he's sincere.
Your point about skepticism being warranted when viewing this linearly is well taken. But this isn’t a linear path. The Internet, at its core, was about connecting computers to unlock the value of those connections—a transformative but relatively straightforward concept.
What we’re dealing with now is the training of cognitive digital intelligence. This is an inherently dynamic and breakthrough-oriented process, one that evolves in ways far less predictable or constrained than simple network effects. While the metaphor of connectivity is useful, it doesn’t fully capture the parallel, multi-dimensional approaches at play here.
Pessimism, in my view, is deeply unwarranted, especially given the history of technological progress. Time and again, advancements have proven to be far more impactful and beneficial than even the most optimistic predictions. Consider the projections for AI in 2017—most futurists undershot its actual progress by an order of magnitude.
This research clearly illuminates a path forward:
https://ekinakyurek.github.io/papers/ttt.pdf
Deeply appreciate your thoughtful comment.
Their models have tons of use cases, but OpenAI and Anthropic are now in a product/commercial play.
Well, I can see the direction you are going. I am unconvinced though - it hasn't thread the needle.
Reason being
1) They are doing both in cube farms in the PHP, RTO + replacement by GenAI.
2) In high tech, they are also trying achieve these contradictory goals. RTO + Increased GenAI capability to reduce manpower needs.
I can see a desire to reduce costs. I cant see how RTO to improve team work sits with using LLMs to do human work.
If AGI doesn't take the form of human-ish intelligence, then we'd never know it was intelligence. This means that the target is always a "visible" human like intelligence and that was gained through evolution and millions of years of experimentation and records. It will most certainly not take that long for human-like intelligence to form given our current progress but we would not recognise anything else.
Rumours have been in abundance since GPT-4 came out due to on the lack of clarity, but that lack of clarity seems to also exist within the companies themselves.
OpenAI and Anthropic certainly seem up be doing a lot of product stuff, but at the same time the only reason people have for saying OpenAI not making a profit is all the money they're also spending on training new models — I've yet to use o1, it's still in beta and is only 2 months old (how long was gmail in "beta", 5 years?)
I also don't know how much self-training they do, training on signals from the model's output and how users rate that output, only that (1) it's more then none, that (2) some models like Phi-3 use at least some synthetic data[0], and (3) that making a model to predict how users will rate the output was one of the previous big breakthroughs.
If they were to train on almost all their own output, and estimaing API costs as approximately actual costs, and given the claimed[1] public financial statements, that's in the order of a quadrillion (1e15) tokens, compared to the mere ~1e13 claimed for some of the larger models.
[0] https://arxiv.org/abs/2404.14219
[1] I've not found the official sources nor do I know where to look for them, all I see are news websites reporting on the numbers without giving citations I can chase up
clippy.gif
People use the term in different ways. It generally implies being able to think like a human or better. OpenAI have always said they are working towards it, I think deepmind too. It'll probably take more than an LLM.
It's economically a big deal because if it can out think humans you can set it to develop the next improved model and basically make humans redundant.
There are definitely teams working on applying reinforcement learning to LLMs. Maybe that will unlock new potential from finite training data.
And yes of course hallucinations are a huge problem for most of these use cases, but they aren't stopping people from using them anyway. We have a new misinformation problem and it has no agenda. It's basically just white noise.
So my money is also on this changing the world dramatically, just not in the in uniformly positive way that the hype said it will.
"""
Intuitively, an overparameterized model will generalize well if the model’s representations capture the essential information necessary for the best model in the model class to perform well
"""
https://iclr-blogposts.github.io/2024/blog/double-descent-de...
No, that's one contiguous response from the LLM. I have screenshots, because I was so surprised the first time. I've had it happen many times. This was (as I always use LLM) direct API calls. In the first case it happened, it was with largest Llama 3.5. It usually only happens one shot, no context, base/empty system prompt.
> LLMs don't exhibit such an inner feedback loop
That's not true, at all. Next token prediction is based on all previous text, including the previous word that was just produced. It uses what it has said for what it will say next, within the same response, just as a markov chain would.
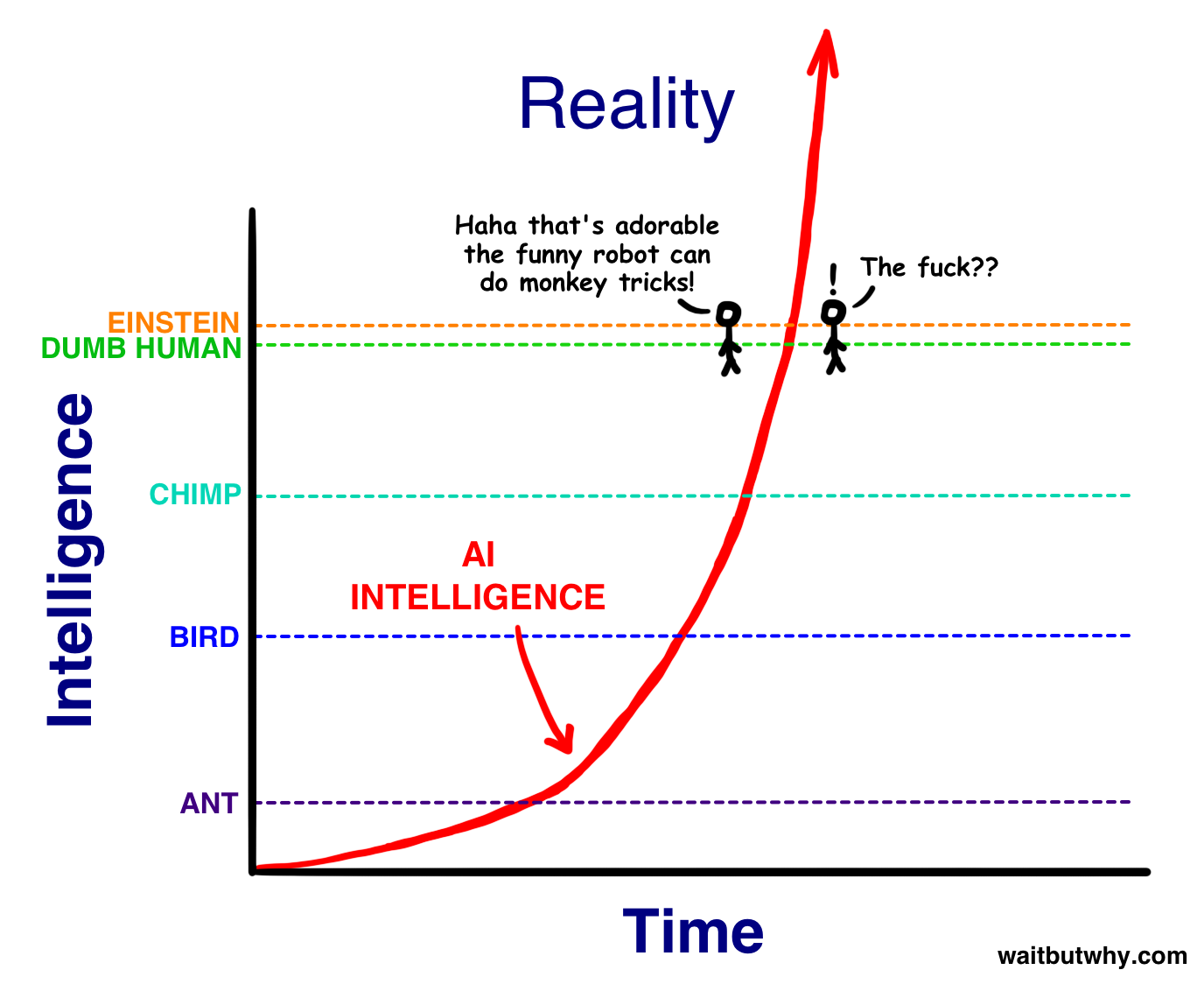{kind=link}