Curious what “home servers” are really for. I’ve gone decades without needing a home server — what am I missing out on?
replies(12):
I don't want to spend time meticulously configuring things beyond the core infrastructure my services run on. I should probably explore FreeBSD more, but honestly, with containers being everywhere now, I'm not seeing a compelling reason to bother. I realize jails are a valid analogue, but broadly speaking the UX is not the same.
All this being said, I have this romantic draw to FreeBSD and want to play around with it more. But every time I set up a basic box I feel teleported back to 2007.
Are there any fun lab projects, posts, educational series targeted at FreeBSD?
I can’t think of any change that has improved my Linux sysadmin experience more than the move to systemd.
Is it complicated? Perhaps it is. But this FUD about it being resource intensive or unreliable or difficult to use is complete nonsense.
And on top of that systemd isn’t even “Linux.” Plenty of popular production-ready distros like Alpine Linux don’t even use it.
And of course I’m not saying FreeBSD is bad, but I’m not the one writing and publishing an article bashing a system I don’t understand.
systemd-as-init-replacement was probably fine. systemd-as-kitchen-sink can get annoying.
I also use it from my other computers via ssh to access git, irc, keepass, and whatever else tickles my fancy.
If "kubesomething" is the reason, there's no requirement to use it. I think most people don't run it on their home servers.
If containers are the reason, then again, they are not a requirement. But they are pretty similar to BSD's jails. I don't think they are particularly complex.
FreeBSD has a number of strong suits: ZFS, a different kernel and network stack, a cohesive system from a small(ish) team of authors, the handbook, etc. But the usual Linux hobgoblins listed above are a red herring here, to my mind.
In my experience, systemd is far better and more reliable than anything else, especially if you need complex logic (ex: when this and that happen, start doing this, except when such and such are present)
Most of the problems I've seen come from trying to duplicate systemd functions: in the author example, why bother with rsyslog or network-manager?
I have also seen many people refusing to learn modern tools, instead trying to make it work with the tools they know, by disabling what works better, often with poor results.
It's like trying to keep using ifconfig and route instead of ip: you can make it work, but for say managing multiple ip on the same interface forces you to go with eth0:0 eth0:1 etc (and let's not even talk about network namespaces).
I like the various BSD and distributions like postmarket OS, but I wish they had access to modern tools instead of having to "roll my own" with scripts or make do with what they depend on
This is why I use FreeBSD as well for my home server, first class ZFS support out of the box. Void Linux musl on my desktop.
I had an old 2TB ZFS array that was part of a trunas setup kicking around for years. I needed to recover some files from it so I hooked all the disks to a motherboard and booted FreeBSD live. I didn't have to do anything, the array was already up and running when I logged in. ezpz.
The only truly bad systemd-* I've worked with is systemd-journald. Which often fails to contain log entries that should be present or simply just corrupts itself.
An always-on machine to handle recurring tasks (remote backups, say).
Maybe a VPN gateway (you can also just use an AppleTV for that, though, with Tailscale)
Home automation if HomeKit isn't your thing, for whatever reason.
Network-wide adblocking, custom DNS, et c.
You really, really don't need one. But they can be nice.
Also some people just like tinkering. Can't relate (any more) but I've got my thing down to requiring single-digit hours per year.
[EDIT] Of course, part of how I avoid making it more work is that I don't upgrade the core OS, since it has minimal exposure to public networks and everything I care about comes from Docker so IDGAF how old the package collection is. Especially with ZFS in play, upgrades are... fraught. At some point whatever old-ass Debian I have on there will be too old and I'll have to, IDK, image the whole base OS disk as a backup and spend probably a whole weekend screwing with it when it inevitably breaks itself on upgrade. I may just migrate to FreeBSD instead, when the time comes.
For all those things you really shouldn't trust "the cloud"
Absolutely
> If containers are the reason, then again, they are not a requirement. But they are pretty similar to BSD's jails. I don't think they are particularly complex.
The only point I agree with the author is that many things are shipped to be used with docker when they don't need to be, which creates a needless dependency.
Klara Systems [0], Vermaden [1] and IT Notes [2] seems to be the most active and popular.
- [0] https://klarasystems.com/articles/
Docker's just a package manager and process manager, the way I use it, and has performed flawlessly in that role.
OTOH when you compare it to e.g. OpenBSD (or in many instances, even Linux), it's an actual mess. The default install leaves you browsing thru the handbook to get simple things to work; it has three (three!) distinct firewalls; the split between /usr/local/etc and /etc constantly leaves you guessing where to find a particular config file; even the tiny things such as some default sysctl value being an XML snippet - actually, WTF?
The desktop story is also pretty bad. OpenBSD asks you during installation, whether you'd like to use X11 - and that's it. You boot to XDM, you get a basic window manager, things like volume buttons just work, all in the base system - no packages, no config files. You can install Gnome or XFCE from there, and rest assured you'll always have a working fallback. FreeBSD still feels like 90's Linux in that area. Regarding usability, both are behind Linux in things like connecting to Wifi networks, but in OpenBSD's case you just save a list of SSIDs/passwords in a text file, and the kernel does the rest for you.
The author is praising jails. I think it's nice that you can trace the lineage all the way back to 6.x, it sings a song of stability. You can also put each jail on a separate ZFS dataset to get snapshot/restore, cloning, etc. But I think it's still a poor middle ground between OpenBSD and OCI. OpenBSD keeps making steps (privsep, pledge, unveil) to provide isolation, while remaining conceptually simple for the developer and imposing no extra maintenance burden on the operator. Containers by design are declarative, separate the system image from state, etc - it's a wholly different concept for someone used to e.g. managing stateful jails or VMs, but it reinforces what already were good design principles.
Isn't it just that /etc is the base OS and /usr/local is all packages added on top?
It sounds like you wish they used systemd. "Modern" is rarely a good description, and at 15 years old I don't think systemd qualifies as such anyways.
You sat that as though its a bad thing! The author values simplicity.
> I notice FreeBSD admins tend to follow a 'pets not cattle' approach, carefully nurturing individual systems. Linux admins like myself typically prefer the 'cattle not pets' mindset—using infrastructure-as-code where if a server dies, no problem, just spin up another one. Leverage containers. Statelessness.
Is it less work to write that code and manage "pet"? Are there other advantages?
I think you probably are right about the preferred approach - but what are the advantages of each?
> Statelessness
What about data storage?
I push data from my home server for easy access on my cloud VM. For example, weather data from my weather station, images/time-lapses from my weather cam. I have no ports open to my home network. Basically just fun stuff without exposing my home network.
I use the cloud VM as an SSH "jump box" into my home network. My OpenBSD box sets up a remote SSH tunnel port. I can then use the SSH -J option to jump through the cloud VM into that home OpenBSD box (as well as chain "jumps" to other home servers).
* This way I don't need any home server to trust a cloud VM.
* This mostly is for checking on my Home Assistant instance.
* I've also fixed some things remotely with an SSH session.
Maybe in the past there was an argument for that, but ever since FreeBSD started using OpenZFS implementation...what's the difference?
My ideal OS would be something like NixOS, but on FreeBSD and with better language than Nix.
https://www.schneier.com/blog/archives/2022/08/security-and-...
The article is directly talking about mass-produced electronic commodities. The same is even more so for bits where the cost of copying is not merely "low" as in microcontrollers, but essentially free.
In my opinion, systemd does solve a lot of problems, at a cost of somewhat more complexity and resource utilization. But it is the nature of material culture to complexify with time as more physical resources become available, i.e., "progress". More advanced commodities don't come out of a thin air of "better processes", but processes that interweave with other parts of the economy more intimately given the previously produced commodities. Something similar can be true inside the computer.
In fact I think even that thing is still to complicated. We need one-click deploys, automatic updaters for Linux or FreeBsd or similar for regular people to be able to self host and own their data.
Having local pizzeria hosting its menu on Facebook is not a good thing. Having an online only calendar app as an only way to schedule haircut locally is not good thing. Having all your files stored on OneDrive or GoogleDrive is not a good thing.
If author thinks FreeBsd is better - cool. Then work on a solution for ordinary people to host file storage server using FreeBsd in a simple way.
Create simple wizard to install Nextcloud or Owncloud or mail sever on FreeBsd.
This post is true but it is just a rant that do not solves any real problems. One if them is that people do not want to manage servers. For better or worse - is beside the point.
But instead it also does NTP, DHCP/networking, logging, etc. There were some very annoying teething issues with a lot of these components. It became more difficult to isolate problems buried within the systemd stack. It also became a pain to do some common, basic tasks. When the first distros starting supporting it, getting the systemd/journald logs for all the services into a central logging service was extremely painful. With (r)syslog it is just one line in a config. Heck, even the config files for systemd are littered all over the place.
It didn't help that the systemd head (Lennart Poettering) was extremely intransigent with any complaints, often outright refusing to deal with various historical edge cases for long-established norms.
And yes, by doing all this it the broke the long-held UNIX philosophy of "do one thing really well" and that continues to ruffle a lot of feathers. I've mainly accepted the fact that it won out, but it's helped by the fact that I'm now mostly using it to start a docker orchestrator and that all the networking is now handled by cloud-computing resources.
RedHat the main powerhouse behind Linux ans is now owned by IBM. And Ubuntu is just corporate Debian who pushes their own proprietary (Flatpak) software which is cobbled together and just generally sucks.
Systemd is bloated in wanting to do everything at once. I have never had a linux systemd distribution that just shutdowns without prompting me "waiting x/2minutes - x/y retries".
FreeBSD is my daily driver and will always be my primary. Once you get over the "eww it's bsd" linux snobbery you start to realise how solid it actually is.
Wifi works, graphics work. Wine and Proton works. Ports is fantastic and kernel compiling is easy. It even works on my MSI 2024 laptop. [1]
Linux is lost in a communistic maze of leap frog.
Each has its own strengths, but I choose FreeBSD for home servers (shared file/media server. and network gateway), for a few specific reasons:
- ZFS (on root, fully integrated tooling for jails, etc)
- More consistency/less churn in base system (great for set-and-forget systems)
- Ports/pkg (still better than any Linux pkg manager)Lack of community resource such as documents, blogs, StackOverflow answers and docker ecosystem just drove me away from BSD as I lose nothing by using Linux. The only thing I miss could be OpenBSD’s pf.
Syncthing is a great use case. Wherever I take my laptop, the files stay in sync between the two devices; I don't need a third device to act as a server, or iCloud, or any other cloud.
Miniflux. I read my RSS feeds from three devices, so I want to track read status and save bookmarks. It provides a Google Reader-compatible API (yes it lives on), so I can plug NetNewsWire into it.
It's an exit node for Tailscale. Did I mention Tailscale? It's like still being on the same LAN anywhere you go. It doesn't matter if your home server doesn't have a public IP.
Grafana is cool for anything you can plot, as long as you can mash it into something vaguely resembling a time series. Sensor readings, data pulled from some API, CSV export from your bank, your chess ELO, etc. It's often combined with Prometheus. So you can also scrape anything that speaks enough HTTP (which is... many things, these days).
I want to explore something like Navidrome or Jellyfin; for now I use Syncthing for my music library, but even if I could run it on iPhone, the whole collection wouldn't fit. Unfortunately it seems there are no decent apps.
You're also free to explore uncharted territory. Rubenerd is hosting a "house-wide" SQL database: <https://rubenerd.com/our-personal-database/>
I do.
> "Modern" is rarely a good description
Then call it reliable and dependable.
Modern doesn't always win for me: I prefer vim to neovim, or bash to zsh. Having a solid set of features and a good integration does.
If you are curious, see https://marcelofern.com/posts/linux/goodbye_zsh/index.html which mirrors my reasons to prefer bash
I remember when Ubuntu and docker each entered the scene and my initial impressions of both were pretty negative.
Currently, I don't have any issue at all, and I'm not aware of any either.
I like how it's very reliable and integrated: the "kitchen sink mentality" can have positive effects
> It didn't help that the systemd head (Lennart Poettering) was extremely intransigent with any complaints, often outright refusing to deal with various historical edge cases for long-established norms.
In retrospect, given how well it all works, maybe he was right to refuse to compromise.
If you wanna run your own init solution you can but it might be a bit of effort, embedded people often do this while a system like a desktop with dbus and display servers and IPC left and right might standardize on systemd
One of the reasons I prefer NetBSD (and the BSDs in general) is that they don't change gratuitously. The ifconfig / ip example you use is good: Why? If we look at the reasoning given, it was that they didn't want to make big changes to ifconfig, so they made a whole new set of commands, even though the BSDs have extended ifconfig many times.
So that ends up meaning that how-tos just don't work any more. Imagine if you want to write a how-to these days where you're telling people how to do something using standard ifconfig and now also need to add ip. This is how you do DNS on standard Unix(like) systems, and now you have to explain multiple iterations of systemd. This is how you add software, but now you need to have separate instructions for apt, yum, dpkg.
Having administered Ubuntu for others, even going from version 18 to 20 or 22 means that how-tos no longer work, scripts need to be modified, systemd handling has to be updated, et cetera.
This is why I will always choose a BSD if given a chance. Pointing to a less messy Linux (like Void because it doesn't use systemd) isn't good enough when clean, well thought out systems already exist.
For instance, DNS handling and NTP keep coming up over and over, and it's almost becoming a meme. Why? Because it's the Microsoft mentality - we (the systemd people) know better than you (you're just the machine's owner and administrator), and we'll take care of this. You want to? Not without a fight.
So no, it's not FUD when reasonable people can't give reasonable answers for how to do something that's otherwise reasonably simple.
I like BSDs for the integration and the performance.
> So that ends up meaning that how-tos just don't work any more
Complexity (or change) doesn't come out of nowhere: sometimes, new tools must be learned.
> isn't good enough when clean, well thought out systems already exist.
I also love well thought out systems, but I think systemd is one of these "well thought out" systems.
I started with FreeBSD and it never was a problem to me until I started to use Linux too. Now I just make symlinks from /usr/local/etc to /etc for software I use both on Linux and FreeBSD. The rule is simple - if an app is from the base system it is in /etc and if you installed some software from packages (ports) then configs will be in /usr/local/etc.
> This is of course not an easy task, one of the main blockers we found as we collaborate more closely with KDE and GNOME developers is that they have a hard time with our OpenRC-based stack. In order to get KDE Plasma and GNOME working at all, we use a lot of systemd polyfills on top of OpenRC.
But I know that once it's fixed, it will work well, so it's motivating me to give a hand
With Linux there’s been many times I’ll google some problem and the only solution that turns up is for distro Y which is mostly or entirely irrelevant to distro X that I’m running at the moment. This happens even with the big mainstream distros like Ubuntu and Fedora, but of course it’s worse with more niche ones.
* UrBackup for all of the host systems in the home to backup to
* Plex for home movies
* HomeAssistant
* OpenThread Border Router
* Zigbee2MQTT
* Matter Server
* PostgreSQL (for HA)
* InfluxDB (for long term statistics from HA)
* EMHASS (linear optimizer to maximise profit on my Solar PV + Battery system)
* Minecraft server for the kids
* Mosquitto MQTT broker
* TeslaMate for car data
In my case, the heaviest use is HomeAssistant - every light in the house has smarts, either directly, or through smart relays. Telling my energy provider how much charge to add to the EV's so they schedule it and I only pay 7p per kWh during the dispatching windows. Managing energy flow in the house (charge battery? discharge battery? only charge battery from solar that would otherwise be curtailed due to a 5kW export limit) etc. etc.
It's running in a short depth 2U rackmount chassis inside my network rack, with 6 4TB drives running in RaidZ2 and offsite backups which are aided by a 1Gbps symmetric FTTP connection.
The only salient point in this entire article is that BSD typically is less convoluted as a system (and as a consequence... usually less capable and less supported).
I find absolutely all of the other points to be "easy cop outs". They're there to provide him a mental justification for doing the thing he wants to do anyways, without actually justifying his logic or challenging any assumptions.
---
Case in point - I used to point all (most of) my hosted services at a single database. It genuinely sucked. It's a larger backup, it's a larger restore, if it goes down everything is down, and you better hope all the software you're hosting supports your preferred DB (hah - they won't, half will use postgres, half will use mysql, and half of the mysql half will actually be using mariadb, and I'm ignoring the annoying group that won't properly support a networked db at all and don't understand why I'm frustrated they only support sqlite).
You know the only thing it was actually doing for me? Marginally simplifying deployment, usually at first time setup.
You know what else the author of this post is trashing? Some pretty good tools for simplifying deployments.
Turns out... if spinning up a database is 3-10 lines in a config file, and automatic backups are super simple to configure with your deployment tool (see - all those k8s things he's bashing)... You don't even feel this pain at all.
---
Basically - This is a lazy argument.
Perfectly fine personal preference (I also sometimes enjoy the simplicity of my freeBSD machines, and I run opnsense for a reason).
But a trash argument against the things he's railing against.
Switching to k3s and running kubernetes was a a pretty giant time sink to get online (think maybe 25 hours) - but since it's come online... I've never had an easier time managing my home services.
Deployment is SO fucking simple, no one machine going down takes any service down, I get automatic backups, easy storage monitoring (longhorn and NAS), I can configure easy policies to reboot services, or manage their lifecycles, I can provision another machine for the cluster in under 10 minutes, and then it just works (including GPU accelerated workloads).
These days... It's been so long since I've ssh'd into some of my machines that I occasionally have to think for a minute before I remember the hostname.
I don't think about most of them AT ALL - they just fucking work (tm).
I remember the before times - personally, I don't want to go back. It's never been easier to run your own cloud - I currently have 112 online pods across 37 services. I don't restart jack shit on my own - the system runs itself.
Everything from video streaming to LLM inference to simple wikis and bookstack.
I've worked at 'pets not cattle' and 'cattle not pets', and I vastly prefer pets. Yes, you should be able to easily bring up a new pet when you need to; yes, it must be ok if pet1 goes away, never to be seen again. But no, it's not really ok when your servers have an average lifetime of 30 days. It's very hard to offer a stable service on an unstable substrate. Automatic recovery makes sense in some cases, but if the system stops working, there's a problem that needs to be addressed when possible.
> All this being said, I have this romantic draw to FreeBSD and want to play around with it more. But every time I set up a basic box I feel teleported back to 2007.
Like another poster mentioned; this is actually a good thing. FreeBSD respects your investment in knowledge; everything you learned in 2007 still works, and most likely will continue to work. You won't need to learn a new firewall tool every decade, whichever of the three firewalls you like will keep working. You don't need to learn a new tool to configure interfaces, ifconfig will keep working. You don't need to learn a new tool to get network statistics, netstat will keep working. Etc.
I can install a relatively minimal Linux server (usually Ubuntu Server), disable snaps, install Docker community, copy my app directories (with docker-compose.yaml files in each) and `docker compose up -d` in each directory and be (back) up in moments. When I was trying a couple different hosts for mail delivery, the DNS changes took longer than server setup and copy/migration. It was pretty great.
It's also lead me to a point where I'm pretty happy or unhappy with given applications by how hard or easy a compose file for the app and it's dependencies are. Even if, like my mail server, the whole host is effectively for a single stack.
No, I'm not running more complex setups like Kubernetes or even Swarm... I'm just running apps mostly at home and on my hosted server. It's been pretty great for personal use.
For work, yeah, apps will be deployed via k8s. The main projects I'm on are slated for migration from deployed windows apps, mostly under IIS or Windows Services, to Linux/Docker.
Wifi not being available isn't the fault of FreeBSD. If vendors actually gave open sourced drivers to their products and not locked behind a proprietary binary blob then we would be in a completely different world.
I can recall when WiFi on Linux was pretty much non-existent until deals were made back in 2018.
So stop throwing that this is FreeBSDs fault, it's 100% down to the vendors locking down hardware.
On FreeBSD, ifconfig works fine for having multiple addresses on the same interface (and has since like forever?? I had multiple addresses on the same interface in 2004, and it's documented in the FreeBSD 1.0 man page) and it also manages configuration for wireless interfaces too. There's no need for new tools when there is already an appropriate tool that can be updated to do the job. Keeping the existing tools working means you don't need to retrain users and you don't need to update documentation that doesn't touch the new use cases.
It should be below (without the extra “i”):
The whole cattle mindset because at the end of the day everything is a "unstable substrate" your building a stable service on unstable blocks pets don't solve the issue that each pet is fundamentally unstable and your just pretending it's not.
But.
Having tried to move a machine from rhel 5 to rhel 7, where 12 people had used the server over the past 8 years for any scripting/log analysis/automation, for hosting a bespoke python web request site and a team-specific dokuwiki... The idea of having all that in source control and CICD is alluring.
No. Just because it's available doesn't mean it's good. Until FreeBSD supports modern Wifi (4/5, i.e 802.11n/ac) then you're just ticking the box to say you've got it, but Linux actually supports these modern network setups and FreeBSD does not. There is no debating this at this point in time.
And to be clear, I'm referencing wifibox (https://github.com/pgj/freebsd-wifibox) which has been written about extensively and exists to work around FreeBSDs well known poor wifi support.
> So stop throwing that this is FreeBSDs fault
Nope, it's on FreeBSD if they want it. They appear to have finally prioritized it but it's not there yet.
https://freebsdfoundation.org/blog/january-2025-laptop-suppo...
resolved, timesyncd, homed, journald, networkd (was very happy with Debian's interfaces(5)). Never thought of mounting file systems as process control, so also add mounting and taking over fstab. Given the ever-growing number of 'sub-systems', I'm sure new ones have been created that I'm not aware of. (I'm personally most regularly annoyed by resolved, especially as a server sysadmin where I need DNS to be deterministic, and not clever: I've gotten to the point of doing a chattr +i /etc/resolv.conf.)
I'm waiting for a systemd-mail so Zawinski's Law can be fulfilled:
* https://en.wikipedia.org/wiki/Jamie_Zawinski#Zawinski's_Law
> For me, I bring network up in initramfs, so it's definitely part of my init.
I've run Solaris, IRIX, BSD, and 1990s Linux, and I've never thought of networking as related to process control (init).
That's not the way the world has to be. You can have a network that is rock solid. You can have power that is rock solid. You can have hardware that is rock solid.
Sure, if you have a couple thousand machines, a few of them will have hardware problems every year. Yes, once in a while an automatic transfer switch will fail and you'll have a large data center outage. Backhoes exist. Urgent kernel fixes happen. You have to acknowledge failures happen and plan for them, but you should also work to minimize failures, which I honestly haven't seen at the 'cattle not pets' workplaces. Cattle take about two years to get to market [1] (1.5 years before these people receive them, then 180 days before sending them to market); I'd be fine with expecting my servers to run for two years before replacement (and you know, rotating in new servers throughout, maybe swapping out 1/8th of the servers every quarter, etc), but after running for 30 days at 'cattle not pets', I started getting complaints that my systems were running for too long.
[1] https://cultivateconnections.org/how-do-you-determine-when-t...
Nobody says you can't do CI/CD with pets too. You do have to keep the pets well groomed, of course.
- Kavita and Jellyfin to self-host my books, comics, movies and TV. Self hosting is particularly important for non-Hollywood/non-US-centric media which routinely disappears from the internet.
- A custom webapp to self-host my photos (if I did it again today I'd use Immich)
- Gitea to self-host a few Git repos
- A GPU so I can use it remotely to offload AI/ML workloads from my laptop
It is networked with my ither devices via Tailscale so me, my friends and family can access it from everywhere. It is like having a private Netflix, Kindle, Google Photos and Comixology/MangaReader that allows any media to be downloaded to read offline.
I also have second Windows server used for hosting dedicated servers for video games.
Is that true? All you need is one bad mosfet and all the other components fine, zero reliability. Doesn't a M x N matrix with only one extreme value average out from many samples over time?
I couldn't agree more.
Its a testament that this s/w is _still_ NOT LIKED by so many people.
I've been a linux on the desktop, FreeBSD for the server user/admin for over 20 years.
It's a great combination...
I've recently switched my FreeBSD setups to use that scheme, and it's been nice. Would be interested to hear if it's similarly straightforward on Debian (my second-favorite OS :)
Obviously requires support in the bootcode; I'm not sure of the state of that for Linux.
This is a myth. The 787 has about 60 million miles of wiring in it. It is vastly more complicated than an airliner from the 1940s, and it also much, much safer. Poorly engineered technology fails, not necessarily complex technology
> secondary problem is the stacking of abstraction layers docker / kubersomething
Then don't use Kubernetes or Docker? They aren't mandatory
If you treat a server as a "pet", then you typically run multiple services through a service runner (systemd, runit, openrc, etc.) and do only a moderate amount of communication between servers. Here you treat the server as your scheduling substrate upon which your units of compute, services, run. In a "cattle" system, each server is interchangable and you run some isolated service, usually a container, on each of your servers. Here the unit of compute is a container and the compute substrate is the cluster, multiple servers.
In a "pets" system managing many servers is fraught and in a "cattle" system managing many clusters is fraught. So it's simply the abstraction level you want to work at. If you're at the level where your workload fits easily on a single server, or maybe a couple servers, then a pets-like system works fine. If you see the need to horizontally scale then a cattle-like system is what you need. There's a practical problem right now in that containerization ecosystems are usually heavy enough that it takes advanced tools (like bubblewrap or firejail) to isolate your services on a single service which offers the edge to cattle-like systems.
In my experience, many smaller services with non-critical uptime requirements can run just fine on a single server, maybe just moving the data store externally so that failure of the service and failure of the data store are independent.
the arch wiki is VERY comprehensive, linux has a huge community, and arch forced you to understand much just by stepping through the installation process.
Bash and zsh are approximately to same age. I think bash is older by only a few months.
While I can't comment on using it for root, I can say for other use, the only annoyance I have is compiling the kernel module on every single update. This is automatically handled by APT, but for very small servers it can be slow... at most ~15 mins. Could be solved with private distribution for a large fleet but I can't be bother with that stuff. Hoping at some point Debian will relax their strict "to the letter of the GPL" attitude at some point like they did with install media drivers. But it's not the worst experience, at least installing is automated.
`ifconfig` just works, like it has worked for 20 years. On my linux servers, it's all swallowed into `ip addr` now. I don't mind that, I certainly understand why these things change, but when I update an Ubuntu server I always worry that next time I log in a tool I am used to will be broken or removed.
I simply don't have those concerns on FreeBSD.
I know the project is smaller in scope and has less funding than Linux (distros and subprojects included) but it's kind of ridiculous. It's incredibly frustrating to set aside the time to set up a machine only to have the kernel panic half way through booting the install media.
From there it's an annoying and exhausting yak shaving exercise just trying to get the machine to start. Eventually I just give up and put the latest Ubuntu LTS which boots and installs with no problems. I import my ZFS pool and everything just hum along.
I cut my Unix teeth on FreeBSD 3 and 4. I want to use modern FreeBSD but it never seems to run on hardware I actually own. That's why I don't run FreeBSD on my home servers.
I'm on the opposite camp. If FreeBSD can provide a systemd-like service and device management software, then I would switch to it.
I totally get avoiding systemd, I don't myself, but I get it. The author on the other hand talks about the problems doing this in a professional setting. This I do not get. As far as management of large fleets of servers goes, systemd is quite nice. Yeah, it's odd for some things but as far as automation is concerned it's the way to go.
With systemd the same file syntax and management works for services, timers, mount points, networking, name resolution, lightweight containers, virtual machines. You literally have to write one parser and serialize to ini. Then you get distribution generic management. Upgrades? No problem? Moving to CentOS to Debian? Ubuntu? arch? Whatever? No problem. It. Just. Works.
Yeah, if you're in the know you can do better for specific circumstances, but in this day and age OS's are throw away and automation you don't have to refactor is paramount. For professional work, this flame war is over.
Also nice way to recover zfs if anything goes wrong. yea, it's a linux image for just booting. But you put it as an EFI image, and works great.
There is no "syntax", it's all just key=value pairs, and all the subsystems have their own set of keys/directives, and the values have their own mini-DSLs. Things that end in "Sec" (for "seconds") take duration labels. The only directives that are shared is the inter-unit dependency directives. Some keys/directives can be specified multiple times.
I don't know why you'd be parsing unit files or serializing something else to unit files. Just drop them into place. The hard part is knowing all the details of how the directives interact and what their values can be.
On top of the things you mentioned, it’s basically impossible to produce a working playbook that switches from Ubuntu’s garbage package to the upstream ones - systemd wedges badly about 25% of the time, and force disables the zfs units. None of the documented systemd overrides worked.
I’m enjoying devuan and openbsd at home.
I have pretty much every server running from web server to mail server and I don't spend "a few hours" per YEAR to keep it running. about once a week I run a pkg update, pkg upgrade and service x reload in each jail to update the software and 99.9% of the time it works smoothly.It really doesn't get much simpler than that. This could also be done with cron like in your example, but I don't think automating updates is such a great idea. I think updates should be monitored.
I have a lot of confidence in the nginx/postfix/dovecot/etc developers ability to develop professional software.
FWIW I am also not a sysadmin.
Regarding your example with "eth0:0" Is not how you do things in FreeBSD. There is no "eth0" at all.
You use ifconfig xy0 alias. https://man.freebsd.org/cgi/man.cgi?query=ifconfig&apropos=0...
Something nicer than nix would be nice, but otherwise perhaps keep an eye on https://github.com/nixos-bsd/nixbsd
> actual man pages
The jail system has it's warts and at times can seem a little unpolished, but alt least I know that the workarounds and automation I have set up for my home server is mostly "done".
The license is "compatible" enough to be shipped by distributions rather than kernel.
AFAIK, the thing is: no one has seriously decided to test the license compatibility (as in, test it in court) and everybody's essentially scared of Oracle dragging them through endless legal litigation. Oracle owns most/all the IP that came from Sun Microsystems and while ZFS/OpenZFS is CDDL licensed... Who wants to spend millions in legal fees to find out?
Canonical did (still does?) ship OpenZFS with Ubuntu but maybe they're not big enough for Oracle to go after them (who knows? the lawnmower works in misterious ways).
There are people in the FreeBSD camp that actually do advocate for something like systemd in FreeBSD. See "The Tragedy of systemd": https://www.youtube.com/watch?v=o_AIw9bGogo
The way I see it, other init systems had 20 years to come up with a reliable model, but they didn't, and as is usual in FOSS, whoever actually writes the damn thing, decides how it looks.
What I meant is that dockerizing your applications (which author of article seems to have a problem with) is easier from that point of view. There is no need to provide a package for each distribution or OS you want to support. You can bundle all the necessary dependencies if there are any (like i.e. databases which author provide as an example of unnecessary redundancy). There are solutions for web managing docker containers and stacks like Portainer, Taisun, Yacht and probably more I am not aware of. You have Watchtower and Diun for update notifications. So it is simpler for developers and partially for an user.
Maybe there are similar solutions for FreeBsd package manager, but this is only for FreeBsd. With docker it should work on every environment that can run docker. So again it is simpler.
You can run your services without docker and sometimes it is easier without it (i.e. running DLNA server) still, I would not want to run my email server as nginx/postfix/dovecot/sogo/mysql as separate services that I need to separately install, configure and update. There are dockerized solutions for that that exists already that you can start and run with docker + some DNS config. It is just easier.
If you are fine with your stack on FreeBsd it is totally fine, but there is a reason why less, or non-technical people are running commercial NAS devices like Synology. Because it is easier. And there is a reason why non-technical people are using Google Drive and iCloud for their needs like files sync, backups and email instead of running their own mail server and NAS: because it is easier.
So I do not have anything against FreeBsd and their native packages. But you wrote yourself:
> about once a week I run a pkg update, pkg upgrade and service x reload in each jail to update the software and 99.9% of the time it works smoothly. It really doesn't get much simpler than that.
Yes it does: web or phone app management. Why you have an app for every silly smart devices people are buying (like i.e. smart fridge or smart dishwasher)? Because it is easier for ordinary people. Samsung and LG do not make CLI for those to manage those devices via SSH. Maybe it would be even easier, once you are familiar with that, but people are not. Try to explain your hairdresser or plumber what is FreeBsd, pkg, jails and services.
> This could also be done with cron like in your example, but I don't think automating updates is such a great idea. I think updates should be monitored.
Which is exactly why I wrote that I, personally, do not want to spend few hours every week to upgrade and monitor upgrade process of all my devices. Especially since those are used by my family and I do not want to update them during a day, because they will be complaining that they can't use something. And I do not want to do that at night because I want to sleep. I you have nice solution for running 10 or 20 applications on FreeBsd, with very easy and quick update and backup process for them, please write about it. My solution takes about 2 hours every day for 4 devices and about 6 hours of update and backup - every day. But sending about of 2TB of data backups (even incremental) must take some time.
So, again, I agree with an author with few points but in an essence, I do not agree. I does not matter if you use FreeBsd, or Ubuntu or Debian or UnRaid for your self hosting needs. We need simpler solutions for self hosting for ordinary people.
With the switch of TrueNAS to Linux, I have no more BSD at home, unfortunately.
Are you really sure?
systemd is a tool that automates system configuration with no interaction from the user, and it does it in such a way that the user doesn't have to know how the system works, then the user doesn't want to know, and then no longer actually knows.
When that happens, the user can't make any political decisions about his/her system, the "system" account gets to have higher privileges than "Administrator", the user is no longer the owner of the OS, can't control what the system does, not even what it does with his/her personal data, and finally we all turn into uneducated mindless drones. Oh, wait, we're already there. How did that happen?
Great for company computers ; very bad for users.
My NAS is an eight core server with 64GB ECC ram running a ZFS pool with 8 12TB WD Red Pro drives for storing my collection of curated Linux ISOs, running TrueNAS SCALE, running always-on services inside containers:
- PostgreSQL for a bunch of personal project databases
- TeslaMate collecting data from our EVs into the PostgreSQL database
- Plex for serving up media to the Apple TV
- Tailscale exit node so I can access my home network on the go
- Step CA for managing my personal certificate authority used to issue everything I want to have TLS for with a certificate easily (LetsEncrypt doesn’t work for private network servers)
- Tarsnap for periodically backing up all data, documents and configuration I really do not want to lose
- UniFi controller managing my UniFi APs (four of them)
I’m sure I will have more use cases in the future, but it’s really handy to have always running infrastructure and storage at home you can rely on!
And I don’t spend much time tinkering with it now that it’s set up, it’s just maintenance mode.
From time to time I adjust a few configs or upgrade a hardware component here and there but it’s been stable like this for years (apart from the TrueNAS CORE to SCALE migration which was a bit of a shitshow due to moving from FreeBSD to Linux, had to rebuild all jails into Docker containers).
I personally wrote several of them :)
FreeBSD is an extremely simple and stable system. All packages/ports for which are tailored to integrate well with the networking stack, logging etc of FreeBSD. FreeBSD has daily/weekly/monthly cronjobs per default that runs a number of cleanup tasks and security updates and emails the result. It also has email setup correctly per default.
And FreeBSD only gets a few patch updates a year and a new major release every two years. The security patches it will download for you and then inform you over email.
ArchLinux needs constant maintenance to be updated, often requiring manual intervention. The packages are unchanged from upstream and thus do not integrate that well will the system at all, often requiring much more configuration. ArchLinux can be run as a server, and I have an do for years now, but it isn't made for it and it does require attention. ArchLinux is about getting bleeding edge software packaged as-is from upstream, and it's about allowing the user to tinker and customize. In that sense FreeBSD and ArchLinux can be considered opposites.
- I can make /usr read-only, exclude it from backups, put it on an NFS share, or otherwise treat it as immutable during normal operation;
- I can nuke /usr/local any time, fall back on the base system, and reinstall packages from there;
- I can put /etc in version control and track all configuration changes;
- I don't need to think whether to look for /etc/nginx or /usr/local/etc/nginx, this also simplifies automation like scripts or Ansible roles; etc
Notably, OpenBSD takes the effort to ensure all packages install their configs in /etc.
The more components you add a component into to a defined system (excepted for redundancy purpose), the higher the probability of failure.
This is exactly why Toyota provides tier A car in term of reliabily and majority of European / US car full of failures by adding a lot of useless gadget.
If aynthing Linux is an outlier in that core OS components and 3rd party apps both come in similar packages which makes it hard to distinguish which is a part of the base OS and which and optional 3rd party software. In FreeBSD I know that I can delete all packages and still have a system remotely accessible via SSH (with rare exception a normal user will not come across). In Linux to tell which package can be uninstalled without breaking the system one have to be an expert. Can I delete iproute package if I don't use ip command, can I remove NetworkManager, is systemd-container optional? Where the OS stops and 3rd party apps start?
This, with the sections, is INI. Duplicate keys included. Loosely defined spec, but INI none the less
> I don't know why you'd be parsing unit files or serializing something else to unit files. Just drop them into place
It's common to store information in a DB, or some other format that is easy to merge/override programmatically. Even configuration management tools like puppet, salt, ansible do this with JSON/YAML
Holy smokes, that's quite biased!
Good on the author for having strong beliefs, but in my eyes containers avoid entire categories of problems, like: https://blog.kronis.dev/user/pages/blog/oracle-jdk-and-openj... (request processing times for a random system at work ages ago under load tests, it ran passably in OpenJDK, whereas running with the Oracle JDK resulted in an order of magnitude worse performance, this was before containers were introduced in the project; guess which vendor's version was installed in prod without telling us about it)
It was an old post, but sometimes there's configurations that do break in mysterious ways when the dependencies and the runtime environments aren't matched exactly to what was developed/tested against; see the whole reproducible software movement, can have good install scripts and other tools to help even without containers, but good luck managing the support matrix of a bunch of separate *nix distros and OSes, as well as having testing environments for those. Not even that much of an enterprise concern.
We shouldn't need containers for everything, but there aren't that many other good options for packaging software.
> There is a new fashion on the OpenSource world. Developpers think Docker is the new de-facto standard and only propose to install the tools with Docker.
It shouldn't be the only way, but I'll take Docker over random shell scripts and the ability to easily launch software and then later tear it down without messing up my host OS or having to mess around with VMs. Tbh, I do kind of wish that Vagrant had caught on more.
> Most of the time they do no provide any DOCUMENTATION to install their software in a baremetal way.
> At best, they offer an .rpm or .deb package for installation on a non-docker OS. But most of the time it's a docker file.
The Dockerfile is more or less living documentation, which is better than having a source code repo with nothing but obviously worse than someone taking the time of the day to write some guides or docs. Then again, if it's FOSS devs, then I'll take anything over nothing, given how much time they (don't) have.
> Even worse, modern applications often deploy the code and database needed to run the code directly in the docker compose file.
Deploying DBs or even multiple separate apps within a single container is pretty much an anti-pattern (anyone who has needed to decipher what happens inside of a GitLab Omnibus image, or update the Sonatype Nexus image from the embedded OrientDB to PostgreSQL probably understands the pain) and should be avoided, maybe save for rare cases like a web server with PHP-FPM (maybe with supervisord) if you really need to, or for the lazy/testing setups that will ultimately be a mess to maintain.
Edit: however if the complaint is literally just about having a Docker Compose file which contains a self-contained DB container, then it's up to you to decide whether you want or don't want to use it, or reference another DB running on the host or elsewhere (e.g. host.docker.internal or equivalent). It doesn't take much work to comment out a block.
> At what point did these people think it was relevant to run 10 different databases when I'm hosting 10 applications ?
You don't have to. You could have a single PostgreSQL or MariaDB/MySQL instance that just has multiple users and DBs/schemas. I honestly prefer the more distributed setup because I now can move software across servers trivially and can update the versions as I please and when something misbehaves, the impact is limited (because you can set CPU/RAM limits, easier than with cgroups).
Good for the author for enjoying FreeBSD, it's a pretty cool OS and feels more like it's "designed" instead of the more organic feel of how Linux distros work.
But I reject the motionally charged language and stance.
I don't think not knowing all of what systemd does will turn Linux users into mindless drones and it's quite dismissive to take that stance, these are users that chose another OS for their out of their own free will.
How does a particular distribution handle its man pages is up to that distribution. You can browse what is generally considered to be the "standard" set of man pages online: <https://man7.org/linux/man-pages/> or <https://linux.die.net/man/>, but this is a third-party community effort. I've often found minor discrepancies between those resources and what I actually found installed on my system.
Debian does an absolutely amazing job: every executable in every package has to come with a man page, and if there isn't one, the maintainers will at least write a synopsis. You can also read these man pages online: <https://manpages.debian.org>; you get to browse by release, section, you even get translations. Some derivatives (e.g. Ubuntu) will provide their own online browser as well.
But this is where things start to get dicey. Most distributions make heavy use of GNU coreutils, glibc, GCC, etc. Some of these (like GCC) are complex, because the problem domain is complex. On the other hand, coreutils' level of unnecessary complexity is almost byzantine; to cope with that, the GNU project mostly abandoned man pages (these mostly just contain a synopsis) in favour of an in-house "info" system <https://www.gnu.org/software/texinfo/manual/info-stnd/info-s...>, which is basically TeX <https://tug.org> with layers on top.
But not all distros use GNU tools nowadays; e.g. Alpine (actually pretty popular, thanks to the Docker ecosystem) uses busybox and musl libc. However for some reason Alpine not only does not provide an online man page browser, but requires installing a meta-package to add the man pages to your system. The differences between GNU and busybox+musl are non-trivial (and not unlike GNU vs BSD).
You can blame the Linux ecosystem fragmentation, and you would be correct to point out there are three popular BSDs, each with its own goals and little quirks. My final point is about the quality of the documentation. Compare coreutils chmod(1) <https://linux.die.net/man/1/chmod> and OpenBSD chmod(1) <https://man.openbsd.org/chmod.1>. The former is a brief, dense, and intimidating wall of text that expects you to immediately grasp what "ugoa" or "rwxXst" stand for; you will only find out that the tool manages file access permissions once you dig through the third paragraph; the text concludes by referring you to "info coreutils aqchmod invocationaq". By contrast, OpenBSD's man page has a clear introduction, then paces you through explaining the basic; goes into detail over the octal and symbolic representations (with pretty tables); warns you about a common mistake; has several examples with explanations (including equivalences between octal and symbolic forms); and concludes by referring you to the POSIX standards.
Best of it, you can expect the same high standard of quality throughout the entire base system, from user commands to device drivers and kernel internals.
Many people don't. When something more complex and integrated works it can seem perfectly fine. When something more complex and integrated fails, it often has more cascading effects that would otherwise be desired.
> In retrospect, given how well it all works, maybe he was right to refuse to compromise.
systemd's timesyncd is less accurate than ntpd and is terrible at dealing with drift; it is mostly only suitable for desktop timesyncing. As soon as you need to deal with synchronous timing with multiple machines, it's usually the number one problem. Even worse is that it doesn't tend to use less memory or cpu than alternatives.
systemd's DHCP client continues to be a nightmare for people using it with many ISPs or corporate networks due to the creators deciding to only handle one format of optional headers (in particular option 43, but also many others) resulting in networking issues in many situations. These issues are long-historical and can even be due to ancient endian issues. Every other DHCP client implementation deals with this - except systemd's. I have to cleanup my ec2 instances because systemd's dhcp client adds 032 instead of a space to resolv.conf's search field because we have more than one domain there.
In some cases these problems are because of long-established practices that technically violate an RFC. In others it's because they refuse to deal with more than one legit way of doing things. Either way, what is a service/process manager doing in this fight?
When you replace something that's been around for decades (init), you're going to ruffle feathers for good and bad reasons. It's had decades of maturity. But now one is going to do it for dozens of services and not appreciate or handle the nuances that come with such a responsibility? It's literally pure arrogance - hence the hate.
Most people use Open ZFS which is from the Illumos project, which was basically the escape hatch that the engineers who wrote ZFS used when Oracle tried to close source Solaris after the Sun acquisition. There are decades of improvements in all of the OSS versions that comprise Illumos (which Oracle has denied themselves by attempting to close source it, since they cannot feed off of downstream OSS code). i.e most of the people who wrote ZFS immediately left Oracle and worked on Open ZFS.
Open ZFS is for both FreeBSD and Linux, and is what most people are referring to when discussing ZFS. I've never used Oracle ZFS and never will.
It is a cohesive whole which can be read from start to finish (it is an actual book). This is also how the whole system feels as well (as others have commented). Things are integrated and coherent. Example: freebsd has its own libc[0], and the kernel and libc do feel (from old experience) like a consistent unit, so to speak.
So IMO in terms of system cohesiveness (and its documentation which is a marvel unto itself but also represents the thing it covers), it's on a whole other level.
[not even using FreeBSD for any servers right now[1], but I have deep respect and admiration for the project and its team]
https://docs.freebsd.org/en/books/handbook/
[0] that's the thing, as others have commented, Linux is really two parts (GNU+Linux) whereas e.g. FreeBSD is for most intents and purposes "one" internally cohesive part.
[1] though about to get a large old refurbished Dell server with 2xXeon for personal tinkering (you can find them cheap; beware of power usage tho...) and will likely set up FreeBSD as host, with ZFS, etc...
For time sync, what you do depends on what you need: there's a long list of option: rdate, sntp, ntp, ptp and I have used all of them.
Even if rdate is technically obsolete, for embedded systems it's sufficient that the time is not grossly wrong (and it's faster to write a rdate client and server)
However, when I'm doing high precision sampling data with multiple computers and I have to reorder the observations, sub microsecond accuracy is not enough: then I use PTP with a GPS and PPS (or chrony with special NICs if I can't get a GPS signal)
Both of these are very far from the normal needs of linux installs: there is no one size fits all, there are even interesting inbetween (chrony doing hardware timestamping with ntp is very clever) but when you design a system, you have to make choices.
> But now one is going to do it for dozens of services and not appreciate or handle the nuances that come with such a responsibility? It's literally pure arrogance - hence the hate.
I'm very happy systemd exists, because I like the well thought out design it has created: I can feel how it's lacking in the BSD.
I understand systemd success was not a given, and choices had to made. I just don't think it was arrogance, but compromises needed to achieve a vision.
> it's because they refuse to deal with more than one legit way of doing things. Either way, what is a service/process manager doing in this fight?
It's making choices.
Maybe systemd could have used ntp or better (maybe it will? or maybe there's a reason it's a bad idea?) but it does most things extremely well: if I have very specific needs (ex: ptp) far outside the norm, I can concentrate on that and let systemd do everything else far better than I would.
> these problems are because of long-established practices that technically violate an RFC
For DHCP, you should suggest an update, and if it gets adopted, a patch to make systemd follow the updated RFC.
That would show some love, and it might be better (and more productive) than the hate
The only issue I've had with the kernel module aspect is VPS configuration, I use Linode and they used to automatically set everything to use the hypervisor kernel, but the kernel module is obviously built against the versions installed on your OS and these will probably be different.
All you have to do is make sure the boot configuration is set to use GRUB if using a VPS. Linode seem to have switched to this by default for Debian now.
OpenZFS released 2.3.1 a few weeks ago: https://github.com/openzfs/zfs/releases It has direct support for FreeBSD and Linux.
macOS, Windows and other ports work great, but are not (yet) upstream: https://openzfs.org/wiki/Distributions
Actually, there is.
https://web.git.kernel.org/pub/scm/docs/man-pages/man-pages....
It's included with many default distro installs.
There's other stuff like eliminating boot interactivity, so you can't hit ctrl-c or any other keys to cancel waiting for dhcp on network ports that aren't plugged in, that really bother me.
I also don't think a FreeBSD init/system supervision system would go and re-implement dns, ntp, and whatever else, including redoing security mistakes from decades ago.
"Mindless drones" is probably a little harsh - I usually reserve that for mobile phone/tablet users.
There were choices/options, some of which have existed for decades. Instead of replacing them, systemd could have provided optional or mandatory services (eg time, dhcp, etc) that could be passed into systemd. "NTP is enabled and provides time, so it gets started at this point in the dependency tree"...or "NTP with priority 1, chrony with priority 2 provide time, start NTP and if it fails, switch to chrony". This also means that systemd could lag if successor protocols for time syncing, etc take off.
Millisecond or less time syncing is not outside the norm for distributed tracing or other server-side tech stacks, especially if there's lots of traffic. I've been lucky in that AWS's modern underlying hardware seems to keep clock pretty well, meaning I've not had to personally fight with it (that and ubuntu already defaulted to chrony, doing the override work for me.), but I do know people doing on-prem kubernetes loads that have had to...
Swinging back to networking, the tight integration with systemd makes (made? I am only now starting to plan the upgrade of our ubuntu 20.04 fleet to 24.04, so maybe it is better now...) disabling components a huge pain in the ass. My initial fights with systemd's dependency management meant that disabling its internal DHCP had several cascading consequences with other things that expected networking to be "up". This is to say nothing of the tooling that expects a full-slate of systemd services.
> For DHCP, you should suggest an update, and if it gets adopted, a patch to make systemd follow the updated RFC.
It's not mainly an issue with strict adherence to RFCs. There's quite bluntly real-world usage and industry norms.
Firstly RFCs can be vague and unclear. IPSEC is a notorious example in that vendors treat the IP restriction headers differently because the spec is nebulous to how precisely it should work (some call it a proxy-id or proxy-header, others subnet range, etc). Due to a variety of reasons that can be summed up as the consequences of committee driven design, a lot of the spec was defined with great "flexibility" in mind. Some vendors will not bring up the tunnel unless both ends agree on the ranges exactly. Others will happily bring up the tunnel, but only allow traffic that overlaps within the local restrictions. Even more infuriatingly, some vendors (cisco in particular) tie it to the firewall rules, which could include other non-vpn traffic. Some (like checkpoint) dynamically supernet the configured entries. The result is every person who's setup IPSEC VPN tunnels with third parties maintains a "quirks" record to understand how best to bring up tunnels between vendors (eg juniper srx to cisco ASA, juniper srx to palo alto, etc). You just cannot be stubborn here. You need to work with the way the real world works.
Secondly, there can be competing standards or necessary migration paths between them. I'm not sure what the IPv6 status is on systemd so this is only an example, but IPv6's autoconfiguration didn't initially include DNS and other optionally useful fields, meaning DHCPv6 was a thing. This is now mostly deprecated by SLAAC, but DHCPv6 deployments will be needed for awhile as it's all that windows' IPv6 implementation supported until recently. You can't just say "RFC now supports SLAAC...don't whine to me that DHCPv6 doesn't work as it's not part of the RFC".
> That would show some love, and it might be better (and more productive) than the hate
People have tried, but the response can be TL;DR'd to "works on my machine/setup" or to go harass AWS, Microsoft (via AD), etc to make things work the way the systemd mainainers think is right. There's a reason Lennart Poettering has a "difficult" reputation.
I think using the description "mindless drone" for someone using a device is better left off this and any HN communication as I assume 99% of readers use a mobile phone daily.
There isn't anything specific that ifconfig can do that "ip" doesn't -- except I have 20 years of muscle memory for ifconfig and zero for "ip". That's my frustration. When I'm at home, just trying to set up Plex or debug a networking issue, and all I need to do is get my current IP address, the last thing I want to do is spend time learning a new interface that isn't necessary.
Again, this isn't really a complaint about the tools - I'm sure that "ip" is great and has more features and etc. But hosting on Linux feels like this about everything. Logs, services, networking, user configuration - the management tools for all these things have been changing quite fast, and in ways that can be hard to follow.
I'm not on the Kernel or Debian mailing lists and I don't think I should need to be to understand how to configure the network on ubuntu 20.04 vs 18.04. When I need to look up user management on BSD, I just look at the handbook. It's up-to-date and informative. Meanwhile in the Linux world these things change so fast that wiki articles from 2 years ago are often useless.
If sntp is not sufficient for your needs, just disable systemd own sntp solution (systemctl disable...) and use chrony (systemctl start / systemctl enable to make it persistent): then `systemctl status systemd-timesyncd.service` will show you it has been disabled
> but I do know people doing on-prem kubernetes loads that have had to...
What did they have to do? `systemctl disable systemd-timesyncd` is not very complicated. If they want to create a service, they can have it disable timesyncd iff chrony has started successfully (in an ExecStartPost), or doing a logic chain.
It's extremely practical: you can create very precise logic chains with systemd (if this and that, then...)
> My initial fights with systemd's dependency management meant that disabling its internal DHCP had several cascading consequences with other things that expected networking to be "up". This is to say nothing of the tooling that expects a full-slate of systemd services.
Maybe I can help you with that - I used to run a non systemd DHCP when I needed a rapid DHCP to reduce the TTFB for a specific configuration (read https://news.ycombinator.com/item?id=2755461 if you are not familiar with rapid DHCP)
It did not require much effort, just "inserting" my own service in the dependency chain.
Create a /etc/systemd/system/my-dhcpcd@.service with : (put the right option for your dhcp in execstart)
```
[Unit]
Description=dhcpcd on %I
Wants=network.target
Before=network.target
BindsTo=sys-subsystem-net-devices-%i.device
After=sys-subsystem-net-devices-%i.device
[Service]
Type=forking
ExecStart=/usr/bin/dhcpcd -q -w %I
ExecStop=/usr/bin/dhcpcd -x %I
ExecStop=/usr/sbin/ip addr flush dev %I
[Install]
WantedBy=multi-user.target
```
Using the @ syntax, you can create a dhcp just for the one interface you care about: then use systemctl daemon-reload, and start your custom service as my-dhcpd@eth1 : the %i will be replaced by eth1
If you are interested in rapid dhcp, I give more details on https://www.reddit.com/r/archlinux/comments/1392wrc/dhcpcd_1...
> I am only now starting to plan the upgrade of our ubuntu 20.04 fleet to 24.04, so maybe it is better now...
It shouldn't be very hard to fix, I had a similar setup working with a 18.04 and a 20.04
> My initial fights with systemd's dependency management meant that disabling its internal DHCP had several cascading consequences with other things that expected networking to be "up". This is to say nothing of the tooling that expects a full-slate of systemd services.
You need to insert yourself in the dependencies, but the example I gave above should be sufficient to do that
> This is now mostly deprecated by SLAAC, but DHCPv6 deployments will be needed for awhile as it's all that windows' IPv6 implementation supported until recently. You can't just say "RFC now supports SLAAC...don't whine to me that DHCPv6 doesn't work as it's not part of the RFC".
I have maintained such solutions and I had both SLAAC and DHCPv6: giving multiple IPv6 to an host is fine. On linux side, you can even use preferred_lft to change the priority (ex: use 0 to have an IPv6 address that will reply to connections, but that will not be used to initiate connections, for example if you don't want to expose "easy to remember" short addresses like yourprefix:subnet::1
In case you don't know, systemd-networkd IPv6AcceptRA is a separate option (and section) from DHCPv4 and DHCPv6 - you could decide to use either or both, and also do more advanced routing with RouteMetric to prefer one over the other if you have different gateways for redundancy
If what I've explained is not clear, try to read https://wiki.archlinux.org/title/Systemd-networkd it's a good starting guide.
If you have more advanced IPv6 needs, it's usually to request a /56: use PrefixDelegationHint
You can then chunk it out with systemd: check https://major.io/p/dhcpv6-prefix-delegation-with-systemd-net... for a nice guide
> People have tried, but the response can be TL;DR'd to "works on my machine/setup" or to go harass AWS, Microsoft (via AD), etc to make things work the way the systemd mainainers think is right.
Everything we talked about doesn't seem very complicated.
If with all the pointers I've provided you still can't make it work, or if you run into more complicated problems, send an email (username at outlook), I will see what I can do.
https://papers.freebsd.org/2019/eurobsdcon/jude-the_future_o...
Having systemd units automatically categorized and queryable has been very nice (the -u flag). The tag flag has also been great for me.
The --since and --until flags are godsends, I don't really care to waste time converting timestamps in my brain when all I want to do is do something like journalctl -u my_service --since yesterday --until today.
To me a way to centralize logs and have a tool like this to query them in a relatively advanced way is a major benefit.
I find that the complaints about systemd are mainly about UNIX philosphy and not about the actual functionality and benefits of those design choices. It seems like even mentioning that it's good brings back all these 2014 arguments about it.
You brought up mounting, the second paragraph of the systemd-mount manual quite clearly explains the benefit and what makes it different than the lower level mount command. And really it's not like systemd is ripping away your old tools especially in that particular case.
2. DNS handling and NTP comes up over and over...for who exactly? I work with Linux as a full-time job and this has never come up as a pain point.
3. This "Microsoft mentality" thing is such a 2014 argument about systemd. Basically because systemd didn't perfectly conform to "the UNIX philosophy," we are assuming that they are evil bastards like Microsoft. E.g., journalctl had the gall to make a queryable logging system, and because that concept has some passing similarties the Windows Event Viewer it must be bad. If Linux Torvalds has a strong opinionated design on something and refuses a contribution to the Linux kernel, that's cool because he's Enlightened Tech Jesus, but if systemd's maintainers dare to have opinionated design they are draconian Microsoft employees. And again no significant controversial event has happened since that 2014/2015 era of systemd when, really, the software was much older and less mature at that time so disagreements were understandable.
4. Again you claim there are no reasonable answers for how to do "something," when really there are. If nobody knew the answers it wouldn't be the init system for pretty much every big name Linux distro out there (Ubuntu...Red Hat...Fedora...Amazon Linux...Oracle...Arch...SteamOS...)
It and its 787 sibling are highly customized Linux distros.
Aircraft include the 747-8, 787, some 737, ...
http://www.b737.org.uk/flightinstsmax-maint.htm
https://www.teledynecontrols.com/en-us/Product%20Brochures/T...
The people you are attracting to Linux are not the kind of people that will improve it in any way. As Linux is free (well, most distros), you won't even see any extra money. Only idiotic bug reports will increse. "Interent isn't working!!!111 FIX IT NOWWW!!!111"
You're not even attracting competent sysadmins. You'll have more security breaches, more automated hacking (because without manually-written scripts, all systems behave predictably the same), more costly fixes (because consultants that still know the job are expensive).
Mobile users that feel offended users may vote me down, I don't mind, but you know the type of users I was referring to.
As a long time Linux user, what was unexpected and eye-opening was seeing how FreeBSD does things. Somethings better and somethings worse. The better things are WAAYY better. And, for many of those things that felt better, in summary it's really the culmination of the entire ecosystem. The whole package is just better to me. The cohesive system is really a killer app. Oh, and pf is great too.
I havn't given up on linux; it's just running as a VM in bhyve now.
I also run Freebsd on a Thinkpad T490 laptop. Works great.
Meanwhile if you can't find man7.org (Google search results are only getting worse) and start browsing <https://docs.kernel.org>, it refers you to <https://www.kernel.org/doc/man-pages/> which refers you to <https://www.kernel.org/doc/man-pages/maintaining.html>, <https://www.kernel.org/doc/man-pages/missing_pages.html>, and Wikipedia - none of which seem to be relevant, can't tell because it's a wall of text rather than a man page browser.
Now imagine you have to fix a b0rked system that can't display its own man pages. You're now stuck with this mess.
OpenSUSE Tumbleweed is a lot more stable than ArchLinux for that kind of stuff though. It stages updates in tested snapshots. ArchLinux updates just error if you time them right.
This was over 5 years ago so I don't recall the details, but it did involve an issue/bug with systemd's handling of the way its internal services were disabled - it MAY have been unique to RHEL. Their fix was ultimately to upgrade RHEL that by then defaulted to chrony, but they were planning on that upgrade anyways. At the time I was making fun of my friend for using Kubernetes, which IMO is another overly complicated solution. :-P
> Maybe I can help you with that - I used to run a non systemd DHCP
Thanks, but I did solve most of the problems; it was a pain as both documentation and other issues (that again may be resolved) at the time made it a much larger hassle and we were an ubuntu shop moving from upstart to systemd that ubuntu 16.04 moved to. Now that systemd has "won out" (and I have accepted that it has), there's more clear and concise examples in documentation and stack overflow. I still dislike that it bloated out what IMO should be just a service and process management framework, though.
> RE IPv6
As I said, IPv6 (and IPSec) was used as an example of how flexibility is required when supporting services or protocols (and I'm a bit pleasantly surprised that systemd-networkd does), not an issue I was actually fighting. Also, enough consumer ISPs hand out /64's that flexibility isn't easy.
I'm also a strong believer that network configurations shouldn't be "chunked" out into multiple files, as it makes it harder to get a holistic configuration view. Fortunately that's a rare experience I need to deal with in today's world and I don't use linux as a router.
Using Kubernetes is rarely justified because most companies are NOT at google scale :)
> I'm a bit pleasantly surprised that systemd-networkd does
There are many very pleasant surprises with it. I only wish it integrated better with intel iwctl
I'd also be happy if it duplicated iwctl functions so I could get rid of it, and it would be even better if it could also replace bluez: wireless is getting more integrated, with the new WIFI protocols giving a role to BLE (ex: Wifi-Aware 4.0 Instant Communication)
Read about Wifi Aware 4.0 and you will see why having systemd-network work with iwctl and bluez would be much harder than integrating them
> I'm also a strong believer that network configurations shouldn't be "chunked" out into multiple files
Oh no it's about chunking out your /56 prefix to multiple /64 subsets within that prefix. In that specific case, I agree with the article that systemd also made that simpler compared to what needs to be done when not using systemd
> Thanks, but I did solve most of the problems
Great! Should you run into problems during your 24.04 migration, my offer still stands: I think systemd is a nice tool, and I'll be happy to show you how to use it for advanced usecases
Don't hesitate to ping me on ycombinator if I don't reply to your email (the spam filter is not optimal)
Found one, repartitioning:
* https://www.freedesktop.org/software/systemd/man/latest/syst...
Except the file format does not seem to be ACID and can get corrupted, so if the system crashes you may lose the reasons for said crash. This is strange since SQLite was available at the time, so I'm not sure why they didn't use a battle-tested, known-good format; Howard Chu (of OpenLDAP, etc):
* https://www.linkedin.com/pulse/20140924071300-170035-why-you...
> To me a way to centralize logs and have a tool like this to query them in a relatively advanced way is a major benefit.
Centralizing logs from my perspective is sending them to a central host, which last time I checked, journald could not do, so I have to run (r)syslogd regardless to do off-host log-shipping.
And it's easy enough to tell (r)syslogd to put everything in one file (which is the default on some distros) and optionally do separate file at times. With the added benefit of not necessarily having all of your eggs in one binary basket. And if you want a query-able logging API, you can do that too:
* https://www.rsyslog.com/doc/configuration/modules/omlibdbi.h...
* https://syslog-ng.github.io/admin-guide/070_Destinations/270...
> I find that the complaints about systemd are mainly about UNIX philosphy and not about the actual functionality and benefits of those design choices.
My complaint about systemd is about tight coupling between components. If someone finds limitations with (e.g.) journald, how do they swap it out or write a replacement? If the systemd folks want to have their own logging system that's fine, but why won't they architect things so it can be swapped out?
> And really it's not like systemd is ripping away your old tools especially in that particular case.
You mean like udev which used to be in a separate repo but the systemd folks took and tightly coupled?
- bootloader (when root is on ZFS)*
- ARC vs kernel page cache and OOM Killer
That's all in my opinion.
*: Relative to FreeBSD, but that's because bootloader in FreeBSD is part of the base system and in linux it could be one of many.
Very possible, Tumbleweed has had some embarrassing failures.
But when it comes to rolling release on servers I'd still prefer OpenSUSE.
OpenSUSE has whole distributions (MicroOS & Aeon) dedicated to performing automatic updates. ArchLinux is not really made with automatic updates in mind.
Big part of that is possible because OpenSUSE releases Tumbleweed in "snapshots". This means that updated packages are basically staged and tested together before release. This happens a few times a week. If you then experience a failure you can always use an older tumbleweed snapshot. In theory that should provide more stability, but there has recently been a lot of instability especially with SELinux being enabled by default.
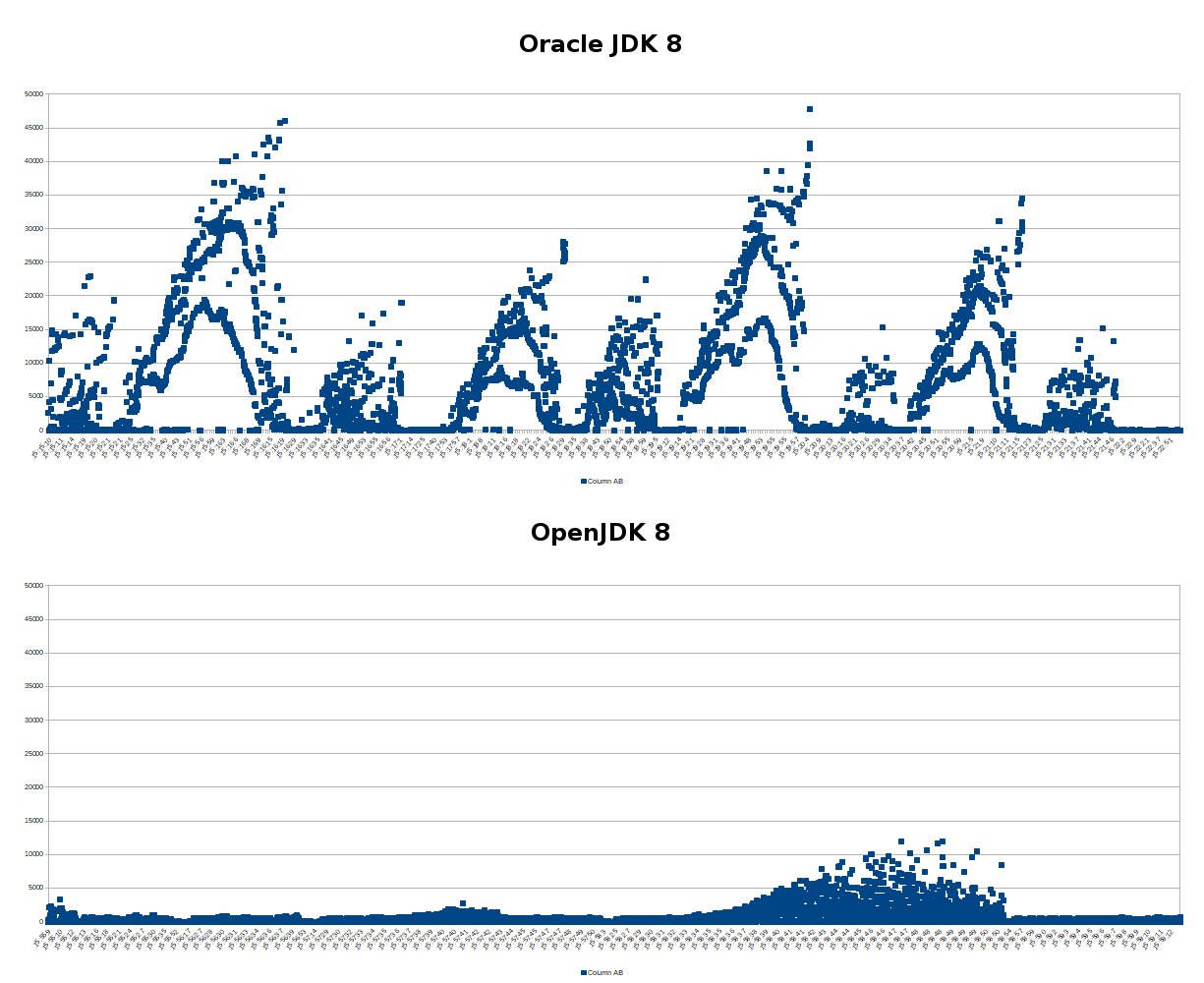{kind=link}