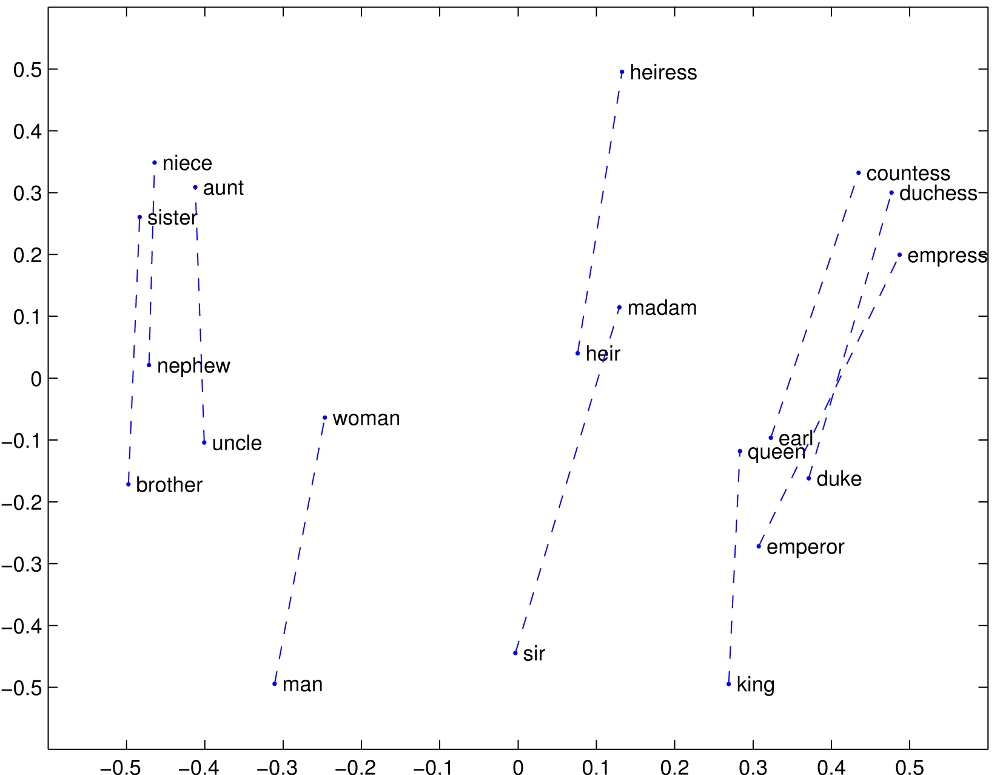
> The 2D map analogy was a nice stepping stone for building intuition but now we need to cast it aside, because embeddings operate in hundreds or thousands of dimensions. It’s impossible for us lowly 3-dimensional creatures to visualize what “distance” looks like in 1000 dimensions. Also, we don’t know what each dimension represents, hence the section heading “Very weird multi-dimensional space”.5 One dimension might represent something close to color. The king - man + woman ≈ queen anecdote suggests that these models contain a dimension with some notion of gender. And so on. Well Dude, we just don’t know.
nit. This suggests that the model contains a direction with some notion of gender, not a dimension. Direction and dimension appear to be inextricably linked by definition, but with some handwavy maths, you find that the number of nearly orthogonal dimensions within n dimensional space is exponential with regards to n. This helps explain why spaces on the order of 1k dimensions can "fit" billions of concepts.
replies(12):
{kind=link}