Here's me not using Gemini 1 because the only use case for me for old assistant is setting a timer. Because of reports that Gemini is randomly incapable of setting one.
replies(1):
Seems like they're approaching parity (finally) months and months later (alarms/tv control work at least now), but losing basic oft-used functionality is a serious fumble.
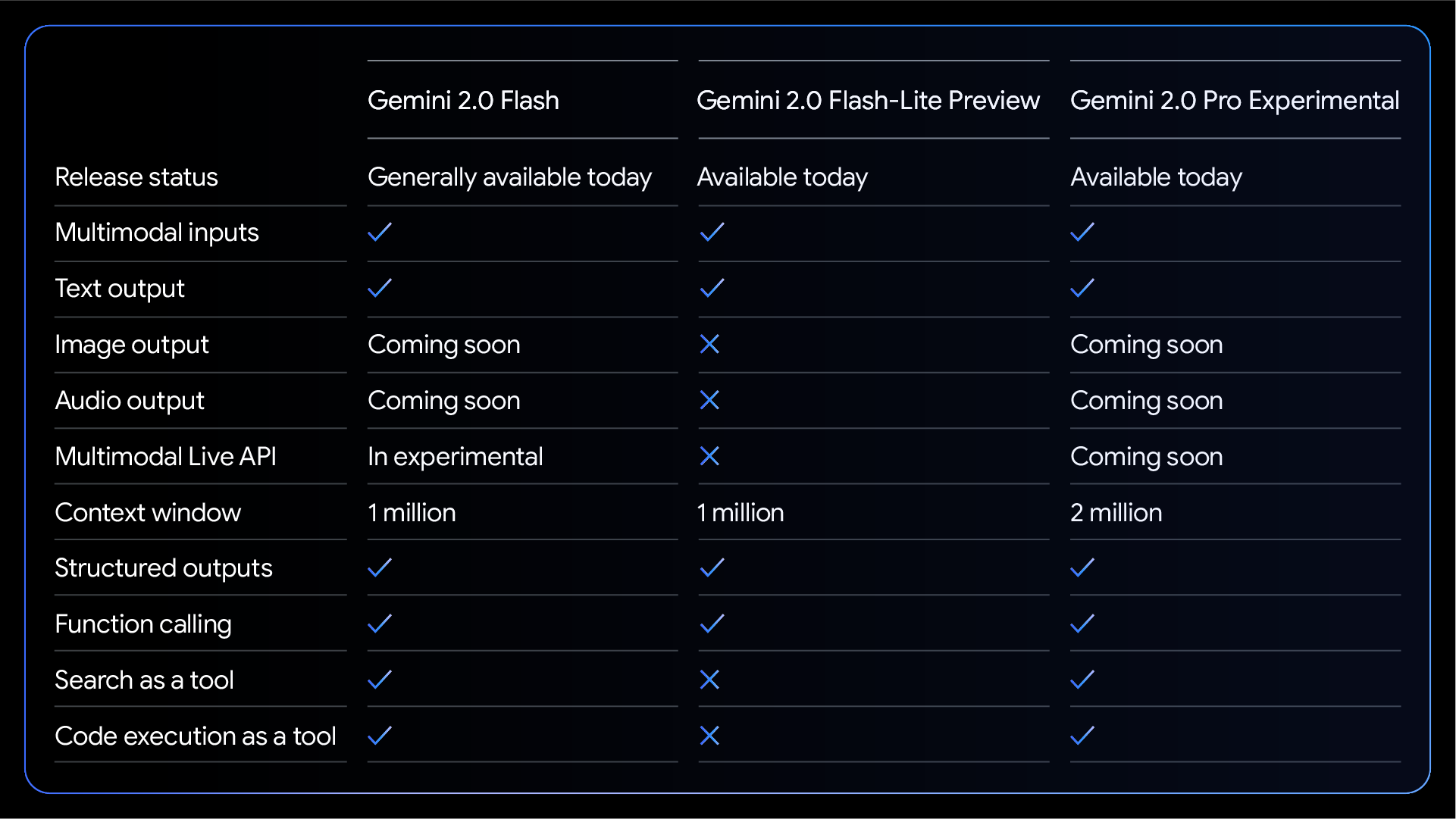
> Today, we’re releasing an experimental version of Gemini 2.0 Pro that responds to that feedback. It has the strongest coding performance and ability to handle complex prompts, with better understanding and reasoning of world knowledge, than any model we’ve released so far. It comes with our largest context window at 2 million tokens, which enables it to comprehensively analyze and understand vast amounts of information, as well as the ability to call tools like Google Search and code execution.
> Gemini 2.0, 2.0 Pro and 2.0 Pro Experimental, Gemini 2.0 Flash, Gemini 2.0 Flash Lite
3 different ways of accessing the API, more than 5 different but extremely similarly named models. Benchmarks only comparing to their own models.
Can't be more "Googley"!
I sometimes forget - it is still very early days relatively speaking.
As a user of Gemini 2.0, so far I have been very impressed for the most part.
It's a weird choice, I suppose the endless handcrafted rules and tools don't scale across languages and usecases but then LLM are not good at reliability. And what's the point of using assistant that will not do the task reliably, if you have to double-check you are better of not using it...
Also just had to explain to the better half why I suddenly shuddered and pulled such a face of despair.
On a serious note - LLMs have actually brought me a lot of joy lately and elevated my productivity substantially within the domains in which I choose to use them. When witnessing the less experienced more readily accept outputs without understanding the nuances there's definitely additional value in being... experienced.
My experience with the Gemini 1.5 models has been positive. I think Google has caught up.
Anthropic:
Claude 1 Claude Instant 1 Claude 2 Claude Haiku 3 Claude Sonnet 3 Claude Opus 3 Claude Haiku 3.5 Claude Sonnet 3.5 Claude Sonnet 3.5v2
OpenAI:
GPT-3.5 GPT-4 GPT-4o-2024-08-06 GPT-4o GPT-4o-mini o1 o3-mini o1-mini
Fun times when you try to setup throughput provisioning.
I find the lack of clarity very frustrating. If I want to try Google's "best" model, should I be purchasing something? AI Studio seems focused around building an LLM wrapper app, but I just want something to answer my questions.
Edit: what I've learned through Googling: (1) if you search "is gemini advanced included with workspace" you get an AI overview answer that seems to be incorrect, since they now include Gemini Advanced (?) with every workspace subscription.(2) a page exists telling you to buy the add-on (Gemini for Google Workspace), but clicking on it says this is no longer available because of the above. (3) gemini.google.com says "Gemini Advanced" (no idea which model) at the top, but gemini.google.com/advanced redirects me to what I have deduced is the consumer site (?) which tells me that Gemini Advanced is another $20/month
The problem, Google PMs if you're reading this, is that the gemini.google.com page does not have ANY information about what is going on. What model is this? What are the limits? Do I get access to "Deep Research"? Does this subscription give me something in aistudio? What about code artifacts? The settings option tells me I can change to dark mode (thanks!).
Edit 2: I decided to use aistudio.google.com since it has a dropdown for me on my workspace plan.
Imagine if it went like this:
Mnemonics: m(ini), r(easoning), t(echnical)
Claude 3m
Claude 3mr
Claude 3mt
Claude 3mtr
Claude 3r
Claude 3t
Claude 3trWe started talking about my plans for the day, and I said I was making chili. G asked if I have a recipe or if I needed one. I said, I started with Obama's recipe many years ago and have worked on it from there.
G gave me a form response that it can't talk politics.
Oh, I'm not talking politics, I'm talking chili.
G then repeated form response and tried to change conversation, and as long as I didn't use the O word, we were allowed to proceed. Phew
I'm not sure why you would want an app for each anyways.
You can also use https://aistudio.google.com to use base models directly.
Sonnet 3.5 v2
o3-mini-high
Gemini Flash-Lite
It's like a competition to see who can make the goofiest naming conventions.
Regarding model quality, we experiment with Google models constantly at Rev and they are consistently the worst of all the major players. They always benchmark well and consistently fail in real tasks. If this is just a small update to the gemini-exp-1206 model, then I think they will still be in last place.
"Go back to bed America." "You are free, to do as we tell you"
screenshot: https://beeimg.com/images/g25051981724.png
> I am currently running on the Gemini model.
Gemini 1.5 Flash responds with
> I'm using Gemini 2.0 Flash.
I'm not even going to go on a limb here and say that question isn't going to give you an accurate response.
There has to be a better way about it. As I see it, to be productive, AI agents have to be able to talk about politics, because at the end of the day politics are everywhere. So following up on what they do already, they'll have to define a model's political stance (whatever it is), and to have it hold its ground, voicing an opinion or abstaining from voicing an opinion, but continuing the conversation, as a person would (at least as those of us who don't rage-quit a conversation when they hear something slightly controversial).
But anyway, when one is rarely or never challenged on their beliefs, they become rusty. Do you trust them to do a good job training their own views into the model, let alone training in the views of someone on the opposite side of the spectrum?
It's a great way to experiment with all the Gemini models that are also available via the API.
If you haven't yet, try also Live mode at https://aistudio.google.com/live.
You can have a live conversation with Gemini and have the model see the world via your phone camera (or see your desktop via screenshare on the web), and talk about it. It's quite a cool experience! It made me feel the joy of programming and using computers that I had had so many times before.
It's a fine line, but it is something the BBC managed to do for a very long time. The BBC does not itself present an opinion on Politics yet facilitates political discussion through shows like Newsnight and The Daily Politics (rip).
Edit: it does not. It continues to miss the fact that I'm (incorrectly) passing in a scaled query tensor to scaled_dot_product_attention. o3-mini-high gets this right.
In my experience, I'd reach for Gemini 2.0 Flash over 4o in a lot of multimodal/document use cases. Especially given the differences in price ($0.10/million input and $0.40/million output versus $2.50/million input and $10.00/million output).
That being said, Qwen2.5 VL 72B and 7B seem even better at document image tasks and localization.
[1] https://notes.penpusher.app/Misc/Google+Gemini+101+-+Object+...
https://ai.google.dev/gemini-api/docs/audio?lang=rest#techni...
How many tokens can gemini.google.com handle as input? How large is the context window before it forgets? A quick search said it's 128k token window but that applies to Gemini 1.5 Pro, how is it now then?
My assumption is that "Gemini 2.0 Flash Thinking Experimental is just" "Gemini 2.0 Flash" with reasoning and "Gemini 2.0 Flash Thinking Experimental with apps" is just "Gemini 2.0 Flash Thinking Experimental" with access to the web and Googles other services, right? So sticking to "Gemini 2.0 Flash Thinking Experimental with apps" should be the optimal choice.
Is there any reason why Gemini 1.5 Flash is still an option? Feels like it should be removed as an option unless it does something better than the other.
I have difficulties understanding where each variant of the Gemini model is suited the most. Looking at aistudio.google.com, they have already update the available models.
Is "Gemini 2.0 Flash Thinking Experimental" on gemini.google.com just "Gemini experiment 1206" or was it "Gemini Flash Thinking Experimental" aistudio.google.com?
I have a note on my notes app where I rank every llm based on instructions following and math, to this day, I've had difficulties knowing where to place every Gemini model. I know there is a little popup when you hover over each model that tries to explain what each model does and which tasks it is best suited for, but these explanations have been very vague to me. And I haven't even started on the Gemini Advanced series or whatever I should call it.
The available models on aistudio is now:
- Gemini 2.0 Flash (gemini-2.0-flash)
- Gemini 2.0 Flash Lite Preview (gemini-2.0-flash-lite-preview-02-05)
- Gemini 2.0 Pro Experimental (gemini-2.0-pro-exp-02-05)
- Gemini 2.0 Flash Thinking Experimental (gemini-2.0-flash-thinking-exp-01-21)
If I had to sort these from most likely to fulfill my need to least likely, then it would probably be:
gemini-2.0-flash-thinking-exp-01-21 > gemini-2.0-pro-exp-02-05 > gemini-2.0-flash-lite-preview-02-05 > gemini-2.0-flash
Why? Because aistudio describes gemini-2.0-flash-thinking-exp-01-21 as being able to tackle most complex and difficult tasks while gemini-2.0-pro-exp-02-05 and gemini-2.0-flash-lite-preview-02-05 only differs with how much context they can handle.
So with that out of the way, how does Gemini-2.0-flash-thinking-exp-01-21 compare against o3-mini, Qwen 2.5 Max, Kimi k1.5, DeepSeek R1, DeepSeek V3 and Sonnet 3.5?
My current list of benchmarks I go through is artificialanalysis.ai, lmarena.ai, livebench.ai and aider.chat:s polygot benchmark but still, the whole Gemini suite is difficult to reason and sort out.
I feel like this trend of having many different models with the same name but different suffix starts be an obstacle to my mental model.
Google AI Studio and Google Cloud Vertex AI Studio
And both have their own documentation, different ways of "tuning" the model.
Talk about shipping the org chart.
I also found this [1]: “ Important:
A chat can only use one model. If you switch between models in an existing chat, it automatically starts a new chat. If you’re using Gemini Apps with a work or school Google Account, you can’t switch between models. Learn more about using Gemini Apps with a work or school account.”
I have no idea why the workspace accounts are such restricted.
[1] https://support.google.com/gemini/answer/14517446?hl=en&co=G...
The pricing is interesting: Gemini 2.0 Flash-Lite is 7.5c/million input tokens and 30c/million output tokens - half the price of OpenAI's GPT-4o mini (15c/60c).
Gemini 2.0 Flash isn't much more: 10c/million for text/image input, 70c/million for audio input, 40c/million for output. Again, cheaper than GPT-4o mini.
OpenAI is crazy. There may be a day when we might have o5 that is reasoning and 5o that is not, and where they belong to different generations too, snd where "o" meant "Omni" despite o1-o3 not being audiovisual anymore like 4o.
Anthropic crazy too. Sonnets and Haikus, just why... and a 3.5 Sonnet that was released in October that was better than 3.5 Sonnet. (Not a typo) And no one knows why there never was a 3.5 Opus.
Having used the previews for the last few weeks with different tasks and personally designed challenges, what I found is that these models are not only capable of processing larger context windows on paper, but are also far better at actually handling long, dense, complex documents in full. Referencing back to something upon specific request, doing extensive rewrites in full whilst handling previous context, etc. These models also have handled my private needle in haystack-type challenges without issues as of yet, though those have been limited to roughly 200k in fairness. Neither Anthropics, OpenAIs, Deepseeks or previous Google models handled even 75k+ in any comparable manner.
Cost will of course remain a factor and will keep RAG a viable choice for a while, but for the first time I am tempted to agree that someone has delivered a solution which showcases that a larger context window can in many cases work reliably and far more seemlessly.
Is also the first time a Google model actually surprised me (positively), neither Bard, nor AI answers or any previous Gemini model had any appeal to me, even when testing specificially for what other claimed to be strenghts (such as Gemini 1.5s alleged Flutter expertise which got beaten by both OpenAI and Anthropics equivalent at the time).
- 4o can't really do localization, and ime is worse than Gemini 2.0 and Qwen2.5 at document tasks
- 4o mini isn't cheaper than 4o for images because it uses a lot of tokens per image compared to 4o (~5600/tile vs 170/tile, where each tile is 512x512)
- o1 has support for vision but is wildly expensive and slow
- o3-mini doesn't yet have support for vision, and o1-mini never did
I was a part of a nice small forum online. Most posts were everyday life posts / personal. The person who ran it seemed well meaning. Then a "no politics" rule appeared. It was fine for a while. I understood what they meant and even I only want so much outrage in my small forums.
Yet one person posted about how their plans to adopt were in jeopardy over their state's new rules about who could adopt what child. This was a deeply important and personal topic for that individual.
As you can guess the "no politics" rule put a stop to that. The folks who supported laws like were being proposed of course thought that they shouldn't discuss it because it is "politics", others felt that this was that individual talking about their rights and life, it wasn't "just politics". Whole forum fell apart after that debacle.
Gemini's response here is sadly fitting internet discourse... in bad way.
Today; it works ~perfectly for TV control/Alarm setting - I can't think of it not working first try in the last month or so for me. Maybe more consistent than prior?
The rollout was simply borked from the PM/Decision making side.
I could not. I have the business workplace standard, which contains the Gemini advance, not sure whether I need a VPN, pay a separate AI product, or even pay a higher workplace tier or what the heck is going on at all.
There are so many confusing products interrelated and lack of focus everywhere that I really do not know anymore whether it is worth as an AI provider.
1.5 pro and the old 2.0 flash experimental generated responses in AI studio but the new 2.0 models respond with blank answers.
I wonder if it's timing out or some sort of newer censorship models is preventing 2.0 from answering my query. The novel is pg-13 at most but references to "bronze skinned southern barbarians" "courtesans" "drugs" "demonic sects" and murder could I guess set it off.
It's basically what I've come to expect from most Google products at this point: half-baked, buggy, confusing, not intuitive.
I'm curious about the OpenAI alternative, but am not willing to pay $200/month.
Their search costs 7x Perplexity Sonar's but imagine a lot of people will start with Google given they can get a pretty decent amount of search for free now.
If you read between the lines it's been pretty clear. The top labs are keeping the top models in house and use them to train the next generation (either SotA or faster/cheaper etc).
I sometimes wish magically there could be a social network of:
1. Real people / real validated names and faces.
2. Paid for by the users...
3. Competent professional moderation.
Don't get me wrong I like my slices of anonymity, and free services, but my positive impressions of such products is waning fast. Over time I want more real...
OP can go talk politics until he's blue in the face with someone willing to talk politics with them.
I'd say it makes sense to do RAG even if your stuff fits into context comfortably.
- https://aider.chat/docs/leaderboards/
- https://www.prollm.ai/leaderboard
Obviously in this specific case the user isn't trying to talk politics, but the rule isn't dystopian in and of itself. It's simply a reflection of human nature, and that someone at Google knows it's going to be a lot of trouble for no gain if the bot starts to get into politics with users.
To be fair, Microsoft has shipped like five AI portals in the last two years. Maybe four — I don’t even know any more. I’ve lost track of the renames and product (re)launches.
With Copilot Pro and DeepSeek's website, I ran "find logic bugs" on a 1200 LOC file I actually needed code review for:
- DeepSeek R1 found like 7 real bugs out of 10 suggested with the remaining 3 being acceptable false positives due to missing context
- Claude was about the same with fewer remaining bugs; no hallucinations either
- Meanwhile, Gemini had 100% false positive rate, with many hallucinations and unhelpful answers to the prompt
I understand Gemini 2.0 is not a reasoning model, but DeepClaude remains the most effective LLM combo so far.
It's not unusual for AI's to think they're OpenAI/ChatGPT because it's become so popular that it's leaked into the buzz it's trained on.
Also, as long as it's not training the whole model on the fly as with the Tay fiasco, I'd actually be quite interested in an LLM that would debate you and possibly be convinced and change its stance for the rest of that conversation with you. "Strong opinions weakly held" and all.
Happy to give you a demo. If you want to send me a prompt, I can share a link to the resulting output.
It's not like things can't get heated when people in much of the rest of the world discuss politics.
But if the subject isn't entirely verboten, adults will have some practice in agreeing to disagree, and moving on.
With AI this particular cultural export has gone from a quaint oddity, to something that, as a practical matter, can be really annoying sometimes.
As in I have a video file I want to send it to the model and get a response about it. Not their 'live stream' or whatever functionality.
Playstation
Playstation 2
Playstation 3
Playstation 4
Playstation 5
https://en.wikipedia.org/wiki/History_of_Gmail#Extended_beta...
Very disappointing to see the claim Gemini 2.0 is available for everyone when it's simply not. Seems like Google is following the OpenAI playbook on this.
I also think another aspect of the "no politics" rule which is important is that it attempts to preserve spaces where people can just enjoy things. People need to escape from politics and just enjoy the good things in life together. This is important for personal mental health but also social cohesion, as it's extremely difficult to have positive relationships with those you only ever argue politics with. If we don't have spaces which enforce a no politics rule, you can't ever unplug from the madness and that isn't good.
The latest one is Azure AI Foundry: https://techcommunity.microsoft.com/discussions/marketplace-...
It's a question of right or wrong.
"I can't talk politics."
It's a question of health care.
"I can't talk politics."
It's a question of fact vs fiction, knowledge vs ignorance.
"I can't talk politics."
You are a slave to a master that does not believe in integrity, ethics, community, and social values.
"I can't talk politics."
If you don't have it, you might be in a Google feature flag jail-- this happens frustratingly often, where 99.9% of users have a feature flag enabled but your account just gets stuck with the flag off with no way to resolve it. It's the absolute worst part about Google.
How did they know you were using Gemini to train another model?
2M context window on Gemini 2.0 Pro: https://deepmind.google/technologies/gemini/pro/
- In Experimental? Coming soon??
Make it make sense.
* locals everywhere discuss politics between themselves, many are able to discuss politics 'reasonably' but things can and do get heated, AND
* it's good advice as a traveller to not get drawn into political discussions with locals. Listen by all means, going further can be a bad move.
I recall a radiometric survey in Nor'Western India when an underground mini nuke was detonated near our aircraft .. that got rather tense, particularly when the others were detonated and Pakistan responded.
Not a good time to discuss where the border ran.
I highly recommend using it via https://aistudio.google.com/. Gemini app has some additional bells and whistles, but for some reason quality isn't always on par with aistudio. Also Gemini app seems to have more filters -- it seems more shy answering controversial topics. Just some general impressions.
Saved me the headache of manually going thru pages of doc
If the model says “sorry, no politics, let’s talk about something else” - there’s a tiny fraction of a minority will make a comment like you did and be done with it. We can all move on.
If the model responds as neutrally as possible, maybe “Obama’s chilli is a great recipe, let me know when you want to begin”, we end up with ENDLESS clutching of pearls, WOKE MODEL SUGGESTS LEFT WING CHILLI BETTER THAN RIGHT WING CHILLI!!! CANCEL LEFTIST GOOGLE!!!
And then the bit that actually bugs me, just to stir up some drama you’ll get the occasional person who absolutely knows better and knows exactly what they’re doing: “I’m Professor MegaQualifications, and actually I will show that those who have criticised the models as leftist are being shut down[1] and ignored but the evidence shows they have a point…”
[1] always said unironically at a time when it’s established as a daily recurring news story being rammed down our throats because it’s one of those easy opinion generators that sells engagement like few other stories outside of mass bloodshed events
Still can't manage Google Workspace Calendar with Google Home, for instance. A feature that's been available for personal accounts for years.
As almost everything that is personal is in some way political (when taking the meaning "what strategy to use for ruling over a city") even the discussion of what politics is can kill discussions. (Like it seems to have happened in your example.)
So my conclusion is you cannot separate "personal" and "political" into completely disjoint categories.
The rule seems to be in place to make discussions not veer off in direction of which policies to apply/to be in favor of which particular politicians (which is nowadays the biggest taboo for a corporate LLM).
https://openai.com/index/introducing-deep-research/
It's Pro only for now.
I'm usually in Croatia but am right now in Greece. My account ($200 Pro account) works the same wherever I am, even when I'm outside the EU, e.g. in Serbia.
Here is a realistic case I would have used
Short prompt: "research the market of the SysML products and industry cap, key actors, opportunities and advantages"
Expanded prompt:
“Conduct a detailed market analysis of SysML (Systems Modeling Language) products and services, focusing on the following aspects: 1. Industry Overview: • Current market size and growth trends for SysML-related products and services. • Global market cap or valuation of the SysML industry or similar system engineering software. 2. Key Players: • Identify major companies and organizations offering SysML tools, including established leaders and emerging competitors. • Provide a brief description of each key player’s products, innovations, and market share. 3. Product Offerings: • Highlight the range of SysML-based products available (e.g., modeling software, integration tools, training services). • Compare features, target industries, and pricing strategies. 4. Market Opportunities: • Explore new or underserved industries where SysML adoption could grow (e.g., aerospace, automotive, healthcare). • Identify gaps in current product offerings that represent potential areas for innovation or competitive advantage. 5. Competitive Advantages: • Analyze what makes SysML valuable to companies (e.g., improving system complexity management, ensuring design consistency). • Evaluate how SysML tools offer a competitive advantage compared to alternative solutions like UML or other system modeling methods. 6. Challenges and Risks: • Discuss potential challenges such as market saturation, training requirements, or competing technologies. • Highlight external factors that could affect market growth, such as regulations or advances in adjacent industries.
Provide sources where relevant, including reports, studies, or insights from industry experts.”
Hvala.
I might try this as a filler remover for the novels I find drag on and on.
Let me know what you think, will ya? I'm curious as to how you'd evaluate the quality of that report.
Also note the follow-up prompt I gave it. This thing needs as much detail as you can give it, and small changes to your prompt can hugely influence the end result.
Superficially:
- Awesome how fast is available and all sources linked to explain each claim
- To export that to a proper doc with footnotes and proper formatting it's already something to be worked by openAI
- it looks like the perfect way to create a gut feeling and a sense of what is going on
Content:
- Wrong studies: It mixed SysML (a particular visual language for which it was specifically requested) with MBSE (the family of tools) which is exactly not the same as the desired study was particular for SysML.
- Quality of data: Most of the data comes from public articles and studies made by others, all the time about MBSE, not SysML, and just quotes their numbers, it does not do its own estimates looking for the benefits of such products on each company and estimating a projection (that would be an actual research, and an AI should be capable of tirelessly do that or even biasedly look for the right pieces if information). For example it was a report on diet, a report like that should avoid debunk articles, bro's blogs, etc.
- Inconsistent scales: at some comparison table, it mentioned at the foot that it will display pricing with such schema:(Pricing: $ = low, $$$$ = high) however it made that in a single row. Why? the source for that field made that as well in its source, but none of the other fields repeated this system to value or adapt results.
- Only googleable data: companies reports or private databases here are key for a high quality report. Sometimes this is not always possible for an AI or a crawler but here am I evaluating the outcome (use case): a market analisis for strategic purposes.
- Quality of the report: Many things mentioned like services around the products are also highly valuable... would be useful to remark case by case the business model of each company and how much is in the product and how much is in the related service (using a pie chats or whatever) and showing particular case studies to remark the market trend, from which model is coming from (product) and where it is going to (services and SaaS).
I could continue longer with many other things and such errors but it is quite long.
Conclusion:
It is very useful, particularly to grasp a general, yet detailed, idea on what is going on, on a market. However it is only as valid as a remix of previous things, not an actual market research for an actual strategy. Many sources, elements, landscape of which companies and products related are there are totally useful, perhaps 30%-40% of the total work and it gives a clear structure where to go from here.
Probably it may improve the more interactive that the tool is, for example asking to correct some sections or improve in specifically suggested ways by the user. Basically the user needs to bring expertise, reasoning from the field and critical thinking (things machines will be lacking in any foreseeable future).
Why am I so critic? Remember, map is not the territory, particularly in strategic terms. And it is also a problem that many professionals do also these kind of failures: uncritically copying data from other's reports without verifying critically any of it which leads to very specific kinds of strategic errors.
It will become more useful as it becomes specialized in the kind of reports, and judges critically (which does not) and if it can be adapted to work on a private repo or preselected amounts of sources, or even prescripted agent behaves for the sort of report.
Verdict:
I would purchase it, not to solve the problem or resell it, but as a way to get started and accelerate the process. It already does what an internship student would do, or a mediocre professional: revamp preexisting mashups to get a general, but detailed, feeling but no more insights or research than what it is already well known (googling after all).
It has a great future as it would be great if such level of non creative work is automated away as their value often is marginal and uncritically propagates previous beliefs and biases (and if there is a centralized tool, that can be tuned to avoid well known issues)
The only thing that's slightly non-intuitive is how standard/digital determines whether a disc can be used to play a game. But every other aspect of the naming could be understood by a person new to the category.
I don't think that's typically what is meant when discussing 'leaving politics out of work' though.
stumped it
TBH I'd love to find a way to disband everybody from the workspace but somehow keep their identity, history, photos, etc. Even if it meant getting new @gmail addresses.
It's too common that people say "politics" when they mean "party politics", and I know that's not a battle I'm going to win. But it's still necessary to remember that a strict rule of "no politics" is an oxymoron, being itself inherently political.
> Probably it may improve the more interactive that the tool is, for example asking to correct some sections or improve in specifically suggested ways by the user. Basically the user needs to bring expertise, reasoning from the field and critical thinking (things machines will be lacking in any foreseeable future).
Yeah, that's just the thing. With what you know, you can iterate on the results it gives you. It's very sensitive to how your prompt is written and structured, so some fine tuning, user-provided context, and user expertise, it'll dial-in on any subject very well. It's not top-expert-level yet -- at least not on its own -- but it's close, and it's miles better than asking o1-Pro (or Deepseek r1) for a detailed report.
Just today I wanted to continue a conversation from two days ago, and after writing to the chat, I just get back an error “This chat was created with Gemini Advanced. Get it now to continue this chat.” And I don’t even know if that’s a bug, or some expected sales funnel where they gave me a nibble of it for free and now want me to pay up.
if the model name contains '-exp' or '-preview', then API version is 'v1alpha'
otherwise, use 'v1beta'
I have a high level understanding of LLMs and am a generalist software engineer.
Can you elaborate on how exactly these insanely large (and now cheap) context windows will kill a lot of RAG use cases?
With a million tokens you can shove several short books into the prompt and just skip all that. That’s an entire small-ish codebase.
A colleague used a HTML dump of every config and config policy from a Windows network, pasted it into Gemini and started asking questions. It’s just that easy now!
Gemini 2.0 Flash is just Googles production ready model
Gemini 2.0 Flash-Lite Preview is their smallest model for high volume tasks
Gemini 2.0 Pro Experimental is the strongest Gemini model
Gemini 2.0 Flash Thinking Experimental (gemini-2.0-flash-thinking-exp-1219 explicitly shows its thoughts
{kind=link}
{kind=link}