I know for a fact that’s not true. You must have misunderstood the issue.
This is one of the main technical differences between Azure Functions and Google Cloud Run vs Lambda. Azure and GCP offer serverless as a billing model rather than an execution model precisely to avoid this issue. (Among many other benefits*)
Both in Azure and GCP you listen and handle SIGTERM (on Linux at least, Azure has a Windows offering and you use a different Windows thing there that I’m forgetting) and you can control and handle shutdown. There is no “suspend”. “Suspending nodejs” is not a thing. This is a super AWS Lambda specific behavior that is not replicable outside AWS (not easily at least)
The main thing I do is review cloud issues mid size companies run into. Most of them were startups that transitioned into a mid size company and now need to get off the “Spend Spend Spend” mindset and rain in cloud costs and services. The first thing we almost always have to untangle is their Lambdas/SF and it’s always the worst thing to ever untangle or split apart because you will forever find your code behavior differently outside of AWS. Maybe if you have the most excellent engineers working with the most excellent processes and most excellent code. But in reality all Lambda code takes complete dependency on the fact that lambda will kill your process after a timeout. Lambda will run only 1 request through your process at any given time. Lambda will “suspend” and “resume” your process. 99% of lambdas I helped move out of AWS have had a year+ trail of bugs where those services couldn’t run for any length of time before corrupting their state. They rely on the process restarting every few request to clear up a ton of security-impacting cross contamination.
* I might be biased, but I much much prefer GCR or AZF to Lambda in terms of running a service. Lambda shines if you resell it. Reselling GCR or AZF as a feature in your application is not straight forward. Reselling a lambda in your application is very very easy
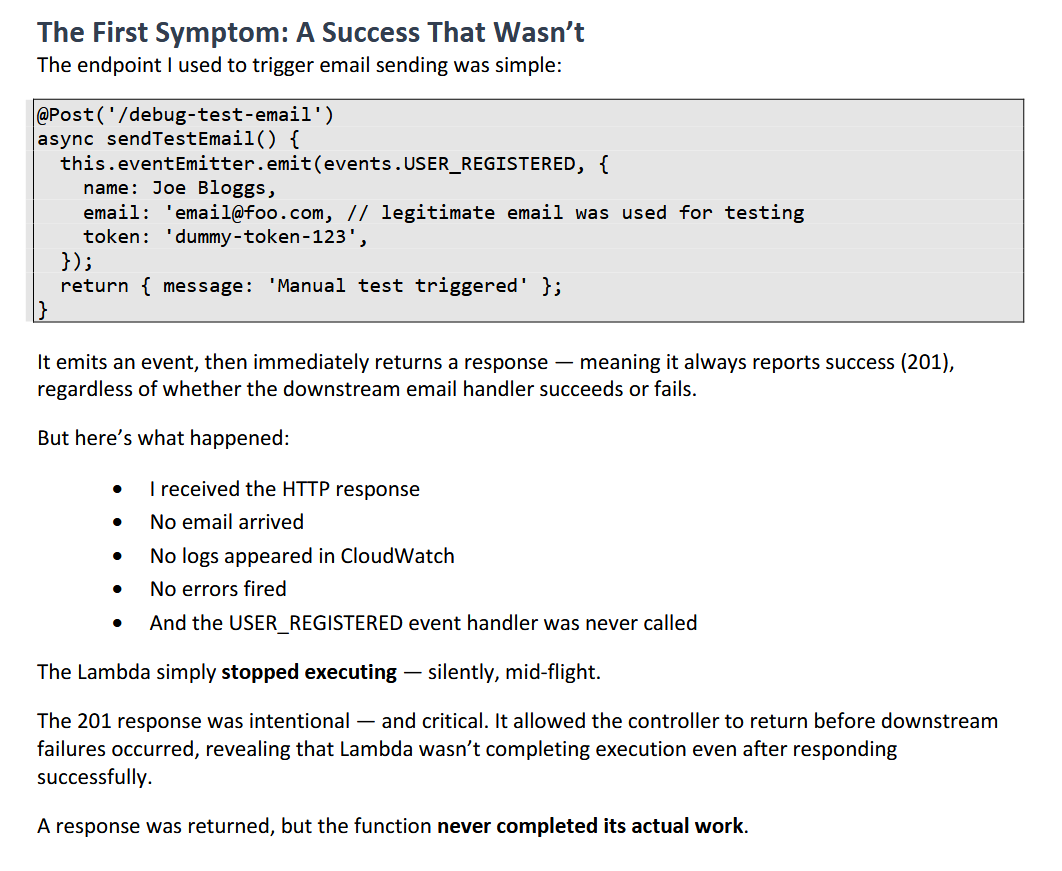{kind=link}