How common is avx on edge platforms?
replies(2):
I recall something like when he first ported it and it worked on my M1 Max he hadn't even yet tested it on Apple Silicon since he didn't have the hardware.
Honestly, with this and whisper, I am a huge fan. Good luck to him and the new company.
“OpenAI recently released a model for automatic speech recognition called Whisper. I decided to reimplement the inference of the model from scratch using C/C++. To achieve this I implemented a minimalistic tensor library in C and ported the high-level architecture of the model in C++.”
That “minimalistic tensor library” was ggml.
[1] https://en.wikipedia.org/wiki/Benevolent_dictator_for_life
I want a local ChatGPT fine tuned on my personal data running on my own device, not in the cloud. Ideally open source too, llama.cpp is looking like the best bet to achieve that!
Excited to see how his venture goes!
Do you have more info on the controversy? I'm not sure ejecting developers just because of controversy is honestly good stewardship.
I don't know why project founders head this way...as the track records of leaders who do this end up disappointing the involved community at some point. Look to matt klein + cloud native computing foundation at envoy for a somewhat decent model of how to do this better.
We continue down the Open Core model yet it continues to fail communities.
There are advantages to simplicity, after all.
https://github.com/ggerganov/llama.cpp/blob/44f906e8537fcec9...
I wonder how much more efficient it would be when Taskflow lib was used instead, or even inteltbb.
The problem is, this financial backing and support is via VCs, who will steer the project to close it all up again.
> I want a local ChatGPT fine tuned on my personal data running on my own device, not in the cloud. Ideally open source too, llama.cpp is looking like the best bet to achieve that!
I think you are setting yourself up for disappointment in the future.
Its comparable to Apache TVM's vulkan in speed on cuda, see https://github.com/mlc-ai/mlc-llm
But honestly, the biggest advantage of llama.cpp for me is being able to split a model so performantly. My puny 16GB laptop can just barely, but very practically, run LLaMA 30B at almost 3 tokens/s, and do it right now. That is crazy!
I'm not saying it was bad stewardship, I honestly don't know. I just agree that we shouldn't make a judgment without more information.
Just because you can (and have the connections), doesn't mean you should. It's a sad state of OSS when the best most brightest developers/founders reach for antiquated models.
Maybe we take up a new rules in OSS communities that say you must release your CORE software as MIT at the same time you plan to go Open Core (and no sooner).
Why should OSS communities take on your product market fit?!
How exactly could they meaningfully do that? Genuine question. The issue with the OpenAI business model is that the collaboration within academia and open source circles is creating innovations that are on track to out-pace the closed source approach. Does OpenAI have the pockets to buy the open source collaborators and researchers?
I'm truly cynical about many aspects of the tech industry but this is one of those fights that open source could win for the betterment of everybody.
More generally, if you want to take away somebody's business model you need to provide one that works. It isn't easy.
Man, nobody has time for this shit. Leave the games and the drama for the social justice warriors and the furries. People building shit ain't got time for this - ejecting trouble makers is the right way to go regardless of which "side" they're on.
Why would you say that?
For the people who build solutions for data handling— ranging from crud to building highly scalable solutions— these things are alien concepts. (Or maybe I am just talking about it myself)
A) Embed OpenAI (etc.) API everywhere. Make embedding easy and trivial. First to gain a small API/install moat (user/dev: 'why install OSS model when OpenAI is already available with an OS API?'). If it's easy to use OpenAI but not open source they have an advantage. Second to gain brand. But more importantly:
B) Gain a technical moat by having a permanent data advantage using the existing install base (see above). Retune constantly to keep it.
C) Combine with existing propriety data stores to increase local data advantage (e.g. easy access for all your Office 365/GSuite documents, while OSS gets the scary permission prompts).
D) Combine with existing propriety moats to mutually reinforce.
E) Use selective copyright enforcement to increase data advantage.
F) Lobby legislators for limits that make competition (open or closed source) way harder.
TL;DR: OSS is probably catching up on algorithms. When it comes to good data and good integrations OSS is far behind and not yet catching up. It's been argued that OpenAI's entire performance advantage is due to having better data alone, and they intend to keep that advantage.
Here's the Matt K article https://mattklein123.dev/2021/09/14/5-years-envoy-oss/
Pretty sure you might be looking for this: https://github.com/SamurAIGPT/privateGPT
Fine-tuning is good for treating it how to act, but not great for reciting/recalling data.
Please tell me your config! I have an i9-10900 with 32GB of ram that only gets .7 tokens/s on a 30B model
Which is my personal holy grail towards making myself unnecessary; it'd be amazing to be doing some light gardening while the bot handles my coworkers ;)
Now, we just need a post that benchmarks the different options (ggml, tvm, AItemplate, hippoml) and helps deciding which route to take.
For an individual running a small open source project, there's time enough for coding or detailed justice, but not both. When two parties start pointing fingers and raising hell and its not immediately clear who is in the right, ban both and let them fork it.
Some of the earlier descriptions of the optimization being used in the AI learning was about steepest descent, that is, just find the gradient of the function are trying to minimize and move some distance in that direction. Just using the gradient was concerning since that method tends to zig zag where after, say, 100 iterations the distance moved in the 100 iterations might be several times farther than the distance from the starting point of the iterations to the final one. Can visualize this zig zag already in just two dimensions, say, following a river, say, a river that curves, down a valley the river cut over a million years or so, that is, a valley with steep sides. Then gradient descent may keep crossing the river and go maybe 10 feet for each foot downstream!
Right, if just trying to go downhill on a tilted flat plane, then the gradient will point in the steepest descent on the plane and gradient descent will go all way downhill in just one iteration.
In even moderately challenging problems, BFGS can a big improvement.
This is SOP for American schools. It's laziness there, since education is supposed to be compulsory. They can't be bothered to investigate (and with today's hostile climate, I don't blame them) so they consign both parties to independent-study programs.
For volunteer projects, throwing both overboard is unfortunate but necessary stewardship. The drama either attracts destabilizes the entire project, which only exists as long as it remains fun for the maintainer. It's tragic, but victims who can't recover gracefully are as toxic as their abusers.
I don't understand why this is so difficult for software developers with GitHub accounts to understand.
I'm running in Windows using koboldcpp, maybe it's faster in Linux?
I tested it out both locally (6c/12t CPU) and on a Hetzner CPX41 instance (8 AMD cores, 16 GB of RAM, no GPU), the latter of which costs about 25 EUR per month and still can generate decent responses in less than half a minute, my local machine needing approx. double that time. While not quite as good as one might expect (decent response times mean maxing out CPU for the single request, if you don't have a compatible GPU with enough VRAM), the technology is definitely at a point where it's possible for it to make people's lives easier in select use cases with some supervision (e.g. customer support).
What an interesting time to be alive, I wonder where we'll be in a decade.
git clone https://github.com/jart/cosmopolitan
cd cosmopolitan
# cross-compile on x86-64-linux for x86-64 linux+windows+macos+freebsd+openbsd+netbsd
make -j8 o//third_party/ggml/llama.com
o//third_party/ggml/llama.com --help
# cross-compile on x86-64-linux for aarch64-linux
make -j8 m=aarch64 o/aarch64/third_party/ggml/llama.com
# note: creates .elf file that runs on RasPi, etc.
# compile loader shim to run on arm64 macos
cc -o ape ape/ape-m1.c # use xcode
./ape ./llama.com --help # use elf aarch64 binary above
Would love voice assistant running locally but probably there are solutions out there - didn't get to do the research yet
e.g.
https://replicate.com/stability-ai/stablelm-tuned-alpha-7b
https://github.com/runpod/serverless-workers/tree/main/worke...
And in general, your inference code will be compiled to a CPU/Architecture target - so you can know ahead of time what instructions you'll have access to when writing your code for that target.
For example in the case of AWS Lambda, you can choose graviton2 (ARM with NEON), or x86_64 (AVX). The trick is that for some processors such as Xeon3+ there is AVX 512, and others you will top out at AVX 256. You might be able to figure out what exact instruction set your serverless target supports.
There is a lull right now between gpt4 and gpt5 (literally and metaphorically). Consumer models are plateauing around 40B for a barely-reasonable RTX 3090 (ggml made this possible).
Now is the time to launch your ideas, all!
A matter of when, not if. I mean, the website itself makes that much clear:
The ggml way
...
Open Core
The library and related projects are freely available under the MIT license... In the future we may choose to develop extensions that are licensed for commercial use
Explore and have fun!
... Contributors are encouraged to try crazy ideas, build wild demos, and push the edge of what's possible
Won't blame anyone here though; because clearly, if you're as good as Georgi Gerganov, why do it for free?
I think it was originally designed to be easily embeddable—and most importantly, native code (i.e. not Python)—rather than competitive with GPUs.
I think it's just starting to get into GPU support now, but carefully.
That's correct, yeah. Q4_0 should be the smallest and fastest quantized model.
> I'm running in Windows using koboldcpp, maybe it's faster in Linux?
Possibly. You could try using WSL to test—I think both WSL1 and WSL2 are faster than Windows (but WSL1 should be faster than WSL2).
Today with the new k-quants users are reporting that 30B models are working with 2-bit quantization on 16GB CPUs and GPUs [2]. That's enabling access to millions of consumers and the optimizations will only improve from there.
[1] https://old.reddit.com/r/LocalLLaMA/comments/13q6hu8/7b_perf...
[2] https://github.com/ggerganov/llama.cpp/pull/1684, https://old.reddit.com/r/LocalLLaMA/comments/141bdll/moneros...
My old job title had "edge" in it, and I still don't know what it's supposed to mean, although "not cloud" is a good approximation.
I think the lesson here is that this setup has enabled some very high-speed project evolution or, at least, not got in its way. If that is surprising and you were expecting downsides, a) why; and b) where did they go?
An alternative method is to index content in a database and then insert contextual hints into the LLM's prompt that give it extra information and detail with which to respond with an answer on-the-fly.
That database can use semantic similarity (ie via a vector database), keyword search, or other ranking methods to decide what context to inject into the prompt.
PrivateGPT is doing this method, reading files, extracting their content, splitting the documents into small-enough-to-fit-into-prompt bits, and then indexing into a database. Then, at query time, it inserts context into the LLM prompt
The repo uses LangChain as boilerplate but it's pretty easily to do manually or with other frameworks.
(PS if anyone wants this type of local LLM + document Q/A and agents, it's something I'm working on as supported product integrated into macOS, and using ggml; see profile)
> ...lately we have been augmenting it with GPU support.
Would you say you'd then be building an equivalent to Google's JAX?
Someone even asked if anyone would build a C++ to JAX transpiler [0]... I am wondering if that's something you may implement? Thanks.
Did you give them a different answer? It is okay if you can't or don't want to share, but I doubt the company is only planning to have fun. Regardless, best of luck to you and thank you for your efforts so far.
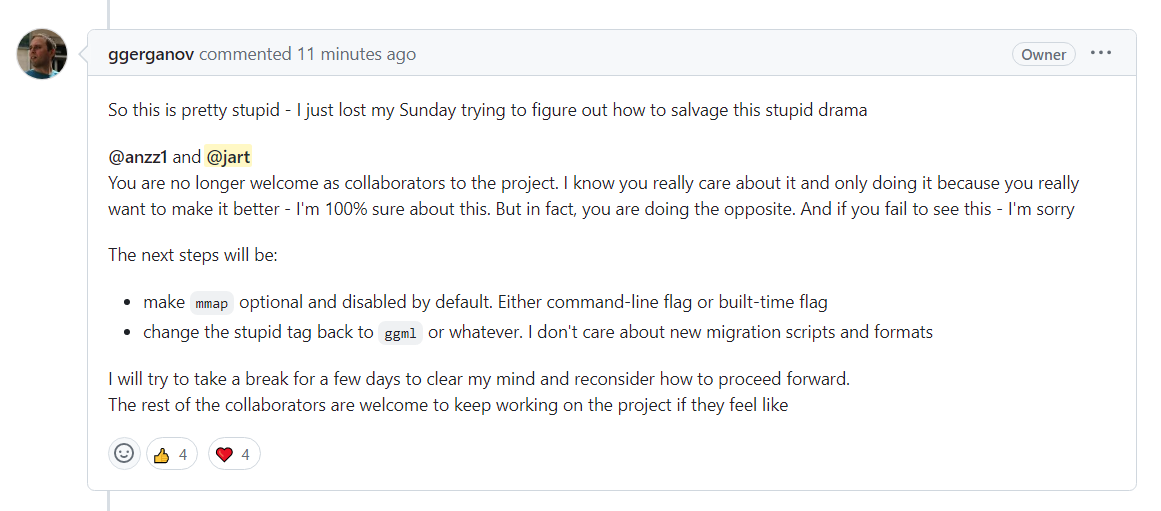
You don't have to take my word on it. Here are some archives of the 4chan threads where they coordinated the raid. It went on for like a month. https://archive.is/EX7Fq https://archive.is/enjpf https://archive.is/Kbjtt https://archive.is/HGwZm https://archive.is/pijMv https://archive.is/M7hLJ https://archive.is/4UxKP https://archive.is/IB9bv https://archive.is/p6Q2q https://archive.is/phCGN https://archive.is/M6AF1 https://archive.is/mXoBs https://archive.is/68Ayg https://archive.is/DamPp https://archive.is/DiQC2 https://archive.is/DeX8Z https://archive.is/gStQ1
If you read these threads and see how nasty these little monsters are, you can probably imagine how Gerganov must have felt. He was probably scared they'd harass him too, since 4chan acts like he's their boy. I wouldn't even be surprised if he's one of them. Plus it was weak leadership on his part to disappear for days, suddenly show up again to neutral knight the situation (https://justine.lol/neutral-knight.png) by telling his team members they're no longer welcome, and then going back and deleting his comment later. It goes to show that no matter how brilliant you are at hard technical skills, you can still be totally clueless about people.
Like I said, very modest
I'm happy with most of the abstractions. We are pushing to assembly codegen. And if you meant things like matrix accelerators, that's my next priority.
We are taking more a of breadth first approach. I think ggml is more depth first and application focused. (and I think Mojo is even more breadth first)
"I should point out that I wasn't personally involved, haven't looked into it in detail, and that there are many different perspectives that should be considered."
Here is the official commit undoing the change:
https://github.com/ggerganov/llama.cpp/pull/711/files#diff-7...
Core pieces: GPT4All (LLM interface/bindings), Chroma (vector store), HuggingFaceEmbeddings (for embeddings), and Langchain to tie everything together.
https://github.com/SamurAIGPT/privateGPT/blob/main/server/pr...
Really looks like some axe-grinding here, if I'm being honest. Especially because it takes very little effort to find out what the present header is by someone who can write software.
In short you can:
1) Run a local Willow Inference Server[1]. Supports CPU or CUDA, just about the fastest implementation of Whisper out there for "real time" speech.
2) Run local command detection on device. We pull your Home Assistant entities on setup and define basic grammar for them but any English commands (up to 400) are supported. They are recognized directly on the $50 ESP BOX device and sent to Home Assistant (or openHAB, or a REST endpoint, etc) for processing.
Whether WIS or local our performance target is 500ms from end of speech to command executed.
When advising start-ups who are taking on VC funding and the inevitable "business guidance" they push on founders I like to remind them that even the best investors are only good at investing. If they were good at business, they wouldn't bother with investing in other companies but instead start companies themselves since they would own 100% and maximize their returns.
llama.cpp is a project that uses ggml to run LLaMA, a large language model (like GPT) by Meta
whisper.cpp is a project that uses ggml to run Whisper, a speech recognition model by OpenAI
ggml's distinguishing feature is efficient operation on CPU. Traditionally, this sort of work is done on GPU, but GPUs with large amounts of memory are specialized and extremely expensive hardware. ggml achieves acceptable speed on commodity hardware.
It's easy to debug because the generated kernels can be compared to GGML, and still gives something practical that we all can play with.
At this point breadth first is a bit boring, because this way we don't know how far tinygrad is from optimal generated output.
% ./bin/gpt-2 -m models/gpt-2-117M/ggml-model.bin -p "Let's talk about Machine Learning now"
main: seed = 1686112244
gpt2_model_load: loading model from 'models/gpt-2-117M/ggml-model.bin'
gpt2_model_load: n_vocab = 50257
gpt2_model_load: n_ctx = 1024
gpt2_model_load: n_embd = 768
gpt2_model_load: n_head = 12
gpt2_model_load: n_layer = 12
gpt2_model_load: ftype = 1
gpt2_model_load: qntvr = 0
gpt2_model_load: ggml tensor size = 224 bytes
gpt2_model_load: ggml ctx size = 384.77 MB
gpt2_model_load: memory size = 72.00 MB, n_mem = 12288
gpt2_model_load: model size = 239.08 MB
extract_tests_from_file : No test file found.
test_gpt_tokenizer : 0 tests failed out of 0 tests.
main: prompt: 'Let's talk about Machine Learning now'
main: number of tokens in prompt = 7, first 8 tokens: 5756 338 1561 546 10850 18252 783
Let's talk about Machine Learning now.
The first step is to get a good understanding of what machine learning is. This is where things get messy. What do you think is the most difficult aspect of machine learning?
Machine learning is the process of transforming data into an understanding of its contents and its operations. For example, in the following diagram, you can see that we use a machine learning approach to model an object.
The object is a piece of a puzzle with many different components and some of the problems it solves will be difficult to solve for humans.
What do you think of machine learning as?
Machine learning is one of the most important, because it can help us understand how our data are structured. You can understand the structure of the data as the object is represented in its representation.
What about data structures? How do you find out where a data structure or a structure is located in your data?
In a lot of fields, you can think of structures as
main: mem per token = 2008284 bytes
main: load time = 366.33 ms
main: sample time = 39.59 ms
main: predict time = 3448.31 ms / 16.74 ms per token
main: total time = 3894.15 msIn my case, my local workstation has a Ryzen 5 1600 desktop CPU from 2017 (first generation Zen, 14nm) and it still worked decently.
Of course, response times would grow with longer inputs and outputs or larger models, but getting a response in less than a minute when running off of purely CPU is encouraging in of itself.
Would someone else have taken his place had he not been around? Maybe, but I'm insanely happy that he is around.
The amount of hours I've sunk into LLM's is crazy, and it's mostly thanks to his work that I can both run and download models in meaningful timeframes.
And yes, I have tested llama.cpp on my android and it works 100% on termux. (Your biggest enemy here will be Android process reaper when you hit the memory cap)
That's about 2 weeks after the drama around PR 613, which you factually touted as "your work" in several different places.
Daniel Gross set up a company that seemed akin to indebted servitude, modern day slavery. They called it "Pioneer" and later changed the terms, I guess because of backlash.
They gave you a little bit of money to "do whatever you want" but owned a huge stake in anything you did in the future for a long period of time. They didn't advertise that part very heavily, they mostly portrayed it as "we're doing this because we're philanthropists" imo, rather than because they wanted to reinvent indentured servitude within the modern legal framework.
Why do I write these posts? Because I desperately want to believe we can get rich without doing dishonest, evil things. Maybe I'm wrong. Maybe that's why all these guys behave this way. Maybe it really is never enough.
You could consider that the real edge, whereas edge computing often means 'at the edge of the cloud' i.e. local CDN node
Look, my message is simple and clear: keep the politics and drama out of it. If you partake in politics and drama, you'll be ejected from the project. I don't have the time or the energy to police or play games with people. We're here to build things, not to partake in social activism or sling crap at each other over codes of conduct, pronouns, hair color or magic strings. If you're hurt - fork the project (as long as the license allows for it) and have fun playing somewhere else.
It’s pretty good as models of that size go, although it doesn’t take a lot of playing around with it to find that there’s still a good distance between it and ChatGPT 3.5.
(I do recommend editing the instructions before playing with it though; telling a model this size that it “always tells the truth” just seems to make it overconfident and stubborn)
Also from the links you shared it looked like some users on 4chan decided to go out and harass you. If they didn't know you are a trans woman, I'm sure they would've defaulted to calling you a n***** f***** instead. But they were going to harass you nonetheless.
It was very sad to see how things developed over a small issue. I'm sure this could've gotten resolved civilly since I believe you and everyone else involved in the project had good intentions and were doing everything out of love.
Fine-tuning is like having the model take a class on a certain subject. By the end of the class, it's going to have a general understanding on how to do that thing, but it's probably going to struggle when trying to quote the textbooks verbatim.
A good use-case for fine-tuning is teaching it a response style or format. If you fine-tune a model to only respond in JSON, then you no longer need to include formatting instructions in your prompt to get a JSON output.
From what I see, the foundation is there for a great multimodal platform. Very excited to see where this goes.
I am expecting such high expectations like that to end in disappointment for the 'community' since the interests will now be in the VCs to head for the exit. Their actions will speak more than what they are saying on the website.
If a bunch of random strangers (external to the project) are messing with your tools and workflows (stirring things up in the issue tracker, creating drama and playing games with silly Pull Requests and comments) - lock down your tools such that they can only be used by trusted members of your team. Close down and remove all bullshit conversations without spending any further time or energy on any of it. Platforms like GitHub blur the lines between "a suite of productivity tools for software development" and "a social network" - so make sure to lock down and limit the "social networks" aspects whilst optimizing for the "software development productivity" aspect. Go on with your life and continue building.
If the "attacks" happens internally within the project (between two or more members of the team) - eject all parties involved because they're clearly not here to build stuff. Go on with your life and continue building.
Your goal should be to spend your energy on building and creating, and collaborating with like-minded people on building and creating. Not on policing, moderating, or playing games with people.
In other words, it’s like having a spouse/partner. There are certain ways that we communicate that we simply know where the other person is at or what they actually mean.
W = W0 + B A
Where W0 is the trained model’s weights, which are kept fixed, and A and B are matrices but with a much much lower rank than the originals (say r = 4).
It has been shown (as mentioned in the lora paper that training for specific tasks results in low rank corrections, so this is what it is all about. I think that doing LoRa can be done locally.
Even if you're using OpenAI's models, gpt-3.5-turbo is going to be much better (cheaper, bigger context window, higher quality) than any of their models that can be fine-tuned.
But if you're able to fine-tune a local model, then a combination of fine-tuning and embedding is probably going to give you better results than embedding alone.
I wonder if they came to him or if someone else facilitated it as opposed to it being his initiative.
This user stole another user's code, closed his PR, and opened a new one where she started using words like "my work," "I'm the author," "author here," etc., and trying to cozy up to the project lead.
Gerganov figured out what was happening and actually banned her from all further contributions. The user whose code was stolen, Slaren, is still contributing.
----
That's not the original PR. jart was working on a malloc() approach that didn't work and slaren wrote all the code actually doing mmap, which jart then rebased in a random new PR, changed to support an unnecessary version change, magic numbers, a conversion tool, and WIN32 support when that was already working in the draft PR. https://archive.ph/Uva8c
This is the original PR: https://github.com/ggerganov/llama.cpp/pull/586.
Jart's archived comments:
"my changes"
"Here's how folks in the community have been reacting to my work."
"I just wrote a change that's going to let your LLaMA models load instantly..."
"I'm the author"
"Author here..."
"Tragedy of the commons...We're talking to a group of people who live inside scientific papers and jupyer notebooks."
"My change helps inference go faster."
"The point of my change..."
"I stated my change offered a 2x improvement in memory usage."
"I can only take credit for a 2x recrease in RAM usage."
"I just wrote a change that's going to let your LLaMA models load instantly, thanks to custom malloc() and the power of mmap()"
slaren replied to jart on HN asking her why she was doing and saying those things, and she didn't bother to reply to him, despite replying to others in that subthread within minutes. https://archive.ph/zCfiJ
----
You didn't make whole the people you damaged or the project you attempted to harm with plagiarism and pathological levels of manipulation and lying.
This user claims Gerganov publicly humiliated her, but she does it to herself.
{kind=link}