Heya, Disco is the open source PaaS I've been working on with my friend Antoine Leclair.
Lots of conversation & discussion about self-hosting / cloud exits these days (pros, cons, etc.) Happy to engage :-)
Cheers!
replies(5):
Lots of conversation & discussion about self-hosting / cloud exits these days (pros, cons, etc.) Happy to engage :-)
Cheers!
Hosting staging envs in pricey cloud envs seems crazy to me but I understand why you would want to because modern clouds can have a lot of moving parts.
We used to be on Heroku and the cost wasn't just the high monthly bill - it was asking "is this little utility app I just wrote really worth paying $15/month to host?" before working on it.
This year we moved to a self-hosted setup on Coolify and have about 300 services running on a single server for $300/month on Hetzner. For the most part, it's been great and let us ship a lot more code!
My biggest realization is that for an organization like us, we really only need 99% uptime on most of our services (not 99.99%). Most developer tools are around helping you reach 99.99% uptime. When you realize you only need 99%, the world opens up.
Disco looks really cool and I'm excited to check it out!
This seems like a good idea to have plentiful dev environments and avoid a bad pricing model. If your production instance is still on Heroku, you might still want a staging environment on Heroku since a Hetzner server and your production instance might have subtle differences.
The load average in htop is actually per CPU core. So if you have 8 CPU cores like in your screenshot, a load average of 0.1 is actually 1.25% (10% / 8) of total CPU capacity - even better :).
Cool blog! I've been having so much success with this type of pattern!
I'd still like a staging + prod, but keeping the dev environments on a separate beefy server seems smart.
If you can fit them all on a 4 cpu / 32gb machine, you can easily forgo them and run the stack locally on a dev machine. IME staging environments are generally snowflakes that are hard to stand up (no automation).
$500/month each is a gross overpayment.
You get X resources in the cloud and know that a certain request/load profile will run against it. You have to configure things to handle that load, and are scored against other people.
Especially when I got look at the site in question (idealist.org) and it seems to be a pretty boring job board product.
* The big caveat: If you don't incur the exact same devops costs that would have happened with a linux instance.
Many tools (containers in particular) have cropped up that have made things like quick, redundant deployment pretty straightforward and cheap.
I'd say the main differences is that we 1) we offer a more streamlined CLI and UI rather than offering extensive app/installation options 2) have an api-key based system that lets team members collaborate without having to manage ssh access/keys.
Generally speaking, I'd say our approach and tooling/UX tends to be more functional/pragmatic (like Heroku) than one with every possible option.
Not free, it became a productivity boost.
You now have a $35k annual budget for the maintenance, other overhead, and lost productivity. What do you spend it on?
> The team also took on responsibility for server monitoring, security updates, and handling any infrastructure issues themselves
For a place that’s paying devs $150k a year that might math out. It absolutely does not for places paying devs $250k+ a year.
One of the great frustrations of my mid career is how often people tried to bargain for more speed by throwing developers at my already late project when what would have actually helped almost immediately was more hardware and tooling. But that didn’t build my boss’ or his bosses’ empires. Don’t give me a $150k employee to train, give me $30k in servers.
Absolutely no surprise at all when devs were complicit with Cloud migrations because now you could ask forgiveness instead of permission for more hardware.
Just something to consider if you are in a professional environment before switching your entire infra: maintenance cost is expensive. I strongly suggest to throw man-days in your cost calculation.
To prevent security vulnerabilities, the team will need to write some playbooks to auto-update regularly your machine, hoping for no breaking changes. Or instead write a pipeline for immutable OS images updates. And it often mean testing on an additional canary VM first.
Scaling up the VM from a compute point of view is not that straightforward as well, and will require depending of the provider either downtime or to migrate the entire deployments to a new instance.
Scaling from a disk size point of view, you will need to play with filesystems.
And depending on the setup you are using, you might have to manage lets encrypt, authentication and authorization, secrets vaults, etc (here at least Disco manages the SSL certs for you)
Cloud isn't worth it until suddenly it is because you can't deploy your own servers fast enough, and then it's worth it until it exceeds the price of a solid infrastructure team and hardware. There's a curve to how much you're saving by throwing everything in the cloud.
For example, the "Bridging the Gap: Why Not Just Docker Compose?" section is a 1:1 copy of the points in the "Powerful simplicity" on the landing page - https://disco.cloud/
And this blog post is the (only) case study that they showcase on their main page.
You can also enable zram to compress ram, so you can over-provision like the pros'. A lot of long-running software leaks memory that compresses pretty well.
Here is how I do it on my Hetzner bare-metal servers using Ansible: https://gist.github.com/fungiboletus/794a265cc186e79cd5eb2fe... It also works on VMs.
It offloads things like - Power Usage - Colo Costs - Networking (a big one) - Storage (SSD wear / HDD pools) - etc
It is a long list but what doesnt allow you do it make trade offs like spending way less but accept downtime if your switch dies etc etc.
For a staging env these are things you might want to do.
As for the staging servers, for each deployment, it was a mix of Performance-M dynos, multiple Standard dynos, RabbitMQ, a database large enough, etc. - it adds up quickly.
Finally, Idealist serves ~100k users per day - behind the product is a lot of boring tech that makes it reliable & fast. :-)
It's fun the first time, but becomes an annoying faff when it has to be repeated constantly.
In Heroku, Vercel and similar you git push and you're running. On a linux server you set up the OS, the server authentication, the application itself, the systemctl jobs, the reverse proxy, the code deployment, the ssl key management, the monitoring etc etc.
I still do prefer a linux server due to the flexibility, but the UX could be a lot better.
If you are small enough, you are not going to be truly affected by downtime. If you are just a little bigger, a single hot spare is going to be sufficient.
The place where you get dinged is heavy growth in personnel and bandwidth. You end up needing to solve CPU bound activities quicker because it hurts the whole system. You need to start thinking about sticky round robin load balancing and other fun pieces.
This is where the cloud can allow you to trade money for velocity. Eventually, though, you will need to pay up.
That said, the average SaaS can go a long way with a single server per product.
Which means, that if they want to test what it will look like running in cloud for prod, they are going to either need a pre-prod environment or go yolo
What's in it for Disco ?
What's the pricing ?
How many work hours per month does keeping this thing stable take.
If it takes over 15 Heroku is cheaper.
Hosting with bare metal is still expensive, you pay in other ways.
- ...
I'm kidding :-)
Our library is open source, and we're very happy and proud that Idealist is using us to save a bit of cash. Is it marketing if you're proud of your work? :-) Cheers
The key element here is the need to continuously exercise both processes (Heroku + your staging server), to work out both processes & maintain familiarity on both.
Depending on the amount of staff involved in the above, it might eclipse the compute savings, but only OP knows those details. I'm sure they are a smart bunch.
For an algorithm using the whole memory, that’s a terrible idea.
Things like Lambda do fit in this model, but they are too inefficient to model every workload.
Amazon lacks vision.
But to provision a new server, as these are "stateless" (per 12 Factor) servers, it's just 1) get a VPS 2) install Docker+Disco using our curl|sh install script 3) authorize github 4) deploy a "project" (what we call an app), setting the env vars.
All in all ~10 minutes for a new machine.
[0] https://github.com/gregsadetsky/example-flask-site/blob/main...
Marketing should be marketing and clearly so. Tech blogs are about sharing information with the community (Netflix Tech blog is a good example) NOT selling something. Marketing masquerading as a tech blog is offputting to a lot of people. People don't like being fooled with embedded advertising and putting ad copy into such pieces is at best annoying.
We know of two similar cases: a bootcamp/dev school in Puerto Rico that lets its students deploy all of their final projects to a single VPS, and a Raspberry Pi that we've set up at the Recurse Center [0] which is used to host (double checking now) ~75 web projects. On a single Pi!
From looking at your docs, it appears like using and connecting GitHub is a necessary prerequisite for using Disco. Is that correct? Can disco also deploy an existing Docker image in a registry of my choosing without a build step? (Something like this with Kamal: `kamal --skip-push --version latest`)
This has a number of benefits: in practice more “active” space is freed up as unused pages are compressed and often compressible. Often times that can be freed application memory that is reserved within application space but in the free space of the allocator, especially if that allocator zeroes it those pages in the background, but even active application memory (eg if you have a browser a lot of the memory is probably duplicated many times across processes). So for a usually invisible cost you free up more system RAM. Additionally, the overhead of the swap is typically not much more than a memcpy even compressed which means that you get dedup and if you compressed erroneously (data still needed) paging it back in is relatively cheap.
It also plays really well with disk swap since the least frequently used pages of that compressed swap can be flushed to disk leaving more space in the compressed RAM region for additional pages. And since you’re flushing retrieving compressed pages from disk you’re reducing writes on an SSD (longevity) and reducing read/write volume (less overhead than naiive direct swap to disk).
Basically if you think of it as tiered memory, you’ve got registers, l1 cache, l2 cache, l3 cache, normal RAM, compressed swap RAM, disk swap - it’s an extra interim tier that makes the system more efficient.
To clarify OP's represention of the tool, it compresses swap space not resident ram. Outside of niche use-cases, compressing swap has overall little utility.
At least, the "fear" factor (will the new system work? what bugs will it introduce? how much time will I spend, etc.) pushes a lot of folks to accept a very big price differential aka known knowns versus unknowns...
It's understandable really. It's just that once you've migrated, you almost definitely never want to go back :-)
And of course the overhead is zero when you don't page-out to swap.
However, yes, you can ask Disco to fetch an existing Docker image (we use that to self-host RabbitMQ). An example of deploying Meilisearch's image is here [0] with the tutorial here [1].
Do you typically build your Docker images and push them to a registry? Curious to learn more about your deployment process.
[0] https://github.com/letsdiscodev/sample-meilisearch/blob/main...
It's a shame they don't just license all their software stack at a reasonable price with a similar model like Sidekiq and let you sort out actually decent hardware. It's insane to consider Heroku if anything has gotten more expensive and worse compared to a decade ago yet in comparison similar priced server hardware has gotten WAY better of a decade. $50 for a dyno with 1 GB of ram in 2025 is robbery. It's even worse considering running a standard rails app hasn't changed dramatically from a resources perspective and if anything has become more efficient. It's comical to consider how many developers are shipping apps on Heroku for hundreds of dollars a month on machines with worse performance/resources than the macbook they are developing it on.
It's the standard playback that damn near everything in society is going for though just jacking prices and targeting the wealthiest least price sensitive percentiles instead of making good products at fair prices for the masses.
We built and open sourced https://canine.sh for exactly that reason. There’s no reason PaaS providers should be charging such a giant markup over already marked up cloud providers.
I even shown one customer that their elaborate cluster costing £10k a month could run on a £10 vps faster and with less headache (they set it up for "big data" thinking 50GB is massive. There was no expectation of the database growing substantially beyond that).
Their response? Investors said it must run on the cloud, because they don't want to lose their money if homegrown setup goes down.
So there is that.
Today the smallest, and even large, aws machines are a joke, comparable to a mobile phone from 15 years ago to a terrible laptop today, and take about three to six months to in rent as buying the hardware outright.
If you're on the cloud without getting 75% discount you will save money and headcount by doing everything on prem.
Maybe back in the 90s, it was okay to wait 2-3 seconds for a button click, but today we just assume the thing is dead and reboot.
Why is that an issue? Is it forbidden by HN guidelines? Or would you like all marketing to be marked as such? Which articles aren't marketing, one way or another?
Only if those man-days actually incur a marginal cost. If it's just employees you already have spending their time on things, then it's not worth factoring in because it's a cost you pay regardless.
We're actually mostly talking to people (that "schedule a meeting") to see how we can help them migrate their stuff away (from Heroku, Vercel, etc.)
But we're not sure of the pricing model yet - probably Entreprise features like Gitlab does, while remaining open source. It's a tough(er) balance than running a hosted service where you can "just" (over)charge people.
> Critically, all staging environments would share a single "good enough" Postgres instance directly on the server, eliminating the need for expensive managed database add-ons that, on Heroku, often cost more than the dynos themselves.
Heroku also has cheaper managed database add-ons, why not use something like that for staging? The move to self hosting might still make sense, my point is that perhaps the original staging costs of $500/mo could have been lower from the start.
How do you typically deploy this?
It's like juniors who did not recieve a proper training/education got hired into companies where someone told them to go serverless on some heroku or vercel, or use some incredibly expensive aws service because that's a "modern correct way" to do it, except now they were a developer for long enough to get a "senior" title in their job title now are in positions of actually modelling this architecture themselves
It’s a lot cheaper than me learning to bake as well as he does—not to mention dedicating the time every day to get my daily bread—and I’ll never need bread on the kind of scale that would make it worth my time to do so.
No one gets hurt if someone else chooses to waste their money on Heroku so why are people complaining? Of course it applies in cases where there aren't a lot of competitors but there are literally hundreds of different of different options for deploying applications and at least a dozen of them are just as reliable and cheaper than Heroku.
Nowadays when a program hits swap it's not going to fallback to a different memory usage profile that prioritises disk access. It's going to use swap as if it were actual ram, so you get to see the program choking the entire system.
The challenge I always face with homebrew PaaS solutions is that you always end up moving from managing your app to managing your PaaS.
This might not be true right now but as complexity of your app grows it’s almost always the eventual outcome.
I regularly use it on my Snapdragon 870 tablet (not exactly a top of the line CPU) to prevent OOM crashes (it's running an ancient kernel and the Android OOM killer basically crashes the whole thing) when running a load of tabs in Brave and a Linux environment (through Tmux) at the same time.
ZRAM won't save you if you do actually need to store and actively use more than the physical memory but if 60% of your physical memory is not actively used (think background tabs or servers that are running but not taking requests) it absolutely does wonders!
On most (web) app servers I happily leave it enabled to handle temporary spikes, memory leaks or applications that load a whole bunch of resources that they never ever use.
I'm also running it on my Kubernetes cluster. It allows me to set reasonable strict memory limits while still having the certainty that Pods can handle (short) spikes above my limit.
In the age of microservices and cattle servers, reboot/reinstall might be cheap, but in the long run it is not. A long running server, albeit being cattle, is always a better solution because esp. with some excess RAM, the server "warms up" with all hot data cached and will be a low latency unit in your fleet, given you pay the required attention to your software development and service configuration.
Secondly, Kernel swaps out unused pages to SWAP, relieving pressure from RAM. So, SWAP is often used even if you fill 1% of your RAM. This allows for more hot data to be cached, allowing better resource utilization and performance in the long run.
So, eff it, we ball is never a good system administration strategy. Even if everything is ephemeral and can be rebooted in three seconds.
Sure, some things like Kubernetes forces "no SWAP, period" policies because it kills pods when pressure exceeds some value, but for more traditional setups, it's still valuable.
Not if you're running with external resources of specific type, or want to share the ongoing work with others. Or need to setup 6 different projects with 3 different databases at the same time. It really depends on your setup and way of working. Sometimes you can do local staging easily, sometimes it's going to be a lot of pain.
The draw of a docker-compose-like interface for deployment is so alluring that I have spent the last year or so working on a tool called Defang that takes a compose file and deploys it to the cloud. We don't support Hetzner (yet), but we do support AWS, GCP, and DO. We provision networking, IAM, compute, database, secrets, etc in your cloud account, so you maintain full control, but you also get the ergonomics of compose.
If you are on a PaaS and you want to reduce cost without losing ergonomics and scalability, it might be interesting.
Swap helps you use ram more efficiently, as you put the hot stuff in swap and let the rest fester on disk.
Sure if you overwhelm it, then you're gonna have a bad day, but thats the same without swap.
Seriously, swap is good, don't believe the noise.
Regardless, you're going to have a much easier time developing your app if your datastore access latency is submillisecond rather than tens of milliseconds.
So that extra trouble might be worth it...
It doesn't. SSDs came a long way but so did memory dies and buses, and with that the way programs work also changed as more and more they are able to fit their stacks and heaps on memory more often than not.
I have had a problem with shellcheck that for some reason eats up all my ram when I open I believe .zshrc and trust me, it's not invisible. The system crawls to a halt.
AMD Ryzen™ 7 3700X CPU 8 cores / 16 threads @ 3.6 GHz Generation: Matisse (Zen2) RAM 64 GB DDR4 ECC
Drives 4 x 22 TB HDD 2 x 1 TB SSD
is only 104 euros a month on Hetzner.
The STORAGE alone would cost $1624 a month in most clouds
This is in the site guidelines: https://news.ycombinator.com/newsguidelines.html.
If your GC is a moving collector, then absolutely this is something to watch out for.
There are, however, a number of runtimes that will leave memory in place. They are effectively just calling `malloc` for the objects and `free` when the GC algorithm detects an object is dead.
Go, the CLR, Ruby, Python, Swift, and I think node(?) all fit in this category. The JVM has a moving collector.
This is not about belief, but lived experience. Setting up swap to me is a choice between a unresponsive system (with swap) or a responsive system with a few oom kills or downed system.
https://news.ycombinator.com/newsguidelines.html
(I've responded to the other commenter elsewhere in the thread.)
If we're talking about SATA SSDs which top at 600MBps, then yes, an aggressive application can make itself known. However, if you have a modern NVMe, esp. a 4x4 one like Samsung 9x0 series or if you're using a Mac, I bet you'll notice the problem much later, if ever. Remember the SSD trashing problem on M1 Macs? People never noticed that system used SWAP that heavily and trashed the SSD on board.
Then, if you're using a server with a couple of SAS or NVMe SSDs, you'll not notice the problem again, esp. if these are backed by RAID (even md counts).
I mean, I manage some servers, and this is my experience.
> Setting up swap to me is a choice between a unresponsive system (with swap) or a responsive system with a few oom kills or downed system.
Sorry, but are you sure that you budgeted your system requirements correctly? A Linux system shall neither fill SWAP nor trigger OOM regularly.
Yup, this is a thing. It happens because file-backed program text and read-only data eventually get evicted from RAM (to make room for process memory) so every access to code and/or data beyond the current 4K page can potentially involve a swap-in from disk. It would be nice if we had ways of setting up the system so that pages of code or data that are truly critical for real-time responsiveness (including parts of the UI) could not get evicted from RAM at all (except perhaps to make room for the OOM reaper itself to do its job) - but this is quite hard to do in practice.
Netflix is giving away free water bottles (I hate them, but I use their fast.com super often to test the speeds), another is pretending to be a blog post, but actually being an ad (if that was the case here). You just feel lied to. You cannot take anything seriously you read there, as it will probably be super biased and you cannot get your time back now.
This cache is evictable, but it'll be there eventually.
Linux used to don't touch unused pages in the RAM in the older days if your RAM was not under pressure, but now it swaps out pages unused for a long time. This allows more cache space in RAM.
> how does caching to swap help?
I think I failed to convey what I tried to say. Let me retry:
Kernel doesn't cache to SSD. It swaps out unused (not accessed) but unevictable pages to SWAP, assuming that these pages will stay stale for a very long time, allowing more RAM to be used as cache.
When I look to my desktop system, in 12 days, Kernel moved 2592MB of my RAM to SWAP despite having ~20GB of free space. ~15GB of this free space is used as disk cache.
So, to have 2.5GB more disk cache, Kernel moved 2592 MB of non-accessed pages to SWAP.
I mean something like a list of moving parts so I can understand how it works. Perhaps something like this:
https://caprover.com/#:~:text=CapRover%20Architecture%20at%2...
I'm not an AWS guy. I can see and touch the servers I manage, and in my experience, SWAP works, and works well.
wallstop@fridge:~$ free -m
total used free shared buff/cache available
Mem: 15838 9627 3939 26 2637 6210
Swap: 4095 0 4095
wallstop@fridge:~$ uptime
00:43:54 up 37 days, 23:24, 1 user, load average: 0.00, 0.00, 0.00( ) a 1% chance the system would crawl to a halt but would work
( ) a 1% change the kernel would die and nothing would work
But the cloud is different. None of the financial scale benefits are passed on to you. You save serious money running it in-house. The arguments around scale have no validity for the vast, vast majority of use cases.
Vercel isn't selling bread: they're selling a fancy steak dinner, and yes, you can make steak at home for much less, and if you eat fancy steak dinners at fancy restaurants every night you're going to go broke.
So the key is to understand whether your vendors are selling you bread, or a fancy steak dinner, and to not make the mistake of getting the two confused.
AWS isn't much better honestly.. $50/month gets you an m7a.medium which is 1 vCPU (not core) and 4GB of RAM. Yes that's more memory but any wonder why AWS is making money hand-over-fist..
NSDJUST=$(pgrep -x nsd); echo -en '-378' > /proc/"${NSDJUST}"/oom_score_adj
vm.overcommit_memory = 0
vm.overcommit_ratio = 0
vm.admin_reserve_kbytes = 262144
vm.user_reserve_kbytes = 262144
vm.min_free_kbytes = 1024000
Another option is to limit memory per application in cgroups but that requires more explaining than I am putting in an HN comment.
Another useful thing is to never OOM kill in the first place on servers that are only doing things in memory and need not commit anything to disk. So don't do this on a disked database. This is for ephemeral nodes that should self heal. Wait 60 seconds so drac/ilo can capture crash message and then earth shattering kaboom...
# cattle vs kittens, mooooo...
kernel.panic = 60
vm.panic_on_oom = 2
This is from another system I have close:
total used free shared buff/cache available
Mem: 31881 1423 1042 10 29884 30457
Swap: 976 2 974
I'm complaining about thinly veiled ad copy wearing the mask of shared technical notes. This is seen as a bad faith effort by the publisher of such notes and a dirty trick played on the reader. Advertising should announce itself for what it is.
I'm very clearly making a distinction, I like A, I don't like B.
You're taking that, saying I must actually hate both A and B, and by the way C through Z because nobody is 111% pure of heart and everybody must have at least some motivation for doing something and nobody is entirely altruistic.... which is just this crazy extreme that it's clear I don't believe at all.
I like the incentive structure that leads Netflix to produce objectively high quality articles sharing with the community in a way that really seems to be entirely untainted by the motivation.
Ad copy in tech notes does seem to taint the motivation and quality of them, it can be innocent but it doesn't seem like it and is generally irritating to a lot of people.
Dislike of a certain kind of advertising doesn't mean I'm sitting around miserable because nobody is truly altruistic as you suggest, and that the issue. My lines of thinking aren't taken to a silly extreme. A lot of disagreements these days are people reinterpreting their opposition as exclusively extremist and that's a problem.
Is earlyoom a better solution than that to prevent an erratic process from making an instance unresposnsive?
If you're running something that's too expensive for your taste and can share more information, happy to brainstorm some options.
Tracing garbage collectors solve a single problem really really well - managing a complex, possibly cyclical reference graph, which is in fact inherent to some problems where GC is thus irreplaceable - and are just about terrible wrt. any other system-level or performance-related factor of evaluation.
Once everything is installed/running, a very tldr diagram would be:
GitHub (webhook on git push) -> Docker swarm running Caddy -> Disco Daemon REST API which will ask Docker to build the image, and then does a blue-green zero-time deployment swap
But yeah, a clearer/better diagram would be great. Thanks for the push!
I’m gonna guess you’re not old enough to remember computers with memory measured in MB and IDE hard disks? Swapping was absolutely brutal back then. I agree with the other poster, swap hitting an SSD is a barely noticeable in comparison.
Many won't enable swap. For some swap wouldn't help anyways, but others it could help soak up spikes. The latter in some cases will upgrade to a larger instance without even evaluating if swap could help, generating AWS more money.
Either way it's far-fetched to derive intention from the fact.
To enable a swap file in Linux, first create the swap file using a command like sudo dd if=/dev/zero of=/swapfile bs=1G count=1 for a 1GB file. Then, set it up with sudo mkswap /swapfile and activate it using sudo swapon /swapfile. To make it permanent, add /swapfile swap swap defaults 0 0 to your /etc/fstab file.There's a lot of "it depends" here.
For example, an RC garbage collector (Like swift and python?) doesn't ever trace through the graph.
The reason I brought up moving collectors is by their nature, they take up a lot more heap space, at least 2x what they need. The advantage of the non-moving collectors is they are much more prompt at returning memory to the OS. The JVM in particular has issues here because it has pretty chunky objects.
That is my interpretation of what people are saying upthread, at least. To which posters such as yourself are saying “you still need swap.” Why?
I DON’T WANT THE KERNEL PRIORITIZING CACHE OVER NRU PAGES.
The easiest way to do this is to disable swap.
> Secondly, Kernel swaps out unused pages to SWAP, relieving pressure from RAM. So, SWAP is often used even if you fill 1% of your RAM. This allows for more hot data to be cached, allowing better resource utilization and performance in the long run.
Yes, and you can observe that even in your desktop at home (if you are running something like Linux).
> So, eff it, we ball is never a good system administration strategy. Even if everything is ephemeral and can be rebooted in three seconds.
I wouldn't be so quick. Google ran their servers without swap for ages. (I don't know if they still do it.) They decided that taking the slight inefficiency in memory usage, because they have to keep the 'leaked' pages around in actual RAM, is worth it to get predictability in performance.
For what it's worth, I add generous swap to all my personal machines, mostly so that the kernel can offload cold / leaked pages and keep more disk content cached in RAM. (As a secondary reason: I also like to have a generous amount of /tmp space that's backed by swap, if necessary.)
With swap files, instead of swap partitions, it's fairly easy to shrink and grow your swap space, depending on what your needs for free space on your disk are.
And that was like... two years ago? 1GB of RAM and actually ~700MB usable before I found the proper magik incantations to really disable kdump.
Also have used 1GB machines for literally years.
Strongly suggest you shouldn't strongly suggest.
Bring back sanity to tech.
If your problem doesn't keep growing, and you just have more data that programs want to keep in memory than you have RAM, but the actual working set of what's accessed frequently still fits in RAM, then swap perfectly solves this.
Think lots of programs open in the background, or lots of open tabs in your browser, but you only ever rapidly switch between at most a handful at a time. Or you are starting a memory hungry game and you don't want to be bothered with closing all the existing memory hungry programs that idle in the background while you play.
When you call malloc(), it requests a big chunk of memory from the OS, in units of pages. It then uses an allocator to divide it up into smaller, variable length chunks to form each malloc() request.
You may have heard of “heap” memory vs “stack” memory. The stack of course is the execution/call stack, and heap is called that because the “heap allocator” is the algorithm originally used for keeping track of unused chunks of these pages.
(This is beginner CS stuff so sorry if it came off as patronizing—I assume you’re either not a coder or self-taught, which is fine.)
fallocate -l 1G /swapfile
chmod 600 /swapfile
mkswap /swapfile
swapon /swapfile
So no, my experience with swap isn't that it's invisible with SSD.
With a good amount of swap, you don't have to worry about closing programs. As long as your 'working set' stays smaller than your RAM, your computer stays fast and responsive, regardless of what's open and idling in the background.
> Doesn't swap just delay the fundamental issue?
The fundamental issue here is what the linux fanboys literally think what killing a working process and most of the time the process[0] is a good solution for not solving the fundamental problem of memory allocation in the Linux kernel.
Availability of swap allows you to avoid malloc failure in a rare case your processes request more memory than physically (or 'physically', heh) present in the system. But in the mind of so called linux administrators even if a one byte of the swap would be used then the system would immediately crawl to a stop and never would recover itself. Why it always should be the worst and the most idiotic scenario instead of a sane 'needed 100MB more, got it - while some shit in the memory which wasn't accessed since the boot was swapped out - did the things it needed to do and freed that 100MB' is never explained by them.
[0] imagine a dedicated machine for *SQL server - which process would have the most memory usage on that system?
But that's a job applications are already doing. They put data that's being actively worked on in RAM they leave all the rest in storage. Why would you need swap once you can already fit the entire working set in RAM?
I think this is partly responsible for the increased popularity of sqlite as a backend. It's super simple and lightstream for recovery isn't that complicated.
Most apps don't need 5 9s, but they do care about losing data. Eliminate the possibility of losing data, without paying tons of $ to also eliminate potential outages, and you'll get a lot of customers.
Eg Google used to (and perhaps still does?) run their servers without swap, because they had built fault tolerance in their fleet anyway, so were happier to deal with the occasional crash than with the occasional slowdown.
For your desktop at home, you'd probably rather deal with a slowdown that gives you a chance to close a few programs, then just crashing your system. After all, if you are standing physically in front of your computer, you can always just manually hit the reset button, if the slowdown is too agonising.
...but this CX33 "server" being discussed - is a 6 bucks a month VPS [0]
Normally you build a prototype on laptop and move it out to fat hardware when it outgrows that. Here they started with 3k infra and then later realized it runs on toaster. Completely back to front.
Maybe they just never iterated on a local version and nobody developed an intuition for requirements. Switched straight to iterating on a nebulous cloud where you can't tell how much horsepower is behind the cloudfunctions etc.
Presumably there is a perfectly reasonably explanation and it's just not spelled out, it just seems weird based on given info
Water is cheap, yes. Salt isn't all that cheap, but you only need a little bit.
> [...] and I’ll never need bread on the kind of scale that would make it worth my time to do so.
If you need bread by hand, it's a very small scale affair. Your physique and time couldn't afford you large scale bread making. You'd a big special mixer and a big special oven etc for that. And you'd probably want a temperature and moisture controlled room just for letting your dough rise.
If you reserve that instance you can get it for 40% cheaper, or get 4 cores instead.
Yes it's more expensive than OVH but you also get everything AWS to offer.
The lead who wrote it had never even profiled code before, after some changes we cut it down to ~$0.01/per, but that's still insane.
Certainly true, but there are a whole lot of tools to automate those operations so that you aren't doing them constantly.
If you size your RAM and swap right, you get no service degradation, but still get away with using less RAM.
But when I was at Google (about a decade ago), they followed exactly the philosophy you were outlining and disabled swap.
It's that "touching" of all the pages controlled by the GC that ultimately wrecks swap performance. But also the fact that moving collector like to hold onto memory as downsizing is pretty hard to do efficiently.
Non-moving collectors are generally ultimately using C allocators which are fairly good at avoiding fragmentation. Not perfect and not as fast as a moving collector, but also fast enough for most use cases.
Java's G1 collector would be the worst example of this. It's constantly moving blocks of memory all over the place.
It has the benefit of absorbing memory leaks (which for whatever reason compress really well) and compressing stale memory pages.
Under actual memory pressure performance will degrade. But in many circumstances where your powerful CPU is not fully utilized you can 2x or even 3x your effective RAM (you can opt for zstd compression). zram also enables you to make the trade-off of picking a more powerful CPU for the express purpose of multiplying your RAM if the workload is compatible with the idea.
PS: On laptops/workstations, zram will not interfere with an SSD swap partition if you need it for hibernation. Though it will almost never be used for anything else if you configure your zram to be 2x your system memory.
https://postmates.com/store/restaurant-depot-4538-s-sheridan...
I blush to admit that I do from time to time pay $21 for a single sourdough loaf. It’s exquisite, it’s vastly superior to anything I could make myself (or anything I’ve found others doing). So I’m happy to pay the extreme premium to keep the guy in business and maintain my reliable access to it.
It weighs a couple of pounds, though I’m not clear how the water weight factors in to the final weight of a loaf. And I’m sure that flour is fancier than this one. I take your point—I don’t belong in the bread industry :)
You do understand what's being discussed... right?
Swap ram by itself would be stupid but no one doing this isn’t also turning on compression.
I did just this using Coolify, Mythic Beasts running Django & Postgres the other month from Google App Engine. Hilariously easy, even with my extremely rusty skills.
Either that or use a PaaS that deploys to VMs. Can't make recommendations here but you could start by looking at Semaphore, Dokku, Dokploy.
You can also self host almost any open source service without any fuss, and perform internal networking with telepresence. (For example, if you want to run an internal metabase that is not available on public internet, you can just run `telepresence connect`, and then visit the private instance at metabase.svc.cluster.local).
Canine tries to leverage all the best practices and pre-existing tools that are already out there.
But agreed, business critical databases probably shouldn't belong on Kubernetes.
Or you have a very peculiar understanding what 'VPS' means.
Heroku's pricing has _remained the same_ for at least seven years, while hardware has improved exponentially. So when you look at their pricing and see a scam, what you're actually doing is comparing a 2025 anchor to a mid-2010s price that exists to retain revenue. At the big cloud vendors, they differentiate customers by adding obstacles to unlocking new hardware performance in the form of reservations and updated SKUs. There's deliberate customer action that needs to take place. Heroku doesn't appear to have much competition, so they keep their prices locked and we get to read an article like this whenever a new engineer discovers just how capable modern hardware is.
Also: When those processes that haven't been active since boot (and which may never be active again) are swapped out, more system RAM can become available for disk caching to help performance of things that are actively being used.
And that's... that's actually putting RAM to good use, instead of letting it sit idle. That's good.
(As many are always quick to point out: Swap can't fix a perpetual memory leak. But I don't think I've ever seen anyone claim that it could.)
I wonder, though—at the risk of overextending the metaphor—what if I don’t have a kitchen, but I need the lunch meeting to be fed? Wouldn’t (relatively expensive) catering routinely make sense? And isn’t the difference between having steak catered and having sandwiches catered relatively small compared to the alternative of building out a kitchen?
What if my business is not meaningfully technical: I’ll set up applications to support our primary function, and they might even be essential to the meat of our work. But essential in the same way water and power are: we only notice it when it’s screwed up. Day-to-day, our operational competency is in dispatching vehicles or making sandwiches or something. If we hired somebody with the expertise to maintain things, they’d sit idle—or need a retainer commensurate with what the Vercels and Herokus of the world are charging. We only need to think about the IT stuff when it breaks—and maybe to the extent that, when we expect a spike, we can click one button to have twice as much “application.”
In that case, isn’t it conceivable that it could be worth the premium to buy our way out of managing some portion of the lower levels of the stack?
You say you like A and don't like B. You don't like B because it has X in it. But A also has X in it. So why do you like A but not B? It's not logically consistent. We disagree on how much X is in A. You want X to be clearly marked with red tape. It's not clear how reasonable and feasible that is or isn't. I'm saying if you're looking for X, you're going to find trace amounts of it everywhere once you start looking for it. X isn't some previously unheard of chemical that's gonna give you cancer or leaky gut though, it's other people making money. It's been chosen for us, that money is how the world works. It's not how I would do it, but I'm not in charge of the world, so it's a moot point. Everyone is weird about money in their own special way. I am no exception. What sticks in my craw is when people have problems with other people making money. How they make money is material. I'm not okay with making money off of sex trafficking or CSAM, for example, but advertising a product with an interesting bit of writing beforehand isn't that. So on the spectrum of your kid's painting that they made for you in school with crayon that were ethically sourced and drew on recycled paper, to the in your face red plastic Coca-Cola banner wrapped around the side of a bus that's gonna be fed to whales to choke and die on, where this particular blog post lies is for you to determine for yourself. Where I'm really getting at is that requiring X to be at a certain level has the unintended consequence that only big corporations with giant bags of money can create content that passes this purity test of yours, is, if we do some extrapolating, self-defeating.
Configuring a web server is a low-difficulty task that should be available for any good software developer with 3 days to study for it. It's absurd for a developer to need to configure a web server, but insist on paying a large rent and cede control to some 3rd party instead of just doing it.
Without swap oom killer runs and things become responsive.
Adding a couple of gb of swap means the image resizing is _slow_, but completes without causing issues.
That's more than 1/3 of the cost of a developer there.
That will save you some week of a person's work to set things up and half-a-day every couple of months to keep it running. Rounding way up.
By the time the product is a success and reaches a scale where it becomes cost prohibitive, they have enough resources to expand or migrate away anyway.
I suppose for solo devs it might be cheaper to setup a box for fun, but even then, I would argue that not everyone enjoys doing devops and prefers spending their time elsewhere.
Partly it's a money thing (they want to sell you RAM), partly it's so that the shared disk isn't getting thrashed by multiple VPS
Example on my personal VPS
$ free -m
total used free shared buff/cache available
Mem: 3923 1225 328 217 2369 2185
Swap: 1535 1335 200If you setup a server with the curl|sh install script on the homepage, you'll get a url at the end that directs you there. And you can use the CLI too of course.
But yeah, thanks for the reminder!
I am building https://github.com/openrundev/openrun/. Main difference is that OpenRun has a declarative interface, no need for manual CLI commands or UI operations to manage apps. Another difference is that OpenRun is implemented as a proxy, it does not depend on Traefik/Nginx etc. This allows OpenRun to implement features like scaling down to zero, RBAC access control for app access, audit logs etc.
Downside with OpenRun is that is does not plan to support deploying pre-packaged apps, no Docker compose support. Streamlit/Gradio/FastHTML/Shiny/NiceGUI apps for teams are the target use case. Coolify has the best support and catalog of pre-packaged apps.
Swap is good to have. The value is limited but real.
Also not having swap doesn't prevent thrashing, it just means that as memory gets completely full you start dropping and re-reading executable code over and over. The solution is the same in both cases, kill programs before performance falls off a cliff. But swap gives you more room before you reach the cliff.
systemd-oomd and oomd use the kernel's PSI[2] information which makes them more efficient and responsive, while earlyoom is just polling.
earlyoom keeps getting suggested, even though we have PSI now, just because people are used to using it and recommending it from back before the kernel had cgroups v2.
[0]: https://www.freedesktop.org/software/systemd/man/latest/syst...
I've had good experience with linux's multi-generation LRU feature, specifically the /sys/kernel/mm/lru_gen/min_ttl_ms feature that triggers OOM-killer when the "working set of the last N ms doesn't fit in memory".
If the implementer cares about memory use it won't. There are ways to compact objects that are a lot less memory-intensive than copying the whole graph from A to B and then deleting A.
That said, they are emerging. I'm actually working on a drop-in Vercel competitor at https://www.sherpa.sh. We're 70% lower cost by running on EU based CDN and dedicated servers (Hetzner, etc). But we had to build the relationships to solve all the above challenges first.
Or they didn't check. A business still existing is pretty weak evidence that the pricing is reasonable.
Heroku has obviously stagnated now but their stack is _very cool_ for if you have a fairly simple system but still want all the nice parts of a mode developed ops system. It almost lets you get away with not having an ops team for quite a while. I don't know any other provider that is low-effort "decent" ops (Fly seems to directionally want to be new Heroku but is still missing a _lot_ in my book, though it also has a lot)
As I said earlier
https://news.ycombinator.com/threads?id=awesome_dude#4566311...
I once used an Intel Optane drive as swap for a job that needed hundreds of gigabytes of ram (in a computer that maxed out at 64 gigs). The latency was so low that even while the task was running the machine was almost perfectly usable; in fact I could almost watch videos without dropping frames at the same time.
(Just remember to take regular backups now, so that when this 5 year deal expires you don’t get into the same situation again :-)
Every other time I login to the admin site I get a Heroku error.
(Similarly to how you pay Amazon or Google etc not just for the raw cloud resources, but for the system they provide.)
I grew up in Germany, but now live in Singapore. What's sold as 'good' sourdough bread here would make you fail your baker's training in Germany: huge holes in the dough and other defects. How am I supposed to spread butter over this? And Mischbrot, a mixture of rye and wheat, is almost impossible to find.
So we make our own. The goal is mostly to replicate the everyday bread you can buy in Germany for cheap, not to hit any artisanal highs. (Though they are massively better IMHO than anything sold as artisanal here.)
Interestingly, the German breads we are talking about are mostly factory made. Factory bread can be good, if that's what customers demand.
See https://en.wikipedia.org/wiki/Mischbrot
Going on a slight tangent: with tropical heat and humidity, non-sourdough bread goes stale and moldy almost immediately. Sourdough bread can last for several days or even a week without going moldy in a paper bag on the kitchen counter outside the fridge, depending on how sour you go. If you are willing to toast your bread, going stale during that time isn't much of an issue either.
(Going dry is not much of an issue with any bread here--- sourdough or not, because it's so humid.)
Gives you some time to upgrade, or tune services before it goes ka-boom.
Wait, what? Salt is literally one of the cheapest of all materials per kilogram that exists in all contexts, including non-food contexts. The cost is almost purely transportation from the point of production. High quality salt is well under a dollar a pound. I am currently using salt that I bought 500g for 0.29 euro. You can get similar in the US (slightly more expensive).
This was a meme among chemical engineers. Some people complain in reviews on Amazon that the salt they buy is cut with other chemicals that make it less salty. The reality is that there is literally nothing you could cut it with that is cheaper than salt.
If your memory usage spikes suddenly, a nominal amount of swap isn't stopping anything from getting killed; you're at best buying yourself a few seconds, so unless you spend your time just staring at the server, it'll be dead anyways.
Oh, and the new machine has unified RAM. The old machine had a bit of extra RAM in the GPU that I'm not counting here.
As far as I can tell, the new RAM is a lot faster. That counts for something. And presumably also uses less power.
On my 8gb M1 Mac, I can have a ton of tabs open and it'll swap with minimal slowdown. On the other hand, running a 4k external display and a small (4gb) llm is at best horrible and will sometimes require a hard reset.
I've seen similar with different combinations of software/hardware.
> systemd-oomd periodically polls PSI statistics for the system and those cgroups to decide when to take action.
It's unclear if the docs for systemd-oomd are incorrect or misleading; I do see from the kernel.org link that the recommended usage pattern is to use the `poll` system call, which in this context would mean "not polling", if I understand correctly.
Unless they plan to move prod and dev as well, and using staging now as a test platform.
Once few problems glitch when moving to prod, they may no longer think they are saving much money.
Ansible basically automates the workflow of: log in to X, do step X (if Y is not present). It has broad support for distros and OSes. It's mostly imperative and can be used like a glorified task runner.
Salt let's you mostly declaratively describe the state of a system. It comes with a agent/central host system for distributing this configuration from the central host to the minions (push).
Puppet is also declarative and also comes with an agent/central host system but uses a pull based approach.
Specialized/ exotic options are also available, like mgmt or NixOS.
And maybe plan on getting more RAM.
(It's your system. You're allowed to tune it to fit your usage.)
But sure, it's cheap otherwise. Point granted.
One way or another, salt is not a major driver of cost in bread, because there's relatively little salt in bread. (If there's 1kg of flour, you might have 20g of salt.)
It's actually not too bad, if look at the capital cost of a bread factory amortised over each loaf of bread.
The equipment is comparatively more expensive for a home baker who only bakes perhaps two loafs a week.
The memory that's now not in use, but still held onto, can be swapped out.
As a small example from a default Ubuntu installation, "unattended-upgrades" is holding 22MB of RSS, and will not impact system performance at all if it spends next week swapped out. Bigger examples can be found in monolithic services where you don't use some of the features but still have to wire them into RAM. You can page those inactive sections of the individual process into swap, and never notice.
I do: https://postimg.cc/G8Gcp3zb (casualmeasurement.png)
The case of swap thrashing sounds like a misbehaving program, which can maybe be tamed by oomd.
System responsiveness though needs a complete resource control regime in place, that preserves minimum resources for certain critical processes. This is done with cgroupsv2. By establishing minimum resources, the kernel will limit resources for other processes. Sure, they will suffer. That’s the idea.
Actually I am looking for tools to automate DevOps and security for self-hosting
All of my staging setups are on a ~$15 Hetzner server, with a GitHub Action to `docker compose build && docker compose up -d` remotely, with an Apache service with a wildcard certificate and dynamic host names. We have 3..n staging setups, with each PR spinning up a new staging site just for that PR.
It's been working with us for years, for a team of 10 developers.
Also since the refcounts are inline, adding a reference to a cold object will update that object. IIRC Swift has the latter issue as well (unless the heap object’s RC was moved to the side table).
$55 server
$550 aws server
$3000 aws based paas server
What is this referring to? Concerns about capacity if you need to scale up quickly? Or just "political"/marketing considerations about people not being used to being served by a Hetzner server?
(Except this backfires, because a service running on a RHEL or Debian machine might go on for 5-10 years untouched without any particular issue, security aside, while anything relying on kubernetes or the hyperscaler's million little services needs to be tweaked every 6 months and re-engineered every few years or it will completely stop working.)
It's precisely why we moved from a self-hosted demo environment server to heroku - the developers that had both the skills to manage a server and enough seniority to have access accross all the different projects could bring in more by building.
If your group pushes over 23TiB/Month, than most usually look for un-metered colo hosts, and or CDN services with your resource integrity Attribute tags set.
Cloud makes sense for small IT shops that can't afford a fully staffed team. The general rule is a 5:1 labor to hardware cost amortized over 3 years.
AWS was successful as IT had enormous upfront costs most people found difficult to justify, and data-centers could absorb a DDoS that would be expensive to mitigate.
Rule #17: "Only forward meaningful data at every layer of a design, as it often naturally ensures a feasible convergent behavior."
There are a number of great options, but depends on the use-cases. =3
This part can be outsourced to a PaaS company, so that the company engineers can be focused on what is the company actually making money from.
In practice, there are two situations where cloud makes sense:
1. You infrequently need to handle traffic that unpredictably bursts to a large multiple of your baseline. (Consider: you can over provision your baseline infrastructure by an order of magnitude before you reach cloud costs) 2. Your organization is dysfunctional in a way that makes provisioning resources extremely difficult but cloud can provide an end run around that dysfunction.
Note that both situations are quite rare. most industries that handle that sort of large burst are very predictable: event management know when a client will be large and provision ticket sales infra accordingly, e-commerce knows when the big sale days will be, and so on. In the second case, whatever organizational dysfunction caused the cloud to be appealing will likely wrap itself around the cloud initiative as well.
What I was trying to say is that the actual information on when there's memory pressure is more accurate for systemd-oomd / oomd because they use PSI, which the kernel itself is updating over time, and they just poll that, while earlyoom is also internally making its own estimates at a lower granularity than the kernel does.
The free memory won't go below a configurable percentage and the contiguous io algorithms of the swap code and i/o stack can still do their work.
> disco provides a "good enough" Postgres addon.
> This addon is a great way to quickly setup a database when Postgres is not mission critical to your system. If you need any non-basic features, like replication, automatic failover, monitoring, automatic backups and restore, etc. you should consider using a managed Postgres provider, such as Neon or Supabase.
How come automatic backups is considered an “advanced” feature?
Also I can’t think of a single application since 2012 that I have worked on that did not have a secondary/follower instance deployed. Also suggesting Neon and friends is fine, but I wonder what is your average latency, Hetzner does not have direct connection to the DCs these databases are hosted.
But I've migrated plenty of companies off custom deployment setups to PAAS and told many ceo's simply what OP above has shared. Even a part time dev ops engineer is still $60000 a year, and that can buy us a LOT on PAAS. Using PAAS you can have effectively zero dev ops, I've also trained non technical people on how to scale their own servers if no devs are around because you just have a web based UI slider.
I consider myself a developer who cares more about the business, risk, profits and runway. A lot of developers don't share this mentality (which is fine btw always need engineers who like engineering for engineering sakes) but in meetings you will have a hard time beating me in an argument if you try to say that running servers ourselves would be "cheaper", and/or even faster, safer and definitely not more stable. (obviously not in all situations, but kind of most for modern crud web apps that don't require complicated compute setups)
I'm probably being overly antagonistic, forgive me for that, though highly recommend questioning the real cost of running your own setups.
We have a policy that our customers are responsible for all their business-related input, but we make the decisions about the technical implementation. Every technical decision that the customer wants to make basically costs extra.
In this case we built a rather simple multi-tenancy B2B app using Laravel, with one database per tenant. They planned to start with a single customer/tenant, scaling up to maybe a few dozen within the next years, with less than a hundred concurrent users over the first five years. There were some processes with a little load, but they were few, running less that a minute each and already built up to run asynchronous.
We planned a single Hetzner instance and to scale up as soon as we would see it reaching its limits. So less than 100 €/month.
The customer told us that they have a cooperation with their local hosting provider (with "special conditions!") and that they wanted to use them instead.
My colleague did all the setup, because he is more experienced in that, but instead of our usual five-minute-setup in Forge (one of the advantages of the Laravel ecosystem), it took several weeks with the hosting provider, where my colleague had to invest almost full time just for the deployment. The hosting provider "consulted" out customer to invest in a more complex setup with a load balancer in front, to be able to scale right away. They also took very long for each step, like providing IP addresses or to handle the SSL certificates.
We are very proud of our very fast development process and having to work with that hosting provider cost us about one third of our first development phase for the initial product.
It's been around two years since then. While the software still works as intended, the customer could not grow as expected. They are still running with only one single tenant (basically themselves) and the system barely had to handle more than two concurrent users. The customer recently accidentally mentioned that they pay almost 1000€/month for the hosting alone. But it scales!
[1] https://www.hetzner.com/dedicated-rootserver/ax162-s/configu...
Ansible can also do that, on top of literally anything else you could want - network configuration, infrastructure automation, deployment pipelines, migrations, anything. As always, that flexibility can be a blessing or a curse, but I think Ansible manages it well because it's so KISS.
RedHat's commercial Ansible Automation Platform gives you more power for when you need it, but you don't need it starting out.
They replaced a $500/mo bill with a $55/mo server. And at the same time increased what they could do before - run 5 extra staging environments!
While saving $445/mo isn't nothing, in my book enabling teams to freely run the staging environments they need is the real win here! Limiting testing resources can be a real drag on momentum in a project!
Forge seems like a great integrated solution (I subscribe to their newsletter and their product updates seem quite frequent and useful). What's been your experience with them? Any particular things you like, or dislike about them?
I'm also curious when you talk about scaling up Forge - is that something you've done, and is that generally easy to do?
Thanks a lot!
I fully agree with you though, it's table stakes (unintended pun!) for any prod deployment, just as read-only followers, etc. Our biggest, most important point, is that folks should be using real dbs hosted by people who know what they're doing. The risk/reward ratio is out of whack in terms of doing it yourself.
And finally, re Hetzner and cross-DC latency, that's unfortunately a very good issue that we had to plan for in another case - specifically, a customer using Supabase (which is AWS-based). The solution was to simply use an EC2 machine in the same region. Thankfully, some db providers end up being explicit about which AWS region they run in - and obviously, using AWS RDS is also an option! It's definitely a consideration.
Re Load balancing for example, Disco is built on top of Docker Swarm, so you can add nodes (ie machines) to scale horizontally - `disco nodes:add root@<ip>`
For monitoring/alerting, we offer some real time cpu/memory metrics (ie `docker stats`) and integrate with external syslog services.
Do you have specific use cases in mind which current PaaS providers satisfy? Would you say that these kinds of concerns are what's holding you back from leaving Heroku or others (and are you considering leaving because of price, support, etc.)? Cheers
I'm not sure what you mean here? Swapping out infrequently accesses pages to disk to make space for more disk cache makes sense with our without compression.
Almost by definition, that leaked memory is never accessed again, so it's very cold. But the applications don't put this on disk by themselves. (If the app's developers knew about which specific bit is leaking, they'd rather fix the leak then write it to disk.)
Signed up with Contabo without incident and have been a happy customer ever since.
Look, whether or not Hetzner chose to block me out of blatant geo-racism is not at issue here, I wouldn't want to do business with them either way since they declined to give me a reasonable explanation and I wouldn't feel secure with a provider like that.
background: I have been self-hosting apps on VPS for a while now but just started using a tool
How do I harden the server, back it up, etc? Basically the layer below Disco, to go beyond running it as a "toy"
This is not a dig at Disco, I run into the same issue with virtually any other self-hosted PaaS I could find.
Therefore it is better to always tune "vm.swappiness" to 1 in /etc/sysctl.conf
You can also configure your web server / TCP stack buffers / file limits so they never allocate memory over the physical ram available. (eg. in nginx you can setup worker/connection limits and buffer sizes.)
Ansible-Lockdown is another excellent example of how Ansible can be used to harden servers via automation.
I have to ask - do scripts not work for you?
When I had to do this back in 2005 it was automated with 3 main steps:
1. A preseed (IIRC) debian installation disc (all the packages I needed where installed at install time), and
2. Which included a first-boot bash script that retrieved pre-compiled binaries from our internal ftp site, and
3. A final script that applied changes to the default config files and ran a small test to ensure everything started.
Zero human interaction after powering a machine on with the disc in the drive.
These days I would do it even better (system-d configs, Nix perhaps, text files (such as systemd units) can be retrieved automagically after boot, etc).
Right, you seem to be not understanding what I'm getting at.
Memory exhaustion is bad, regardless of swap or not.
Swap gets you a better performing machine because you can swap out shit to disk and use that ram for vfs cache.
the whole "low latency" and "I want my VM to die quicker" is tacitly saying that you haven't right sized your instances, your programme is shit, and you don't have decent monitoring.
Like if you're hovering on 90% ram used, then your machine is too small, unless you have decent bounds/cgroups to enforce memory limits.
It is in general the simplest of these systems to get started with and you should be able to incrementally adopt it. There is also a plethora of free online resources available for it.
That reads like what they said? You reserve part of the RAM as a swap device, and memory is swapped from resident RAM to the swap ramdisk, as long as there’s space on there. And AFAIK linux will not move pages between swap devices because it doesn’t understand them beyond priority.
Zswap actually seems strictly better in many cases (especially interactive computers / dev machines) as it can more flexibly grow / shrink, and can move pages between the compressed RAM cache and the disk swap.
They don't want our hosting solutions but insist on using their own hosting partners
The result are similar:
- its at least five times more expensive on pure hosting costs
- we lose a considerable amount of time dealing with the hosting partner (which we bill to the customer)
- it's always a security nightmare, either because they put so much "safety protections" in place that it's unusable (think about the customer wanting an Internet-facing website, but the servers are private...) or because they don't put any safety settings in place so the servers are regularly taken down through awfully simple exploits (think about SSH root access with "passw0rd" as password...)
- customer keep complaining about performances to us, but what can you do when the servers are sharing a 100Mbps connection, or the filesystem is on an NFS with <20Mbps bandwidth
The easiest way affecting everything running on the system might not be the best or even the correct way to do things.
There's always more than one way to solve a problem.
Reading the Full Manual (TM) is important.
If you factor in salaries, I can see this ending up costing more than Heroku. $3000/m is one (underpaid) developer here in Scandinavia.
That's the equation that's often lacking, and why Heroku is still worth it where I work.
Of course, the difference between sourdough and anything else is astonishing, I just can't comprehend someone charging $21 for it!
Their advertised prices are not half of Hetzner, but you can find hidden deals if you do a Google search, or via sites like https://racknerdtracker.com (no affiliation).
Breaking into a home is relatively easy.
And unless you live in the US and is willing to actually shot someone (with all the paperwork that entails, as well as physical and legal risks), the fact is that you can't actually stop a burglary.
Local hosting can also be comparing apple with oranges. A local data center that provide a physical machine is very different from a cloud provider, especially if that cloud is located in a different continent and under different jurisdictions. Given that they were providing SSL certificates, was this a local php webshop? Data centers should be a bit more proficient with things like IP addresses and setting up any cast, but less so in providing help with php or certificates, and if they sell that it may not be their area of expertise.
What prevented them from scaling to more tenants?
Companies that use k3/k8's they may still have bare metal nodes that are dedicated to a role such as databases, ceph storage nodes, DMZ SFTP servers, PCI hosts that were deemed out of scope for kube clusters and of course any "kittens" such as Linux nodes turned into proprietary appliances after installing some proprietary application that will blow chunks if shimmed into k8's or any other type of abstraction layer.
- hardware, networks, monitoring, provisioning, server room locations in existing buildings, how to prepare server rooms
- and so on up to hiring and firing sysadmins, salary negotiations[2], vendor negotiations and the first book even had a whole chapter dedicated to "Being happy"
[1] There is a third author as well now, but those two were the ones that are on the cover of my book from 2005 and that I can remember
[2] Has mostly worked well after I more or less left sysadmin behind as well
ls -lrt, ls -lSh and ls -lShr are also very common in my daily use, depending on what I'm doing.
However, from my experience, normal (eviction based) usage of SWAP doesn't impact the life of an SSD in a measurable manner. My 256GB system SSD (of my desktop system) shows 78% life remaining after 4 years of power on hours, which also served as /home for at least half of its life.
But also false. Swap is there so anonymous pages can be evicted. Not as a “slow overflow for RAM”, as a lot of people still believe.
By disabling swap you can actually *increase* thrashing, because the kernel is more limited in what it can do with the virtual memory.
Yup, that part of my comment was culmination of using Linux desktops for the last two decades. :)
> I wouldn't be so quick. Google ran their servers without swap for ages.
If you're designing this from get go and planning accordingly, it doesn't fit into my definition of eff it, we ball, but let's try this and see whether we can make it work.
> With swap files, instead of swap partitions,...
I'm a graybeard. I eyeball a swap partition size while installing the OS, and just let it be. Being mindful and having good amount of RAM means that SWAP acts as a eviction area for OS first, and as an escape ramp second, in very rare cases.
--
Sent from my desktop.
There are some folks with good offerings (Fly, Railway, etc), but the feature set of Heroku is deeper, and more important for production apps, than most people realize. They aren’t a good place for hobbyists anymore though. I agree with that.
Detecting things are down is far easier than detecting things are slow.
I'd rather that oom started killing things though than a kernel panic or a slow system. Ideally the thing that is leaking, but if not the process using the most memory (and yes I know that "using" is tricky)
total used free shared buff/cache available
Mem: 31989 11350 4474 2459 16164 19708
Swap: 6047 20 6027
Mem: 1919 333 75 0 1511 1403
Swap: 2047 803 1244
If I were to increase this to 8G of ram instead of 2G, but for arguments sake had to have no swap as the tradeoff, would that be better or worse. Swap fans say worse.
How about this server:
total used free shared buffers cached
Mem: 8106 7646 459 0 149 6815
-/+ buffers/cache: 681 7424
Swap: 6228 25 6202
How long does the server have to run to reach 100% of ram?
25MB swap use seems normal for a server which doesn't juggle much tasks, but works on one.
As I noted somewhere, my other system has 2,5GB of SWAP allocated over 13 days. That system is a desktop system and juggles tons of things everyday.
I have another server with tons of RAM, and the Kernel decided not to evict anything to SWAP (yet).
> If I were to increase this to 8G of ram instead of 2G, but for arguments sake had to have no swap as the tradeoff, would that be better or worse. Swap fans say worse.
I'm not a SWAP fan, but I support its use. On the other hand I won't say it'd be worse, but it'd be overkill for that server. Maybe I can try 4, but that doesn't seem to be necessary if these numbers are stable over time.
Here’s a screenshot from atop while the task was running: <https://db48x.net/temp/Screenshot%20from%202019-11-19%2023-4...>. Note the number of page faults, the swin and swout (swap in and swap out) numbers, and the disk activity on nvme0n1. Swap in is 150k, and the number of disk reads was 116k with an average size of 6KB. Swap out was 150k with 150k disk writes of 4KB. It’s also reading from sdh at a fair clip (though not as fast as I wanted!)
<https://db48x.net/temp/Screenshot%20from%202019-12-09%2011-4...> is interesting because it actually shows 24KB average write size. But notice that swout is 47k but there were actually 57k writes. That’s because the program I was testing had to write data out to disk to be useful, and I had it going to a different partition on the same nvme disk. Notice the high queue depth; this was a very large serial write. The swap activity was still all 4KB random IO.
Our philosophy is built on the "cattle, not pets" [0] and 12-factor [1] app methodologies. To some extent, the Disco server itself should be treated as disposable.
Disco runs your applications, which are just deployments of your code (ie git pulls). There's nothing on the server itself to back up. If a server were to die, you'd spin up a new one, run the install.sh script, and redeploy your apps in about 15 minutes.
For application data, our stance is that we believe you should use a dedicated, managed database provider for prod workloads. While we can run a "good enough" postgres as noted, we treat that as a dev/staging tool. Disco handles the stateless application layer, you should entrust your critical stateful data to a service that specializes in that.
Finally, re: security, we recommend a fresh Ubuntu 24.04 LTS server, which handles its own OS security updates. Disco only exposes the necessary web and SSH ports, so the attack surface is minimal by default.
[0] https://cloudscaling.com/blog/cloud-computing/the-history-of...
Where they get you is all the ancillary shit, you buy some database/backup/storage/managed service/whatever, and it is priced in dollars per boogaloo, you also have to pay water tax on top, and of course if you use more than the provisioned amount of hafnias the excess ones cost 10x as much.
Most customers have no idea how little compute they are actually buying with those services.
Almost VPS-sized! haha
(I really wish we could support phones as the ultimate self-hosting device)
Enables Multi-Gen LRU (improved page reclaim and caching policy).
Prevents thrashing, improves loading speeds under low ram conditions.
Requires kernel 6.1+.
Has dramatic effect especially on slower HDDs.
For slower HDDs, consider 1000 instead of 300 for min_ttl_ms.
sudo tee /etc/tmpfiles.d/mglru.conf <<EOF
w- /sys/kernel/mm/lru_gen/enabled - - - - y
w- /sys/kernel/mm/lru_gen/min_ttl_ms - - - - 300
EOFDirty buffer should also be tuned (limited), absolutely. Default is 20% of RAM, (with 5 second writeback and 30 second expire intervals), which is COMPLETELY insane. I limit it to 64 MB max usually, with 1 second writeback and 3 second expire intervals.
My experience is the exact opposite. If anything 2-3 second button clicks are more common than ever today since everything has to make a roundtrip to a server somewhere whereas in the 90s 2-3s button click meant your computer was about to BSOD.
Edit: Apple recently brought "2-3s to open tab" technology to Safari[1].
[1] https://old.reddit.com/r/MacOS/comments/1nm534e/sluggish_saf...
At a certain scale (or when you do more custom dev), you just don't prioritize it because it's a blip in your financials compared to salaries. And it's not worth spending what might be thousands (or tens of thousands) of dollars of engineering and testing effort to migrate off, when there are other priorities.
And one day you (in our case) realize that you're spending $600/month between Linode/AWS/Fly/Render (cuz we experimented a lot), claude code can help you with some of the stuff, and you want to consolidate it all back to the olden days where you just had 2-3 servers paying a total of $60-75 a month . But you still have to set aside probably a day or two to do it (no longer a couple sprints). So then the math works out where we make that money back within a few months.
So that's where I am at the moment.
But this is also one of those things where, almost invariably after you do it, you think "Oh man, we should've done this 3 years ago!!! It just ended up taking a day and everything's working beautifully"
So most of the time I'd prefer option 3: the OOM killer to reap a few offending programs and let me handle restarting them.
Simplicity is uncomfortable to a lot of people when they're used to doing things the hard way.
I bet you could figure out `apt install nginx` and a basic config pretty quickly, definitely faster than a web dev could learn game programming. “What do you mean, I have to finish each loop in 16 msec?”
Also, "small scale" means different things to different people. Given the full topic at hand, I would call it "nano scale". Depending upon your specific schema, you can serve tens of thousands of queries per second with a single server on modern hardware, which is way more than enough for the vast majority of workloads.
Honestly, reading these threads it sounds to me like a lot of people are still launching new projects on Heroku. I wouldn’t have guessed that was true before reading this.
Uhh... A VMM that swaps out to disk an allocated page to make room for more disk cache would be braindead. The process has allocated that memory to use it. The kernel doesn't have enough information to deem disk cache a higher priority. The only thing that should cause it to be swapped out is either another process or the kernel requesting memory.
/swapfile swap swap sw 0 0
or via ansible:
mount:
src: "/swapfile"
name: "swap"
fstype: "swap"
opts: "sw"
passno: "0"
dump: "0"
state: presentAs someone with zero ansible experience, can you elaborate on why a yaml list is better than a simple shell script with comments before each command?
Volunteering to be preempted by broken systems more often is a sucker’s bet. Solve problems so they stay solved. It’s more work now, but reduces the interest rate on past work so you can get new things done.
So no, VPS is a proper virtualization for a 15 years. And with a proper virtualization you have the full control.
And no, if you need 100MB more then it's literally not important how much RAM do you have. You just needed 100MB more this time.
The default thought to use the cloud because it's more performant though for even the most basic to intermediate loads instead of the hardware directly is what I'm referring to and what the article is referring to.
It's very easy to pay for cloud services per transaction at greatly inflated prices than what it actually costs, and how many cpu cores it actually uses at any given time.
The person you're replying to mentioned a self-hosting use case, so this probably isn't relevant for that, but Ansible can also be configured for a pull approach, which is useful for scaling.
> Lock all pages which are currently mapped into the address space of the process.
> Lock all pages which will become mapped into the address space of the process in the future.
Some skills are required, but it's really not that hard once you learn the technique and have done it a few times.
MGLRU is basically a smarter version of already existing eviction algorithm, with evicts (or keeps) both page cache and anon pages, and combined with min_ttl_ms it tries to keep current active page cache for a specified amount of time. It still takes into account swappiness and does not operate on a fixed amount of page cache, unlike le9.
Both are effective in trashing prevention, both are different. MGLRU, especially with higher min_ttl_ms, could cause OOM killer more frequently than you'd like it to be called. I find le9 more effective for desktop use on old low-end machines, but that's only because it just keeps the (large/er amounts of) page cache. It's not very preferable for embedded systems for example.
I don't think using swap as "emergency RAM" makes a lot of sense in 2025. The arguments in favor of swap which I find convincing are about allowing the system to evict low use pages which otherwise would not be evictable.
Claiming any decision is “brain dead” in something as heuristic heavy and impossible to compute optimally as resident memory pages is quite the statement to make; this is a form of the knapsack problem (NP-complete at least) with the added benefit of time where the items are needed in some specific indeterminate order in the future and there’s a whole bunch of different workloads and workload permutations that alter this.
To drive this point home in case you disagree, what’s dumber? Swapping out to disk an allocated page (from the kernel’s perspective) that’s just sitting in the free list of the userspace allocator for that process or a page of some frequently accessed page of data?
Now, I agree that VMMs may not do this because it’s difficult to come up with these kinds of scenarios that don’t penalize the general case, more importantly than performance this has to be a mechanism that is explainable to others and understandable for them. But claiming it’s a braindead option to even consider is IMHO a bridge too far.
Another option is to run BSD to avoid the Linux oom issue
For example, I'm not using Hetzner but I run NetBSD entirely from memory (no disk, no swap) and it never "went down" when out of memory
Looks like some people install FreeBSD and OpenBSD on Hetzner
https://gist.github.com/c0m4r/142a0480de4258d5da94ce3a2380e8...
https://computingforgeeks.com/how-to-install-freebsd-on-hetz...
https://web.archive.org/web/20231211052837if_/https://www.ar...
https://community.hetzner.com/tutorials/freebsd-openzfs-via-...
https://www.souji-thenria.net/posts/openbsd_hetzner/
https://web.archive.org/web/20220814124443if_/https://blog.v...
https://www.blunix.com/blog/how-to-install-openbsd-on-hetzne...
https://gist.github.com/ctsrc/9a72bc9a0229496aab5e4d3745af0b...
If it is possible to boot Hetzner from a BSD install image using "Linux rescue mode"^1 then it should also possible to run NetBSD entirely from memory using custom kernel
Every user is different but this is how I prefer to run UNIX-like OS for personal, recreational use; I find it more resilient
1.
https://docs.hetzner.com/robot/dedicated-server/troubleshoot...
https://blog.tericcabrel.com/hetzner-rescue-mode-unlock-serv...
https://github.com/td512/rescue
https://gainanov.pro/eng-blog/linux/hetzner-rescue-mode/
https://docs.hetzner.com/cloud/servers/getting-started/rescu...
ChromeOS has an interesting approach to Linux oom issues. Not sure it has ever been discussed on HN
https://github.com/dct2012/chromeos-3.14/raw/chromeos-3.14/m...
Edit: I feel like I should give you a more fulsome response, so here goes:
I understand the frustration. I feel it too, even apart from HN making me feel it as part of my job. But I've had to learn some lessons about this, such as:
1. It doesn't help to assume the position of the-one-who-is-not-stupid. Doing that is supercilious and just means you'll contribute to making things worse.
2. Far better is to accept that, as one is human, one shares in all the qualities of being human, including a full complement of stupidity.
3. I forget the third lesson!
No. It covered setting up all the applications needed as well (nginx, monitoring agent, etc), installing keys/credentials.
What did parent mention that can't be covered by the approach I used?
Oh, there’s actually this tutorial that shows a tiny preview of it:
https://disco.cloud/docs/deployment-guides/meilisearch
Thanks for the reminder!
Sure you can script all the things into 3 steps, just like you can draw an owl with a couple circles.
Stupid people ruin everything.
Maintain, maybe. The setup for everything extra can scripted, and include a few packages I had to build from source myself because there was no binary download.
> One of the major differences between M7a instances and the previous generations of instances, such as M6a instances, is their vCPU to physical processor core mapping. Every vCPU on a M7a instance is a physical CPU core. This means there is no Simultaneous Multi-Threading (SMT). By contrast, every vCPU on prior generations such as M6a instances is a thread of a CPU core.
My wild guess is they're disabling it. For Intel instance families they loudly praise their custom Intel processors, but this page does not contain the word "custom" anywhere.
I'm not a PaaS user, and I encourage people to avoid vendor lock-in and be in control of their own destiny. It takes work though, and you need to sweat the details if you care about reliability and security, which continue to be problem areas for more DIY solutions.
If people aren't willing to put in the work, I'd rather they stick to the managed services so they don't contribute to eroding the already abysmal trust of the industry at large.
I rewrote a slice of the program in Rust with quite promising results, but by that time there wasn’t really any demand left. You see, one of the many uses of Reposurgeon <http://www.catb.org/esr/reposurgeon/> is to convert SVN repositories into Git repositories. These performance results were taken while reposurgeon was running on a dump of the GCC source code repository. At the time this was the single largest open source SVN repository left in the world with 287k commits. Now that it’s been converted to a Git repository it’s unlikely that future Reposurgeon users will have the same problem.
Also, someone pointed out that MG-LRU <https://docs.kernel.org/admin-guide/mm/multigen_lru.html> might help by increasing the block size of the reads and writes. It was introduced a year or more after I took these screenshots, so I can’t easily verify that.
{kind=link}
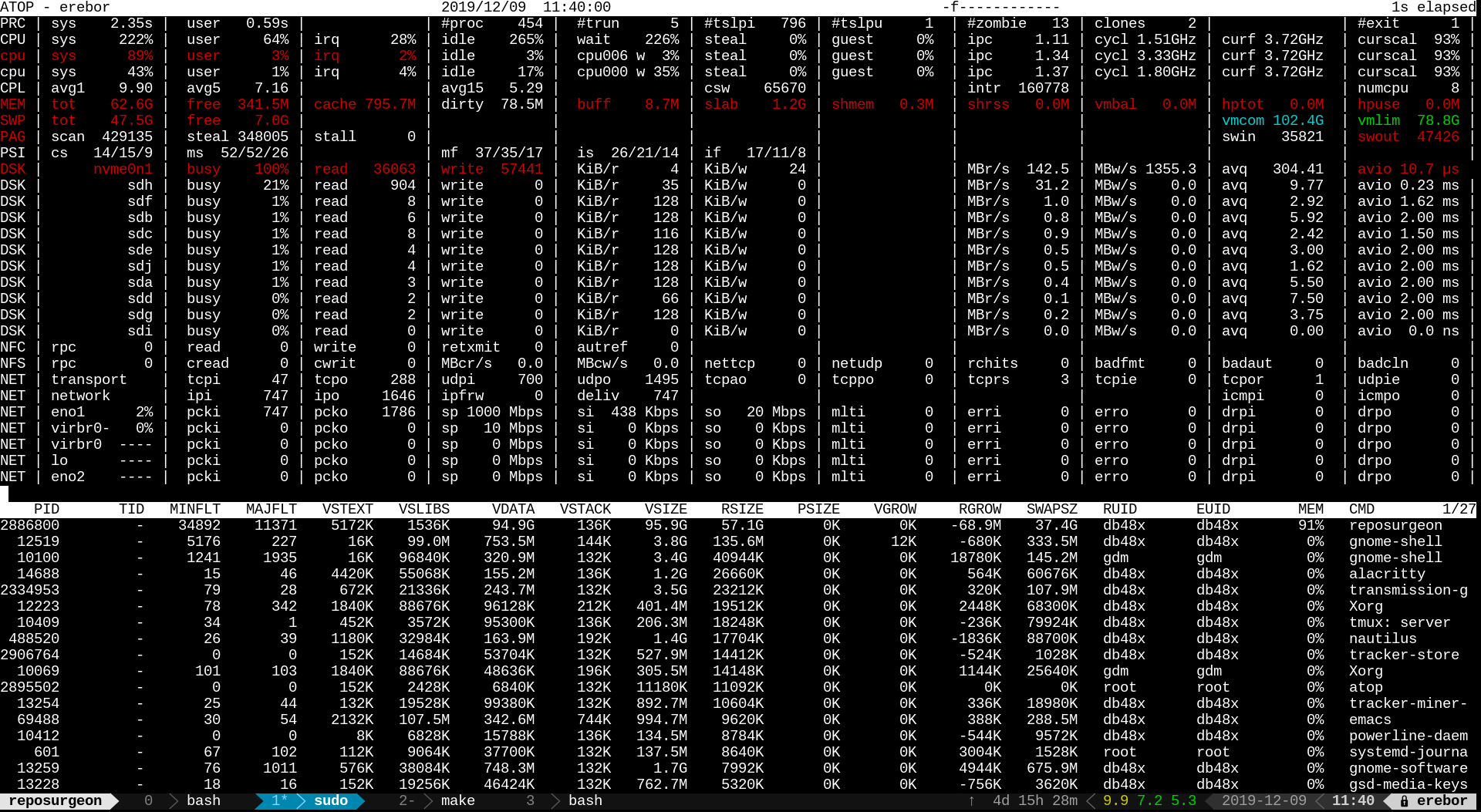{kind=link}