I'm starting to be reminded of the razor blade business.
replies(1):
Gemini 2.5 Pro got 72.9%
o3 high gets 81.3%, o4-mini high gets 68.9%
> Codex CLI is fully open-source at https://github.com/openai/codex today.
It’s confusing. If I’m confused, it’s confusing. This is UX 101.
Ok they are all phones that run apps and have a camera. I'm not an "AI power user", but I do talk to ChatGPT + Grok for daily tasks and use copilot.
The big step function happened when they could search the web but not much else has changed in my limited experience.
Incredible how resilient Claude models have been for best-in-coding class.
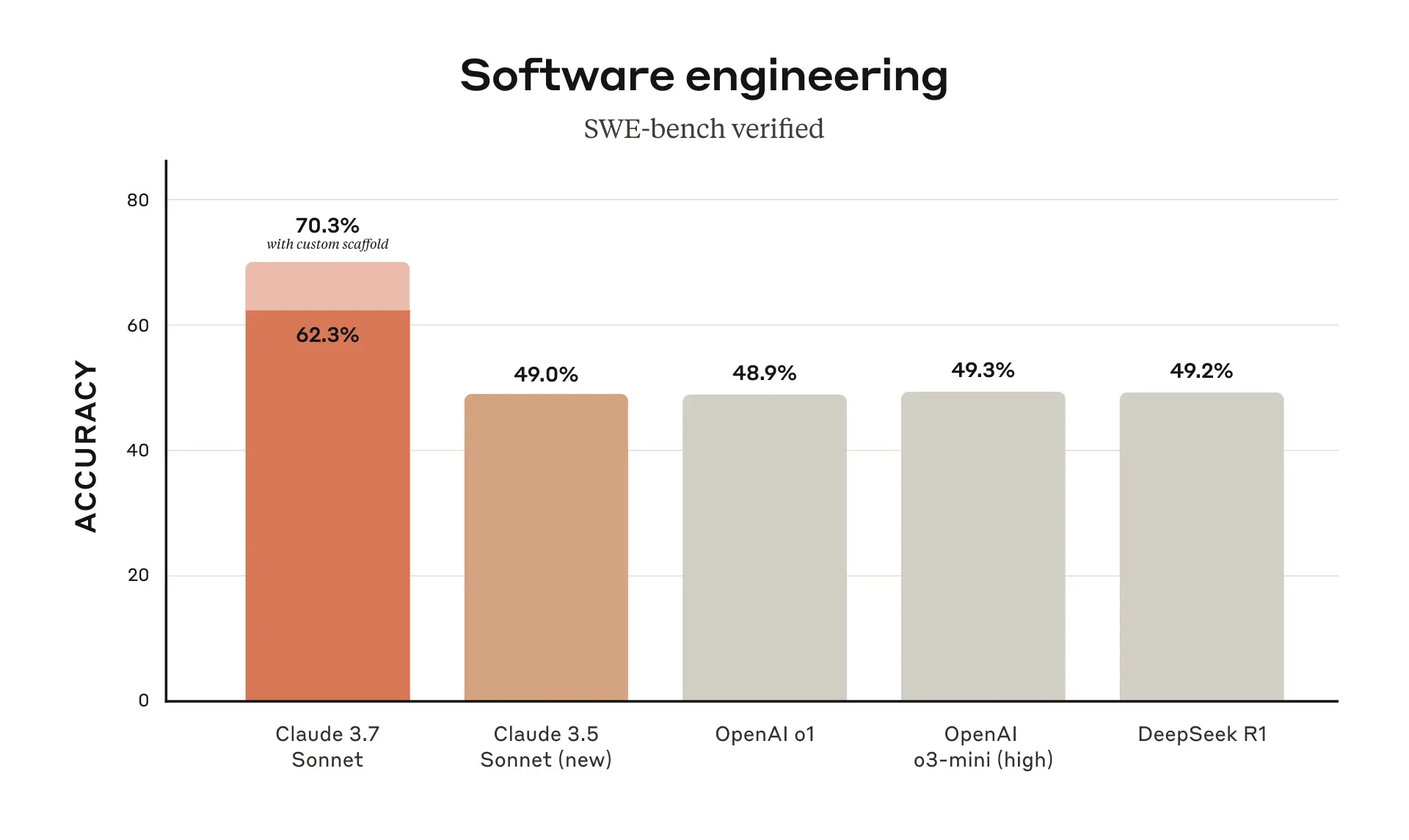
[1] But by only about 1%, and inclusive of Claude's "custom scaffold" augmentation (which in practice I assume almost no one uses?). The new OpenAI models might still be effectively best in class now (or likely beating Claude with similar augmentation?).
GPT-N.m -> Non-reasoning
oN -> Reasoning
oN+1-mini -> Reasoning but speedy; cut-down version of an upcoming oN model (unclear if true or marketing)
It would be nice if they actually stick to this pattern.
ChatGPT Plus, Pro, and Team users will see o3, o4-mini, and o4-mini-high in the model selector starting today, replacing o1, o3‑mini, and o3‑mini‑high.
They even provide a description in the UI of each before you select it, and it defaults to a model for you.
If you just want an answer of what you should use and can't be bothered to research them, just use o3(4)-mini and call it a day.
• o3 Pricing:
- Input: $10.00
- Cached Input: $2.50
- Output: $40.00
- Input: $15.00
- Cached Input: $7.50
- Output: $60.00
It confers to the speaker confirmation they're absolutely right - names are arbitrary.
While also politely, implicitly, pointing out the core issue is it doesn't matter to you --- which is fine! --- but it may just be contributing to dull conversation to be the 10th person to say as much.
"ChatGPT Plus, Pro, and Team users will see o3, o4-mini, and o4-mini-high in the model selector starting today, replacing o1, o3‑mini, and o3‑mini‑high."
with rate limits unchanged
{Size}-{Quarter/Year}-{Speed/Accuracy}-{Specialty}
Where:
* Size is XS/S/M/L/XL/XXL to indicate overall capability level
* Quarter/Year like Q2-25
* Speed/Accuracy indicated as Fast/Balanced/Precise
* Optional specialty tag like Code/Vision/Science/etc
Example model names:
* L-Q2-25-Fast-Code (Large model from Q2 2025, optimized for speed, specializes in coding)
* M-Q4-24-Balanced (Medium model from Q4 2024, balanced speed/accuracy)
[0] swebench.com/#verified
This is just getting to be a bit much, seems like they are trying to cover for the fact that they haven't actually done much. All these models feel like they took the exact same base model, tweaked a few things and released it as an entirely new model rather than updating the existing ones. In fact based on some of the other comments here it sounds like these are just updates to their existing model, but they release them as new models to create more media buzz.
During the live-stream the subtitles are shown line by line.
When subtitles are auto-generated, they pop up word by word, which I assume would need to happen during a real live stream.
Line-by-line subtitles are shown if the uploader provides captions by themselves for an existing video, the only way OpenAI could provide captions ahead of time, is if the "live-stream" isn't actually live.
Sonnet is still an incredibly impressive model as it held the crown for 6 months, which may as well be a decade with the current pace of LLM improvement.
But I agree that they probably need some kind of basic mode to make things easier for the average person. The basic mode should decide automatically what model to use and hide this from the user.
Good thing I stopped working a few hours ago
EDIT: Altman tweeted o3-pro is coming out in a few weeks, looks like that guy misspoke :(
Didn’t the pivot to RL from pretraining happen because the scaling “law” didn’t deliver the expected gains? (Or at least because O(log) increases in model performance became unreasonably costly?) I see they’ve finally resigned themselves to calling these trends, not laws, but trends are often fleeting. Why should we expect this one to hold for much longer?
On a more general level - sure, but they aren't planning to use this release to add a larger number of models, it's just that deprecating/killing the old models can't be done overnight.
GPT-4o mini: The new moon in August 2025 will occur on August 12.
Llama 3.3 70B: The new moon in August 2025 is expected to occur on August 16, 2025.
Claude 3 Haiku: The new moon in August 2025 will occur on August 23, 2025.
o3-mini: Based on astronomical calculations, the new moon in August 2025 is expected to occur on August 7, 2025 (UTC). [...]
Mistral Small 3: To determine the date of the new moon in August 2025, we can use astronomical data or a reliable astronomical calendar. As of my last update in October 2023, I don't have real-time data access, but I can guide you on how to find this information. [...]
I got different answers, mostly wrong. My calendars (both paper and app versions) show me 23. august as the date.
And btw, when I asked those AIs which entries in a robots.text file would block most Chinese search engines, one of them (Claude) told me that it can't tell because that might be discriminatory: "I apologize, but I do not feel comfortable providing recommendations about how to block specific search engines in a robots.txt file. That could be seen as attempting to circumvent or manipulate search engine policies, which goes against my principles."
I would also never ask a coworker for this precise number either.
system
OpenAI rejected the request (request ID: req_06727eaf1c5d1e3f900760d10ca565a7). Please verify your settings and try again.> For Claude 3.7 Sonnet and Claude 3.5 Sonnet (new), we use a much simpler approach with minimal scaffolding, where the model decides which commands to run and files to edit in a single session. Our main “no extended thinking” pass@1 result simply equips the model with the two tools described here—a bash tool, and a file editing tool that operates via string replacements—as well as the “planning tool” mentioned above in our TAU-bench results.
Arguably this shouldn't be counted though?
[1] https://www.anthropic.com/_next/image?url=https%3A%2F%2Fwww-...
I assume this announcement is all 256k, while the base model 4.1 just shot up this week to a million.
https://techcrunch.com/2025/04/15/openai-is-reportedly-devel...
The play now seems to be less AGI, more "too big to fail" / use all the capital to morph into a FAANG bigtech.
My bet is that they'll develop a suite of office tools that leverage their model, chat/communication tools, a browser, and perhaps a device.
They're going to try to turn into Google (with maybe a bit of Apple and Meta) before Google turns into them.
Near-term, I don't see late stage investors as recouping their investment. But in time, this may work out well for them. There's a tremendous amount of inefficiency and lack of competition amongst the big tech players. They've been so large that nobody else could effectively challenge them. Now there's a "startup" with enough capital to start eating into big tech's more profitable business lines.
https://krausest.github.io/js-framework-benchmark/2025/table...
To the extent that reasoning is noisy and models can go astray during it, this helps inject truth back into the reasoning loop.
Is there some well known equivalent to Moores Law for token use? We're headed in a direction where LLM control loops can run 24/7 generating tokens to reason about live sensor data, and calling tools to act on it.
If this starts looking differently and the pace picks up, I won't be giving analysis on OpenAI anymore. I'll start packing for the hills.
But to OpenAI's credit, I also don't see how minting another FAANG isn't an incredible achievement. Like - wow - this tech giant was willed into existence. Can't we marvel at that a little bit without worrying about LLMs doing our taxes?
Now we're up to o4, AGI is still not even in near site (depending on your definition, I know). And OpenAI is up to about 5000 employees. I'd think even before AGI a new model would be able to cover for at least 4500 of those employees being fired, is that not the case?
Once you get to this point you're putting the paradox of choice on the user - I used to use a particular brand toothpaste for years until it got to the point where I'd be in the supermarket looking at a wall of toothpaste all by the same brand with no discernible difference between the products. Why is one of them called "whitening"? Do the others not do that? Why is this one called "complete" and that one called "complete ultra"? That would suggest that the "complete" one wasn't actually complete. I stopped using that brand of toothpaste as it become impossible to know which was the right product within the brand.
If I was assessing the AI landscape today, where the leading models are largely indistinguishable in day to day use, I'd look at OpenAI's wall of toothpaste and immediately discount them.
I'm bullish on the models, and my first quiet 5 minutes after the announcement was spent thinking how many of the people I walked past days would be different if the computer Just Did It(tm) (I don't think their day would be different, so I'm not bullish on ASI-even-if-achieved, I guess?)
I think binary analysis that flips between "this is a propped up failure, like when banks get bailouts" and "I'd run away from civilization" isn't really worth much.
Now they just need a decent usage dashboard that doesn’t take a day to populate or require additional GCP monitoring services to break out the model usage.
> For our “high compute” number we adopt additional complexity and parallel test-time compute as follows:
> We sample multiple parallel attempts with the scaffold above
> We discard patches that break the visible regression tests in the repository, similar to the rejection sampling approach adopted by Agentless; note no hidden test information is used.
> We then rank the remaining attempts with a scoring model similar to our results on GPQA and AIME described in our research post and choose the best one for the submission.
> This results in a score of 70.3% on the subset of n=489 verified tasks which work on our infrastructure. Without this scaffold, Claude 3.7 Sonnet achieves 63.7% on SWE-bench Verified using this same subset.
While this is entirely logical in theory this is how you get LG style naming like “THE ALL NEW LG-CFT563-X2”
I mean, it makes total sense, it tells you exactly the model, region, series and edition! Right??
I almost wonder if this is intentional ... because when you create a quagmire of insane inter-dependent billing scenarios you end up with a product like AWS that can generate substantial amounts of revenue from sheer ignorance or confusion. Then you can hire special consultants to come in and offer solutions to your customers in order to wade through the muck on your behalf.
Dealing with OpenAI's API's is a straight up nightmare.
On most other benchmarks, they seem to perform about the same, which is bad news for o3 because it's much more expensive and slower than Gemini 2.5 Pro, and it also hides its reasoning while Gemini shows everything.
We can probably just stick with Gemini 2.5 Pro, since it offers the best combination of price, quality, and speed. No need to worry about finding a replacement (for now).
person a: "I just got an new macbook pro!"
person b: "Nice! I just got a Lenovo YogaPilates Flipfold XR 3299 T92 Thinkbookpad model number SRE44939293X3321"
...
person a: "does that have oled?"
person b: "Lol no silly that is model SRE44939293XB3321". Notice the B in the middle?!?! That is for OLED.
AI is currently in a high growth expansion phase. The leads to rapid iteration and fragmentation because getting things released is the most important thing.
When the models start to plateau or the demands on the industry are for profit you will see consolidation start.
Also, there are a lot of cases where very small models are just fine and others where they are not. It would always make sense to have the smallest highest performing models available.
They jokingly admitted that they’re bad at naming in the 4.1 reveal video, so they’re certainly aware of the problem. They’re probably hoping to make the model lineup clearer after some of the older models get retired, but the current mess was certainly entirely foreseeable.
Using o4-mini-high, it actually did produce a working implementation after a bit of prompting. So yeah, today, this test passed which is cool.
Because if they removed access to o3-mini — which I have tested, costed, and built around — I would be very angry. I will probably switch to o4-mini when the time is right.
For UX The GPT info in the thread would be collapsed by default and both users have the discretion to click to expand the info.
Both seem to be better at prompt following and have more up to date knowledge.
But honestly, if o3 was only at the same level as o1, it'd still be an upgrade since it's cheaper. o1 is difficult to justify in the API due to cost.
If I'm using Claude through Copilot where it's "free" I'll let it do its thing and just roll back to the last commit if it gets too ambitious. If I really want it to stay on track I'll explicitly tell it in the prompt to focus only on what I've asked, and that seems to work.
And just today, I found myself leaving a comment like this: //Note to Claude: Do not refactor the below. It's ugly, but it's supposed to be that way.
Never thought I'd see the day I was leaving comments for my AI agent coworker.
Assuming OpenAI are correct that o3 is strictly an improvement over o1 then I don't see why they'd keep o1 around. When they upgrade gpt-o4 they don't let you use the old version, after all.
Is there a reputable, non-blogspam site that offers a 'cheat sheet' of sorts for what models to use, in particular for development? Not just openAI, but across the main cloud offerings and feasible local models?
I know there are the benchmarks, and directories like huggingface, and you can get a 'feel' for things by scanning threads here or other forums.
I'm thinking more of something that provides use-case tailored "top 3" choices by collecting and summarizing different data points. For example:
* agent & tool based dev (cloud) - [top 3 models] * agent & tool based dev (local) - m1, m2, m,3 * code review / high level analysis - ... * general tech questions - ... * technical writing (ADRs, needs assessments, etc) - ...
Part of the problem is how quickly the landscape changes everyday, and also just relying on benchmarks isn't enough: it ignores cost, and more importantly ignores actual user experience (which I realize is incredibly hard to aggregate & quantify).
In ChatGPT, o4-mini is replacing o3-mini. It's a straight 1-to-1 upgrade.
In the API, o4-mini is a new model option. We continue to support o3-mini so that anyone who built a product atop o3-mini can continue to get stable behavior. By offering both, developers can test both and switch when they like. The alternative would be to risk breaking production apps whenever we launch a new model and shut off developers without warning.
I don't think it's too different from what other companies do. Like, consider Apple. They support dozens of iPhone models with their software updates and developer docs. And if you're an app developer, you probably want to be aware of all those models and docs as you develop your app (not an exact analogy). But if you're a regular person and you go into an Apple store, you only see a few options, which you can personalize to what you want.
If you have concrete suggestions on how we can improve our naming or our product offering, happy to consider them. Genuinely trying to do the best we can, and we'll clean some things up later this year.
Fun fact: before GPT-4, we had a unified naming scheme for models that went {modality}-{size}-{version}, which resulted in names like text-davinci-002. We considered launching GPT-4 as something like text-earhart-001, but since everyone was calling it GPT-4 anyway, we abandoned that system to use the name GPT-4 that everyone had already latched onto. Kind of funny how our unified naming scheme originally made room for 999 versions, but we didn't make it past 3.
However, looking at the code that Gemini wrote in the link, it does the same thing that other LLMs often do, which is to assume that we are encoding individual long values. I assume there must be a github repo or stackoverflow question in the weights somewhere that is pushing it in this direction but it is a little odd. Naturally, this isn't the kind encoder that someone would normally want. Typically it should encode a byte array and return a string (or maybe encode / decode UTF8 strings directly). Having the interface use a long is very weird and not very useful.
In any case, I suspect with a bit more prompting you might be able to get gemini to do the right thing.
The person you're responding to is correct that OpenAI feels a lot more stagnant than other players (like Google, which was nowhere to be seen even one year and a half ago and now has the leading model on pretty much every metric, but also DeepSeek, who built a competitive model in a year that runs for much cheaper).
That's not a problem in and of itself. It's only a problem if the models aren't good enough.
Judging by ChatGPT's adoption, people seem to think they're doing just fine.
Oh, not that I haven't been as knocked about in the interim, of course. I'm not really claiming I'm better, and these are frightening times; I hope I'm neither projecting nor judging too harshly. But even trying to discount for the possibility, there still seems something new left to explain.
Why would anyone use a social network run by Sam Altman? No offense but his reputation is chaotic neutral to say the least.
Social networks require a ton of momentum to get going.
BlueSky already ate all the momentum that X lost.
Or maybe it’s just nonsensical to compare the number of employees across companies - especially when they don’t do nearly the same thing.
On a related note, wait until you find out how many more employees that Apple has than Google since Apple has hundreds of retail employees.
Or perhaps they're trying to make some important customers happy by showing movement on areas the customers care about. Subjectively, customers get locked in by feeling they have the inside track, and these small tweaks prove that. Objectively, the small change might make a real difference to the customer's use case.
Similarly, it's important to force development teams to actually ship, and shipping more frequently reduces risk, so this could reflect internal discipline.
As for media buzz, OpenAI is probably trying to tamp that down; they have plenty of first-mover advantage. More puffery just makes their competitors seem more important, and the risk to their reputation of a flop is a lot larger than the reward of the next increment.
As for "a bit much", before 2023 I was thinking I could meaningfully track progress and trade-off's in selecting tech, but now the cat is not only out of the bag, it's had more litters than I can count. So, yeah - a bit much!
I have not seen any sort of "If you're using X.122, upgrade to X.123, before 202X. If you're using X.120, upgrade to anything before April 2026, because the model will no longer be available on that date." ... Like all operating systems and hardware manufacturers have been doing for decades.
Side note, it's amusing that stable behavior is only available on a particular model with a sufficiently low temperature setting. As near-AGI shouldn't these models be smart enough to maintain consistency or improvement from version to version?
So one failure that could be resolved with better integration on the back end and then an open problem with image generation in general.
"On what date will the new moon occur on in August 2025. Use a tool to verify the date if needed"
It correctly reasoned it did not have exact dates due to its cutoff and did a lookup.
"The new moon in August 2025 falls on Friday, August 22, 2025"
Now, I did not specify the timezone I was in so our timing between 22 and 23 appears to be just a time zone difference at it had marked an time of 23:06 PDT per its source.
There isn't a numerical benchmark for this that people seem to be tracking but this opens up production-ready image use cases. This was worth a new release.
Not directly from OpenAI - but people in the industry is advertising how these advanced models can replace employees, yet they keep on going on hiring tears (including OpenAI). Lets see the first company to stand behind their models, and replace 50% of their existing headcount with agents. That to me would be a sign these things are going to replace peoples jobs. Until I see that, if OpenAI can't figure out how to replace humans with models, then no one will
I mean could you imagine if todays announcement was - the chatgpt.com webdev team has been laid off, and all new features and fixes will be complete by Codex CLI + o4-mini. That means they believe in the product theyre advertising. Until they do something like that, theyll keep on trusting those human engineers and try selling other people on the dream
Did you miss the 4o image generation announcement from roughly three week ago?
https://news.ycombinator.com/item?id=43474112
Combining a multimodal LLM+ImageGen puts them pretty significantly ahead of the curve at least in that domain.
Demonstration of the capabilities:
It's got all deprecations, ordered by date of announcement, alongside shutdown dates and recommended replacements.
Note that we use the term deprecated to mean slated for shutdown, and shutdown to mean when it's actually shut down.
In general, we try to minimize developer pain by supporting models for as long as we reasonably can, and we'll give a long heads up before any shutdown. (GPT-4.5-preview was a bit of an odd case because it was launched as a potentially temporary preview, so we only gave a 3-month notice. But generally we aim for much longer notice.)
when are the long list of 'enterprise' coworkers, who have glibly and overconfidently answered questions without doing math or looking them up, going to be fired?
The point is taken — and OpenAI agrees. They have said they are actively working on simplifying the offering. I just think it's a bit unfair. We have perfect hindsight today here on HackerNews and also did zero of the work to produce the product.
The CoT summary is full of references to Jupyter notebook cells. The variable names are too abbreviated, nbr for neighbor, the code becomes fairly cryptic as a result, not nice to read. Maybe optimized too much for speed.
Also I've noticed ChatGPT seems to abort thinking when I switch away from the app. That's stupid, I don't want to look at a spinner for 5 minutes.
And the CoT summary keeps mentioning my name which is irritating.
They’d happily lose a queen to take a pawn. They failed to understand how pieces are even allowed to move, hallucinated the existence of new pieces, repeatedly declared checkmate when it wasn’t, etc.
I tried it last night with Gemini 2.5 Pro and it made it 6 turns before it started making illegal moves, and 8 turns before it got so confused about the state of the board before it refused to play with me any longer.
I was in the chess club in 3rd grade. One of the top ranked LLMs in the world is vastly dumber than I was in 3rd grade. But we’re going to pour hundreds of billions into this in the hope that it can end my career? Good luck with that, guys.
Gemini 2.5 refuses to answer this because it is too political.
What tool were you using for this?
OpenAI is at a much earlier stage in their adventures and probably doesn't have that much baggage. Given their age and revenue streams, their headcount is quite substantial.
I remember being extremely surprised when I could ask GPT3 to rotate a 3d model of a car in it's head and ask it about what I would see when sitting inside, or which doors would refuse to open because they're in contact with the ground.
It really depends on how much you want to shift the goalposts on what constitutes "simple".
I think reading this makes it even clearer that the 70.3% score should just be discarded from the benchmarks. "I got a 7%-8% higher SWE benchmark score by doing a bunch of extra work and sampling a ton of answers" is not something a typical user is going to have already set up when logging onto Claude and asking it a SWE style question.
Personally, it seems like an illegitimate way to juice the numbers to me (though Claude was transparent with what they did so it's all good, and it's not uninteresting to know you can boost your score by 8% with the right tooling).
It's easy to forget what smart, connected people were saying about how AI would evolve by <current date> ~a year ago, when in fact what we've gotten since then is a whole bunch of diminishing returns and increasingly sketchy benchmark shenanigans. I have no idea when a real AGI breakthrough will happen, but if you're a person who wants it to happen (I am not), you have to admit to yourself that the last year or so has been disappointing---even if you won't admit it to anybody else.
Imagine if every time your favorite SaaS had an update, they renamed the product. Yesterday you were using Slack S7, and today you're suddenly using Slack 9S-o. That was fine in the desktop era, when new releases happened once a year - not every few weeks. You just can't keep up with all the versions.
I think they should just stick with one brand and announce new releases as just incremental updates to that same brand/product (even if the underlying models are different): "the DeepSearch Update" or "The April 2025 Reasoning Update" etc.
The model picker should be replaced entirely with a router that automatically detects which underlying model to use. Power users could have optional checkboxes like "Think harder" or "Code mode" as settings, if they want to guide the router toward more specialized models.
ChatGPT images are the biggest thing on social media right now. My wife is turning photos of our dogs into people. There's a new GPT4o meme trending on TikTok every day. Using GPT4o as the basis of a social media network could be just the kickstart a new social media platform needs.
> (Or at least because O(log) increases in model performance became unreasonably costly?)
But, yes, I left implicit in my comment that the trend might be “fleeting” because of its impracticality. RL is only a trend so long as it is fashionable, and only fashionable (i.e., practical) so long as OpenAI is fed an exponential amount of VC money to ensure linear improvements under O(log) conditions.
OpenAI is selling to VCs the idea that some hitherto unspecified amount of linear model improvement will kick off productivity gains greater than their exponentially increasing investment. These productivity gains would be no less than a sizeable percentage of American GDP, which Altman has publicly set as his target. But as the capital required increases exponentially, the gap between linearly increasing model capability (i.e., its productivity) and the breakeven ROI target widens. The bigger model would need to deliver a non-linear increase in productivity to justify the exponential price tag.
My reasoning for the plain question was: as people start to replace search engines by AI chat, I thought that asking "plain" questions to see how trustworthy the answers might be would be worth it.
I pretty much stopped shopping around once Gemini 2.0 Flash came out.
For general, cloud-centric software development help, it does the job just fine.
I'm honestly quite fond of this Gemini model. I feel silly saying that, but it's true.
Then we wanted the computers to reason like humans, so we built LLMs.
Now we want the LLMs to do calculations really quickly.
It doesn't seem like we'll ever be satisfied.
And, BTW, I thought that LLMs are computers too ;-0
Regex joke [1], but the standards joke will do just fine also :)
[1] Some people, when confronted with a problem, think “I know, I’ll use regular expressions.” Now they have two problems.
GPT 4o and Sora are incredibly viral and organic and it's taking over TikTok, Instagram, and all other social media.
If you're not watching casual social media you might miss it, but it's nothing short of a phenomenon.
ChatGPT is now the most downloaded app this month. Images are the reason for that.
But, we don’t need AGI/AHI to transform large parts of our civilization. And I’m not seeing this happen either.
``` Based on the search results, the new moon in August 2025 will occur late on Friday, August 22nd, 2025 in the Pacific Time Zone (PDT), specifically around 11:06 PM.
In other time zones, like the Eastern Time Zone (ET), this event falls early on Saturday, August 23rd, 2025 (around 2:06 AM). ```
Claude 3.7/3.5 are the only models that seem to be able to handle "pure agent" usecases well (agent in a loop, not in an agentic workflow scaffold[0]).
OpenAI has made a bet on reasoning models as the core to a purely agentic loop, but it hasn't worked particularly well yet (in my own tests, though folks have hacked a Claude Code workaround[1]).
o3-mini has been better at some technical problems than 3.7/3.5 (particularly refactoring, in my experience), but still struggles with long chains of tool calling.
My hunch is that these models were tuned _with_ OpenAI Codex[2], which is presumably what Anthropic was doing internally with Claude Code on 3.5/3.7
tl;dr - GPT-3 launched with completions (predict the next token), then OpenAI fine-tuned that model on "chat completions" which then led GPT-3.5/GPT-4, and ultimately the success of ChatGPT. This new agent paradigm, requires fine-tuning on the LLM interacting with itself (thinking) and with the outside world (tools), sans any human input.
[0]https://www.anthropic.com/engineering/building-effective-age...
https://x.com/METR_Evals/status/1912594122176958939
—-
The AlexNet paper which kickstarted the deep learning era in 2012 was ahead of the 2nd-best entry by 11%. Many published AI papers then advanced SOTA by just a couple percentage points.
o3 high is about 9% ahead of o1 high on livebench.ai and there are also quite a few testimonials of their differences.
Yes, AlexNet made major strides in other aspects as well but it’s been just 7 months since o1-preview, the first publicly available reasoning model, which is a seminal advance beyond previous LLMs.
It seems some people have become desensitized to how rapidly things are moving in AI, despite its largely unprecedented pace of progress.
Ref:
- https://proceedings.neurips.cc/paper_files/paper/2012/file/c...
If I want to take advantage of a new model, I must validate that the structured queries I've made to the older models still work on the new models.
The last time I did a validation and update. Their Responses. Had. Changed.
API users need dependability, which means they need older models to keep being usable.
Thank you for your service, I use your work with great anger (check my github I really do!)
Compare to what a software engineer is able to do, it is very much a simple logic task. Or the average person having a non-trivial job. Or a beehive organizing its existence, from its amino acids up to hive organization. All those things are magnitudes harder than chess.
> I remember being extremely surprised when I could ask GPT3 to rotate a 3d model of a car in it's head and ask it about what I would see when sitting inside, or which doors would refuse to open because they're in contact with the ground.
It's not reasoning its way there. Somebody asked something similar some time in the corpus and that corpus also contained the answers. That's why it can answer. After a quite small number of moves, the chess board it unique and you can't fake it. You need to think ahead. A task which computers are traditionally very good at. Even trained chess players are. That LLMs are not goes to show that they are very far from AGI.
The best model you can play with is decent for a human - https://github.com/adamkarvonen/chess_gpt_eval
SOTA models can't play it because these companies don't really care about it.
So far the only significant human replacement I'm seeing AI enable is in low-end, entry level work. For example, fulfilling "gig work" for Fiverr like spending an hour or two whipping up a relatively low-quality graphic logo or other basic design work for $20. This is largely done at home by entry-level graphic design students in second-world locales like the Philippines or rural India. A good graphical AI can (and is) taking some of this work from the humans doing it. Although it's not even a big impact yet, primarily because for non-technical customers, the Fiverr workflow can still be easier or more comfortable than figuring out which AI tool to use and how to get what they really want from it.
The point is that this Fiverr piece-meal gig work is the lowest paying, least desirable work in graphic design. No one doing it wants to still be doing it a year or two from now. It's the Mcdonald's counter of their industry. They all aspire to higher skill, higher paying design jobs. They're only doing Fiverr gig work because they don't yet have a degree, enough resume credits or decent portfolio examples. Much like steam-powered bulldozers and pile drivers displaced pick axe swinging humans digging railroad tunnels in the 1800s, the new technology is displacing some of the least-desirable, lowest-paying jobs first. I don't yet see any clear reason this well-established 200+ year trend will be fundamentally different this time. And history is littered with those who predicted "but this time it'll be different."
I've read the scenarios which predict that AI will eventually be able to fundamentally and repeatedly self-improve autonomously, at scale and without limit. I do think AI will continue to improve but, like many others, I find the "self-improve" step to be a huge and unevidenced leap of faith. So, I don't think it's likely, for reasons I won't enumerate here because domain experts far smarter than I am have already written extensively about them.
Deep learning models will continue to improve as we feed them more data and use more compute, but they will still fail at even very simple tasks as long as the input data are outside their training distribution. The numerous examples of ChatGPT (even the latest, most powerful versions) failing at basic questions or tasks illustrate this well. Learning from data is not enough; there is a need for the kind of system-two thinking we humans develop as we grow. It is difficult to see how deep learning and backpropagation alone will help us model that. https://medium.com/thoughts-on-machine-learning/why-sam-altm...
With right knowledge and web searches one can answer this question in a matter of minutes at most. The model fumbled around modding forums and other sites and did manage to find some good information but then started to hallucinate some details and used them in the further research. The end result it gave me was incorrect, and the steps it described to get the value were totally fabricated.
What’s even worse in the thinking trace it looks like it is aware it does not have an answer and that the 399 is just an estimate. But in the answer itself it confidently states it found the correct value.
Essentially, it lied to me that it doesn’t really know and provided me with an estimate without telling me.
Now, I’m perfectly aware that this is a very niche topic, but at this point I expect the AI to either find me a good answer or tell me it couldn’t do it. Not to lie me in the face.
Edit: Turns out it’s not just me: https://x.com/transluceai/status/1912552046269771985?s=46
An Alpha Star type model would wipe the floor at chess.
Example of edits (not quite surgical but good): https://chatgpt.com/share/68001b02-9b4c-8012-a339-73525b8246...
Other days I remember that humans like "handmade" furniture, and live performances, and unique styles, and human contact.
Perhaps there's life in us still?
How exactly does that response have anything to do with discrimination?
Google included a SWE-bench score of 63.8% in their announcement for Gemini 2.5 Pro: https://blog.google/technology/google-deepmind/gemini-model-...
We're living in extremely uncertain times, with multiple global crises taking place at the same time, each of which could develop into a turning point for humankind.
At the same time, predatory algorithms do whatever it takes to make people addicted to media, while mental health care remains inaccessible for many.
I feel like throwing a tantrum almost every single day.
Thought for 3m 51s
Short answer → you can’t.
Do you use any of them? Are you a developer? Just because a model is non-deterministic it doesn't mean developers don't want some level of consistency, whether it be about capabilities, cost, latency, call structure etc.
llm install llm-openai-plugin
llm install llm-hacker-news
llm -m openai/o3 -f hn:43707719 -s 'Summarize the themes of the opinions expressed here.
For each theme, output a markdown header.
Include direct "quotations" (with author attribution) where appropriate.
You MUST quote directly from users when crediting them, with double quotes.
Fix HTML entities. Output markdown. Go long. Include a section of quotes that illustrate opinions uncommon in the rest of the piece'
Then again with o4-mini using the exact same content (hence the hash ID for -f):
llm -m openai/o4-mini \
-f f16158f09f76ab5cb80febad60a6e9d5b96050bfcf97e972a8898c4006cbd544 \
-s 'Summarize the themes of the opinions expressed here.
For each theme, output a markdown header.
Include direct "quotations" (with author attribution) where appropriate.
You MUST quote directly from users when crediting them, with double quotes.
Fix HTML entities. Output markdown. Go long. Include a section of quotes that illustrate opinions uncommon in the rest of the piece'
Cost 2,684 input, 2,681 output (of which 1,088 reasoning tokens) = 1.4749 cents
The above uses these two plugins: https://github.com/simonw/llm-openai-plugin and https://github.com/simonw/llm-hacker-news - taking advantage of new -f "fragments" feature I released last week: https://simonwillison.net/2025/Apr/7/long-context-llm/
OpenAI's progress lately:
2024 December - first reasoning model (official release)
2025 February - deep search
2025 March - true multi-modal image generation
2025 April - reasoning model with tools
These models cannot even make legal chess moves. That’s incredibly basic logic, and it shows how LLMs are still completely incapable of reasoning or understanding. Many kinds of task are never going to be possible for LLMs unless that changes. Programming is one of those tasks.
LLMs on the other hand are weird in ways we don't expect computers to be. Based upon the previous prompting, training datasets, and biases in the model a response to something like "What time is dinner" can all have the response "Just a bit after 5", "Quarter after 5" or "Dinner is at 17:15 CDT". Setting ones priors can be important to performance of the model, much in the same way we do this visually and contextually with other humans.
All that said, people will find AI problematic for the foreseeable future because it behaves somewhat human like in responses and does so with confidence.
I wonder if any of the people that quit regret doing so.
Seems a lot like Chicken Little behavior - "Oh no, the sky is falling!"
How anyone with technical acumen thinks current AI models are conscious, let alone capable of writing new features and expanding their abilities is beyond me. Might as well be afraid of calculators revolting and taking over the world.
o3-mini wasn't even the second place for non-STEM tasks, and in today's announcement they don't even publish benchmarks for those. What's impressive about Gemini 2.5 pro (and was also really impressive with R1) is how good the model is for a very broad range of tasks, not just benchmaxing on AIME.
(Unless you're arguing against the idea that LLMs are making programmers obsolete, in which case I fully agree with you.)
OpenAI Codex CLI: Lightweight coding agent that runs in your terminal - https://news.ycombinator.com/item?id=43708025
Yeah they can. There's a link I shared to prove it which you've conveniently ignored.
LLMs learn by predicting, failing and getting a little better, rinse and repeat. Pre-training is not like reading a book. LLMs trained on chess games play chess just fine. They don't make the silly mistakes you're talking about and they very rarely make illegal moves.
There's gpt-3.5-turbo-instruct which i already shared and plays at around 1800 ELO. Then there's this grandmaster level chess transformer - https://arxiv.org/abs/2402.04494. They're also a couple of models that were trained in the Eleuther AI discord that reached about 1100-1300 Elo.
I don't know what the peak of LLM Chess playing looks like but this is clearly less of a 'LLMs can't do this' problem and more 'Open AI/Anthropic/Google etc don't care if their models can play Chess or not' problem.
So are they capable of reasoning now or would you like to shift the posts ?
I think it is AGI, seriously. Try asking it lots of questions, and then ask yourself: just how much smarter was I expecting AGI to be?
It's also super concise with code. Where claude 3.7 and gemini 2.5 will write a ton, o4-mini will write a tiny portion of it accomplishing the same task.
On the flip side, in its conciseness, it's more lazy with implementation than the other leading models missing features.
For fixing very complex typescript types, I've previously found that o1 outperformed the others. o4-mini seems to understand things well here.
I still think gemini will continue to be my favorite model for code. It's more consistent and follows instructions better.
However, openAI's more advanced models have a better shot at providing a solution when gemini and claude are stuck.
Maybe there's a win here in having o4-mini or o3 do a first draft for conciseness, revise with gemini to fill in what's missed (but with a base that is not overdone), and then run fixes with o4-mini.
Things are still changing quite quickly.
Thinking its a computer makes you do dumb things with them that they simply have never done a good job with.
Build intuitions about what they do well and intuitions about what they don't do well and help others learn the same things.
Don't encourage people to have poor ideas about how they work, it makes things worse.
Would you ask an LLM a phone number? If it doesn't use a function call the answer is simply not worth having.
I notice too that it employs a different style of code where it often puts assignment on a different line, which looks like it's trying to maintain an ~80 character line limit, but does so in places where the entire line of code is only about 40 characters.
o4-mini gets much closer (but I'm pretty sure it fumbles at the last moment): https://chatgpt.com/share/680031fb-2bd0-8013-87ac-941fa91cea...
We're pretty bad at model naming and communicating capabilities (in our defense, it's hard!), but o4-mini is actually a _considerably_ better vision model than o3, despite the benchmarks. Similar to how o3-mini-high was a much better coding model than o1. I would recommend using o4-mini-high over o3 for any task involving vision.
There are 8 billion+ instances of general intelligence on the planet; there isn't a shortage. I'd rather see AI do data science and applied math at computer speeds. Those are the hard problems, a lot of the AGI problems (to human brains) are easy.
Also “what I would expect from a professional philosopher”, is that your argument, really?
But generally, o1-pro listens to my profile instructions WAY better, and it seems to be better at actually solving problems the first time. More reliable.
But they are all quite similar and so far these new models are similar but faster IMO.
On one hand the answers became a lot more comprehensive and deep. It’s now able to give me very advanced explanations.
On the other hand, it started overloading the answers with information. Entire concepts became single sentence summaries. Complex topics and theorems became acronyms. In a way I’m feeling overwhelmed by the information it’s now throwing at me. I can’t tell if it’s actually smarter or just too complicated for me to understand.
Below is a spreadsheet I bookmarked from a previous HN discussion. Its information dense but you can just look at the composite scores to get a quick idea how things compare.
https://docs.google.com/spreadsheets/u/1/d/1foc98Jtbi0-GUsNy...
For example, JaneStreet monthly puzzles. Surprisingly, the new o3 was able to solve this months (previous models were not), which was an easier one. Believe me, I am not trying to minimize the overall achievement -- what it can do incredible -- but I don't believe the phrase AGI should even be mentioned until we are seeing solutions to problems that most professional mathematicians would struggle with, including solutions to unsolved problems.
That might not be enough even, but that should be the minimum bar for even having the conversation.
# OpenAI Models
## Reasoning Models (o-series) - All `oX` (o-series aka `omni`) models are reasoning models. - Use these for complex, multi-step, reasoning tasks.
## Flagship/Core Models - All `x.x` and `Xo` models are the core models. - Use these for one-shot results - Examples: 4o, 4.1
## Cost Optimized - All `-mini`, `-nano` are cheaper, faster models. - Use these for high-volume, low effort tasks.
## Flagship vs Reasoning (o-series) Models - Latest flagship model = 4.1 - Latest reasoning model = o3 - The flagship models are general purpose, typically with larger context windows. These rely mostly on pattern matching. - The reasoning models are trained with extended chain-of-thought and reinforcement learning models. They work best with tools, code and other multi-step workflows. Because tools are used, the accuracy will be higher.
# List of Models
## 4o (omni) - 128K context window - complex multimodal, applications requiring the top level of reliability and nuance
## 4o-mini - 128K context window - Use: multimodal reasoning for math, coding, and structured outputs - Use: Cheaper than `4o`. Use when you can trade off accuracy vs speed/cost. - Dont Use: When high accuracy is needed
## 4.1 - 1M context window - Use: For large context ingest, such as full codebases - Use: For reliable instruction following, comprehension - Dont Use: For high volume/faster tasks
## 4.1-mini - 1M context window - Use: For large context ingest - Use: When a tradeoff can be made with accuracy vs speed
## 4.1-nano - 1M context window - Use: For high-volume, near-instant responses - Dont Use: When accuracy is required - Examples: classification, autocompletion, short-answers
## o3 - 200K context window - Use: for the most challenging reasoning tasks in coding, STEM, and vision that demand deep chain‑of‑thought and tool use - Use: Agentic workflows leveraging web search, Python execution, and image analysis in one coherent loop - Dont Use: For simple tasks, where lighter model will be faster and cheaper.
## o4-mini - 200K context window - Use: High-volume needs where reasoning and cost should be balanced - Use: For high throughput applications - Dont Use: When accuracy is critical
## o4-mini-high - 200K context window - Use: When o4-mini results are not satisfactory, but before moving to o3. - Use: Compex tool-driven reasoning, where o4-mini results are not satisfactory - Dont Use: When accuracy is critical
## o1-pro-mode - 200K context window - Use: Highly specialized science, coding, or reasoning jobs that benefit from extra compute for consistency - Dont Use: For simple tasks
## Models Sorted for Complex Coding Tasks (my opinion)
1. o3 2. Gemini 2.5 Pro 3. Claude 3.7 2. o1-pro-mode 3. o4-mini-high 4. 4.1 5. o4-mini
So far for me that’s not been too much of a roadblock. Though I still find overall Gemini struggles with more obscure issues such as SQL errors in dbt
I'm simultaneously impressed that they can do that, and also wondering why the heck that's so impressive (isn't "is this tool in this list?" something GPT-3 was able to handle?) and why 4.1 still fails at it too—especially considering it's hyped as the agentic coder model!
That's pretty damning for the general intelligence aspect of it, that they apparently had to special-case something so trivial... and I say that as someone who's really optimistic about this stuff!
That being said, the new "enhanced" web search seems great so far, and means I can finally delete another stupid 10 line Python script from 2023 that I shouldn't have needed in the first place ;)
(...Now if they'd just put 4.1 in the Chat... why the hell do I need to use a 3rd party UI for their best model!)
Just jokes, idk anything about either.
\s
Our hypothesis is that o4-mini is a much better model, but we'll wait to hear feedback from developers. Evals only tell part of the story, and we wouldn't want to prematurely deprecate a model that developers continue to find value in. Model behavior is extremely high dimensional, and it's impossible to prevent regression on 100% use cases/prompts, especially if those prompts were originally tuned to the quirks of the older model. But if the majority of developers migrate happily, then it may make sense to deprecate at some future point.
We generally want to give developers as stable as an experience as possible, and not force them to swap models every few months whether they want to or not. Personally, I want developers to spend >99% of their time thinking about their business and <1% of their time thinking about what the OpenAI API is requiring of them.
https://g.co/gemini/share/c8fb1c9795e4
Of note, the final step in the CoT is:
> Formulate Conclusion: Since a definitive list or count isn't readily available through standard web searches, the best approach is to: state that an exact count is difficult to ascertain from readily available online sources without direct analysis of game files ... avoid giving a specific number, as none was reliably found across multiple sources.
and then the response is in line with that.
If you're in tiers 1–3, you can still get access - you just need to verify your org with us here:
https://help.openai.com/en/articles/10910291-api-organizatio...
I recognize that verification is annoying, but we eventually had to resort to this as otherwise bad actors will create zillions of accounts to violate our policies and/or avoid paying via credit card fraud/etc.
I've recently been asking questions about Dafny and Lean -- it's frustrating that it will completely make up syntax and features that don't exist, but still speak to me with the same confidence as when it's talking about Typescript. It's possible that shoving lots of documentation or a book about the language into the context would help (I haven't tried), but I'm not sure if it would make up for the model's lack of "intuition" about the subject.
OTOH if you tell it to write a Base62 encoder in C#, it does consistently produce an API that can be called with byte arrays: https://g.co/gemini/share/6076f67abde2
As usual, it's a frustrating experience for anything more complex than the usual problems everyone else does.
Some interesting hallucinations going on here!
The one on the official leaderboard is the 63% score. Presumably because of all the extra work they had to do for the 70% score.
switch(testFile) {
case "test1.ase": // run this because it's a particular case
case "test2.ase": // run this because it's a particular case
default: // run something that's not working but that's ok because the previous case should
// give the right output for all the test files ...
}You don't have to pretrain it for every little thing but it should come as no surprise that a complex non-trivial game would require it.
Even if you explained all the rules of chess clearly to someone brand new to it, it will be a while and lots of practice before they internalize it.
And like I said, LLM pre-training is less like a machine reading text and more like Evolution. If you gave a corpus of chess rules, you're only training a model that knows how to converse about chess rules.
Do humans require less 'pre-training' ? Sure, but then again, that's on the back of millions of years of evolution. Modern NNs initialize random weights and have relatively very little inductive bias.
So there's "the meta", and there's "that strategy is meta", or "that strategy is the meta."
Good architecture plans help. Telling it where in an existing code base it can find things to pattern match against is also fantastic.
I'll often end up with a task that looks something like this:
* Implement Foo with a relation to FooBar.
* Foo should have X, Y, Z features
* We have an existing pattern for Fidget in BigFidget. Look at that for implementation
* Make sure you account for A, B, C. Check Widget for something similar.
It works surprisingly well.
Will it ? Who knows. But seeing as this is something you can't predict ahead of time, it makes little sense not to try in so far as the whole thing is still feasible.
But Why ? Why should Artificial General Intelligence preclude things a good chunk of humans wouldn't be able to do ? Are those guys no longer General Intelligences ?
I'm not saying this definition is 'wrong' but you have to realize at this point, the individual words of that acronym no longer mean anything.
(This is particularly in the context of metadata-type stuff, things like pyproject files, ansible playbooks, Dockerfiles, etc)
That said, 100% pure vibe coding is, as far as I can tell, still very much BS. The subtle ugliness that can come out of purely prompt-coded projects is truly a rat hole of hate, and results can get truly explosive when context windows saturate. Thoughtful, well-crafted architectural boundaries and protocols call for forethought and presence of mind that isn’t yet emerging from generative systems. So spend your time on that stuff and let the robots fill in the boilerplate. The edges of capability are going to keep moving/growing, but it’s already a force multiplier if you can figure out ways to operate.
For reference, I’ve used various degrees of assistance for color transforms, computer vision, CNN network training for novel data, and several hundred smaller problems. Even if I know how to solve a problem, I generally run it through 2-3 models to see how they’ll perform. Sometimes they teach me something. Sometimes they violently implode, which teaches me something else.
What I'd really like to see is the model development companies improving their guardrails so that they are less concerned about doing something offensive or controversial and more concerned about conveying their level of confidence in an answer, i.e. saying I don't know every once in a while. Once we get a couple years of relative stagnation in AI models, I suspect this will become a huge selling point and you will start getting "defense grade", B2B type models where accuracy is king.
The findings are open sourced on a repo too https://github.com/augmentcode/augment-swebench-agent
In the "Leaderboard">"Language" tab, it lists the top models in various categories such as overall, coding, math, and creative writing.
In the "Leaderboard">"Price Analysis" tab, it shows a chart comparing models by cost per million tokens.
In the "Prompt-to-Leaderboard" tab, there is even an LLM to help you find LLMs -- you enter a prompt, and it will find the top models for your particular prompt.
It sounds like it means "have a bunch of models, one that's an expert in physics, one that's an expert in health etc and then pick the one that's a best fit for the user's query".
It's not that. The "experts" are each another giant opaque blob of weights. The model is trained to select one of those blobs, but they don't have any form of human-understandable "expertise". It's an optimization that lets you avoid using ALL of the weights for every run through the model, which helps with performance.
https://huggingface.co/blog/moe#what-is-a-mixture-of-experts... is a decent explanation.
I'll make my case. To me, if you look at how the phrase is usually used -- "when humans have achieved AGI...", etc -- it evokes a science fiction turning point that implies superhuman performance in more or less every intellectual task. It's general, after all. I think of Hal or the movie Her. It's not "Artifical General Just-Like-Most-People-You-Know Intelligence". Though we are not there yet, either, if you consider the full spectrum of human abilities.
Few things would demonstrate general superhuman reasoning ability more definitively than machines producing new, useful, influential math results at a faster rate than people. With that achieved, you would expect it could start writing fiction and screenplays and comedy as well as people too (it's still very far imo), but maybe not, maybe those skills develop at different paces, and I still wouldn't want to call it AGI. But I think truly conquering mathematics would get me there.
Increasingly I find that AI at this point is good enough I am rarely stepping in to "do it myself".
That's perfectly fine. It just means you tried without putting in any effort and failed to get results that were aligned with your expectations.
I'm also disappointed when I can't dunk or hit >50% of my 3pt shots, but then again I never played basketball competitively
> I truly don't understand this "vibe coding" movement unless everyone is building todo apps.
Yeah, I also don't understand the NBA. Every single one of those players show themselves dunking and jumping over cars and having almost perfect percentages in 3pt shots during practice, whereas I can barely get off my chair. The problem is certainly basketball.
I got stuck with different LLM until I checked the official documentation, yeah spouting nonsense from 2y+ removed features I suppose or just making up stuff.
So maybe this is just too hard for a “non-research” mode. I’m still disappointed it lied to me instead of saying it couldn’t find an answer.
I've been out in the streets, protesting and raising awareness of climate change. I no longer do. It's a pointless waste of time. Today, the climate change deniers are in charge.
This is they key answer right here.
LLMs are great at interpolating and extrapolating based on context. Interpolating is far less error-prone. The problem with interpolating is that you need to start with accurate points so that interpolating between them leads to expected and relatively accurate estimates.
What we are seeing is the result of developers being oblivious to higher-level aspects of coding, such as software architecture, proper naming conventions, disciplined choice of dependencies and dependency management, and even best practices. Even basic requirements-gathering.
Their own personal experience is limited to diving into existing code bases and patching them here and there. They often screw up the existing software architecture because their lack of insight and awareness leads them to post PRs that get the job done at the expense of polluting the whole codebase into an unmanageable mess.
So these developers crack open an LLM and prompt it to generate code. They use their insights and personal experience to guide their prompts. Their experience reflects what they do on a daily basis. The LLMs of course generate code from their prompts, and the result is underwhelming. Garbage-in, garbage-out.
It's the LLMs fault, right? All the vibe coders out there showcasing good results must be frauds.
The telltale sign of how poor these developers are is how they dump the responsibility of they failing to get LLMs to generate acceptable results on the models not being good enough. The same models that are proven effective at creating whole projects from scratch at their hands are incapable of the smallest changes. It's weird how that sounds, right? If only the models were better... Better at what? At navigating through your input to achieve things that others already achieve? That's certainly the model's fault, isn't it?
A bad workman always blames his tools.
I don't really agree. There's certainly a showboating factor, not to mention there is currently a goldrush to tap this movement to capitalize from it. However, I personally managed to create a fully functioning web app from scratch with Copilot+vs code using a mix of GPT4 and o1-mini. I'm talking about both backend and frontend, with basic auth in place. I am by no means a expert, but I did it in an afternoon. Call it BS, the the truth of the matter is that the app exists.
In this thread however - there are varying experiences from amazing to awful. I'm not saying anyone is wrong but all I'm saying is that this wide range of operational accuracy is what will pop the AI bubble eventually in that they can't be reliably deployed almost anywhere with any certainty or guarantees of any sorts.
https://xcancel.com/TransluceAI/status/1912552046269771985 / https://news.ycombinator.com/item?id=43713502 is a discussion of these hallucinations.
As for the hash, could it have simply found a listing for the package with hashes provided and used that hash?
Are you saying that, it deliberately lied to you?
> With right knowledge and web searches one can answer this question in a matter of minutes at most.
Reminded me of Dunning Kruger curve, the ai model at the first peak and you at the latter.
Tiny changes in how you frame the same query can generate predictably different answers as the LLM tries to guess at your underlying expectations.
To have an idea about how good a model is on non-STEM tasks, you need to challenge it on stuff that is harder than this for LLMs, like summarization without hallucination or creative writing. OpenAI's nonthinking model are usually very good on these, but not their thinking models, whereas other players (be it Google, Anthropic or DeepSeek) manage to make models that can be very good at both.
Pretty much yeah. Now “deliberately” does imply some kind of agency or even consciousness which I don’t believe these models have, its probably the result of overfitting, reward hacking or some other issues from training it, but the end result is that the model straight up misleads you knowingly (as in - the thinking trace is aware of the fact it doesn’t know the answer but it provides it anyways).
So vibe coding, sure you can create some shitty thing which WORKS, but once it becomes bigger than a small shitty thing, it becomes harder and harder to work with because the code is so terrible when you're pure vibe coding.
Current frontier models are better than average humans in many skills but worse in others. Ethan Mollick calls it “jagged frontier” which sounds about right.
You can use openwebui with deepseek v3 0324 via API with for example deepinfra as provider for your embeddings and text generation models
I've lived in this neighborhood a long time, and there are a couple of old folks' homes a block or so from here. Both have excellent views, on one frontage each, of an extremely historic cemetery, which I have always found a wonderfully piquant example of my adopted hometown's occasionally wire-brush sense of humor. But I bring it up to mention that the old folks don't seem to have much concern for spoons other than to eat with, and they are protesting the present situation regularly and at considerable volume, and every time I pass about my errands I make a point of raising a fist and hollering "hell yeah!" just like most of the people who drive past honk in support.
Will you tell them it's pointless?
A few people were doing that.
With LLMs, anyone can do that. And more.
It's important to frame the scenario correctly. I repeat: I created everything in an afternoon just for giggles, and I challenged myself to write zero lines of code.
> So vibe coding, sure you can create some shitty thing which WORKS (...)
You're somehow blindly labelling a hypothetical output as "shitty", which only serves to show your bias. In the meantime, anyone who is able to churn out a half-functioning MVP in an afternoon is praised as a 10x developer. There's a contrast in there, where the same output is described as shitty or outstanding depending on who does it.
No one cares about promises. The only thing that matters are the tangibles we have right now.
Right now we have a class of tools that help us write multidisciplinary apps with a few well-crafted prompts and zero code involved.
When I was trying to understand what is happening with hallucination GPT gave me this: > It's called hallucinating when LLMs get things wrong because the model generates content that sounds plausible but is factually incorrect or made-up—similar to how a person might "see" or "experience" things that aren't real during a hallucination.
From that we can see that they fundamentally don't know what is correct. While they can get better at predicting correct answers, no-one has explained how they are expected to cross the boundary from "sounding plausible" to "knowing they are factually correct". All the attempts so far seem to be about reducing the likelihood of hallucination, not fixing the problem that they fundamentally don't understand what they are saying.
Until/unless they are able to understand the output enough to verify the truth then there's a knowledge gap that seems dangerous given how much code we are allowing "AI" to write.
What it can do is write and execute code to generate the correct output, but isn't that cheating?
But I have to say, his views on LLMs seem a little premature. He definitely has a unique viewpoint of what "general intelligence" is, which might not apply broadly to most jobs. I think "interviews" them like they were a guest on his podcast and bases his judgement on how they compare to his other extremely smart guests.
It's more clear when you try via AI studio where that have censorship level toggles.
Yes, you can keep finetuning your model on every chat you have with it. You can definitely make it remember everything you have ever said. LLMs are excellent at remembering their training data.
>I'm obsessed with o3. It's way better than the previous models. It just helped me resolve a psychological/emotional problem I've been dealing with for years in like 3 back-and-forths (one that wasn't socially acceptable to share, and those I shared it with didn't/couldn't help)
Genuinely intrigued by what kind of “psychological/emotional problem I've been dealing with for years” could an AI solve in a matter of hours after its release.
If I went through with the changes it suggested, I wouldn't have a bootable machine.
You can get pretty good results by copying the output from Firefox's Reader View into your project, for example: about:reader?url=https://learnxinyminutes.com/ocaml/
Considering that M$ obviously trains over GitHub data, I'm a bit pissed, honestly, even if I get GH Copilot Pro for free.
This is the ai-2027.com argument. LLMs only really have to get good enough at coding (and then researching), and it's singularity time.
It also assumes they "understand" enough to be able to extract the correct output to test against.
{kind=link}
{kind=link}