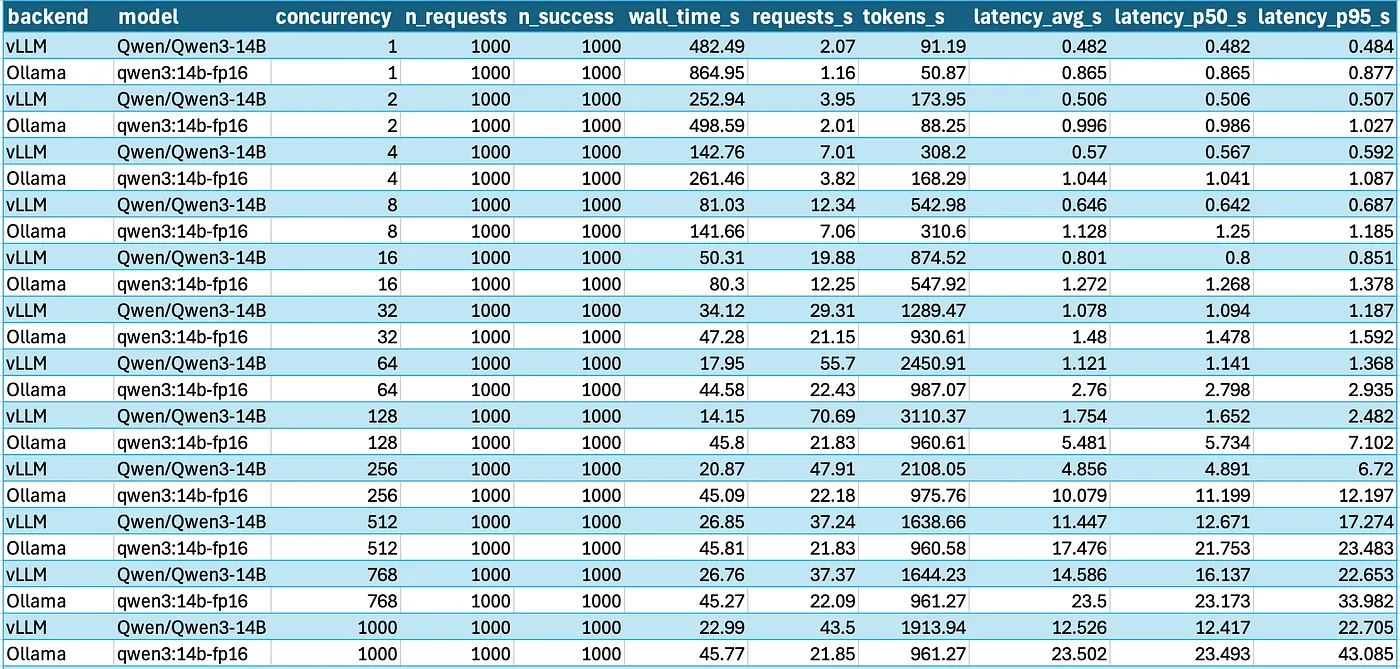
later found vllm uses paged kv cache with layout that matches how the GPU wants to read fully coalesced without strided jumps. llama.cpp was using a flat layout that’s fine for single prompt but breaks L2 access patterns when batching.
reshaped kv tensors in llama.cpp to interleave ; made it [head, seq, dim] instead of [seq, head, dim], closer to how vllm feeds data into fused attention kernel. 2x speedup right there w.r.t same ops.
GPU was never the bottleneck. it was memory layout not aligning with SM’s expected access stride. vllm just defaults to layouts that make better use of shared memory and reduce global reads. that’s the real reason it scales better per batch.
this took its own time of say 2+days and had to dig under the nice looking GPU graphs to find real bottlenecks, it was widly trial and error tbf,
> anybody got idea on how to do this kinda experiment in hot reload mode without so much hassle??
{kind=link}