Not open beta until Q1 2025
I’m curious how they’re doing it. Obviously the standard bag of tricks (eg, speculative decoding, flash attention) won’t get you close. It seems like at a minimum you’d have to do multi-node inference and maybe some kind of sparse attention mechanism?
In other words, if you wanted to run 8 separate 70b models on your cluster, each of which would fit into 1 GPU, how much larger your overall token output could be than parallelizing 1 model per 8 GPUs and having things slowed down a bit due to NVLink?
They have limited memory on chip (all SRAM) and it's not clear how much HBM bandwidth they have per wafer. It's a completely different optimization problem than running on GPU clusters.
I recommend the TechTechPotato YouTube videos on Cerebras to understand more of their chip design.
From what I understand, several, maybe all, of the comparison services are not based on provisioned capacity, which means that the measurements include the queue time. For LLMs this can be significant. The Cerebras number on the other hand almost certainly doesn't have some unbounded amount of queue time included, as I expect they had guaranteed hardware access.
The throughput here is amazing, but to get that throughput at a good latency for end-users means over-provisioning, and it's unclear what queueing will do to this. Additionally, does that latency depend on the machine being ready with the model, or does that include loading the model if necessary? If using a fine-tuned model does this change the latency?
I'm sure it's a clear win for batch workloads where you can keep Cerebras machines running at 100% utilisation and get 1k tokens/s constantly.
So if I had to guess a 96GB H100 could probably run it at fp8 as long as you didn’t need a big context window. If you’re doing speculative decoding it probably won’t fit because you also need weights and kv cache for the draft model.
There are so many interactive experiences that could be made possible at this level of token throughput from 405B class models.
https://www.youtube.com/@TechTechPotato/search?query=cerebra... for anyone also looking. there are quite a lot of them.
but 8x h100 are ~2.6-5.2kw (I get conflicting info, I think based on pice vs smx) so anywhere between roughly even and up to 2x efficient.
Groq has paying customers below the enterprise-level and actually serves all their models to everyone in a wide berth, unlike Cerebras who is very selective, so they have that going for them. But in terms of sheer speed and in the largest models, Groq doesn't really compare.
(yeah, I know they are doing textual tokens. but just sayin..)
edit: context is https://oasisaiminecraft.com/
Looks like an H100 runs about $30K online for one. Are there any issues with just sticking one of these in a stock desktop PC and running llama.cpp?
You can also get a lot fancier with tool-usage when you can start getting an LLM to use and reply to tools at a speed closer to the speed of a normal network service.
I've never timed it, but I'm guessing current LLMs don't handle "live video" type applications well. Imagine an LLM you could actually video chat with - it'd be useful for walking someone through a procedure, or advanced automation of GUI applications, etc.
AND the holy-grail of AI applications that would combine all of this - Robotics. Today, Cerebras chips are probably too power hungry for battery powered robotic assistants, but one could imagine a Star-Wars style robot assistant many years from now. You can have a robot that can navigate some space (home setting, or work setting) and it can see its environment and behavior, processing the video in real-time. Then, can reason about the world and its given task, by explicitly thinking through steps, and critically self-challenging the steps.
However, given that CoT makes models a lot smarter, I think Cerebras chips will be in huge demand from now on. You can have a lot more CoT runs when the inference is 20x faster.
Also, I assume financial applications such as hedge funds would be buying these things in bulk now.
https://www.servethehome.com/a-cerebras-cs-2-engine-block-ba...
Thing is nearly all cooling. And look at the diameter on the water cooling pipes. Airflow guides on the fans are solid steel. Apparently the chip itself measures 21.5cm^2. Insane.
The other thing people don’t seem to be getting in this thread that just to hold the weights for 405B at FP16 requires 19 of their systems since it is SRAM only… rounding up to 20 to account for program code + KV cache for the user context would mean 20 systems/racks, so well over $20M. The full rack (including support equipment) also consumes 23kW, so we are talking nearly half a megawatt and ~$30M for them to be getting this performance on Llama 405B
Such a system would be limited by the latency across the reported 126 layers worth of math involved, before it could generate the next token, which might be as much as 100 uSec. So it would be 10x faster, but you could have thousands of other independent streams pipelined through in parallel because you'd get a token per clock cycle out the end.
In summary, 1 Gigatoken/second, divided into 100,000 separate users each getting 10k tokens/second.
This is the future I want to build.
The limiting factor with GPU for inference is memory bandwidth. For 969 tok/s in int8, you need 392 TB/s memory bandwidth or 200 H100s.
My guess is that would 10X the performance. But then it's a very very expensive solution.
Improving flops is the most obvious way to improve speed, but I think we're pretty close to physical limits for a given process node and datatype precision. It's hard to give proof positive of this, but there are a few lines of evidence. One is that the fundamental operation of LLMs, matrix multiplications, are really simple (unlike e.g. CPU work) and so all the e.g. control flow logic is pretty minimized. We're largely spending electricity on doing the matrix multiplications themselves, and the matrix multiplications are in fact electricity-bound[1]. There are gains to be made by changing precision, but this is difficult and we're close to tapped out on it in my opinion (already very low precisions (fp8 can't represent 17), new research showing limitations).
Efficiency in LLM training is measured with a very punishing standard, "Model Flops Utilization" (MFU), where we divide the theoretical number of flops the hardware could provide with the theoretical number of flops necessary to implement the mathematical operation. We're able to get 30% without thinking (just FSDP) and 50-60% are not implausible/unheard of. The inefficiency is largely because 1) the hardware can't provide the number of flops it says on the tin for various reasons and 2) we have to synchronize terabytes of data across tens of thousands of machines. The theoretical limit here is 2x but in practice there's not a ton to eke out here.
There will be gains but they will be mostly focused on reducing NVIDIA's margin (TPU), on improving process node, on reducing datatype (B100), or on enlarging the size of a chip to reduce costly cross-chip communication (B100). There's not room for a 10x (again at constant precision and process node).
[1]: https://www.thonking.ai/p/strangely-matrix-multiplications
I'm not talking about that. I and many others here have spun up 8x or more H100 clusters and run this exact model. Zero other traffic. You won't come anywhere close to this.
My recollection from PC CPUs is that we've gotten many more operations per second, and many more operations per second per dollar, but that the power and corresponding cooling requirements for the CPUs have tended to go up as well. I don't really know what power per operation has looked like there. (I guess it's clearly improved, though, because it seems like the power consumption of a desktop PC has only increased by a single order of magnitude, while the computational capacity has increased by more than that.)
A reason that I wonder about this in this context is that people are saying that the power and cooling requirements for these devices are currently enormous (by individual or hobbyist standards, not by data center standards!). If we imagine a Moore's Law-style improvement where the hardware itself becomes 1/10 or 1/100 of its current price, would we expect the overall power consumption to be similarly reduced, or to remain closer to its current levels?
Take a look at https://fuse.wikichip.org/news/3010/a-look-at-cerebras-wafer... and specifically the diagram https://fuse.wikichip.org/wp-content/uploads/2019/11/hc31-ce...
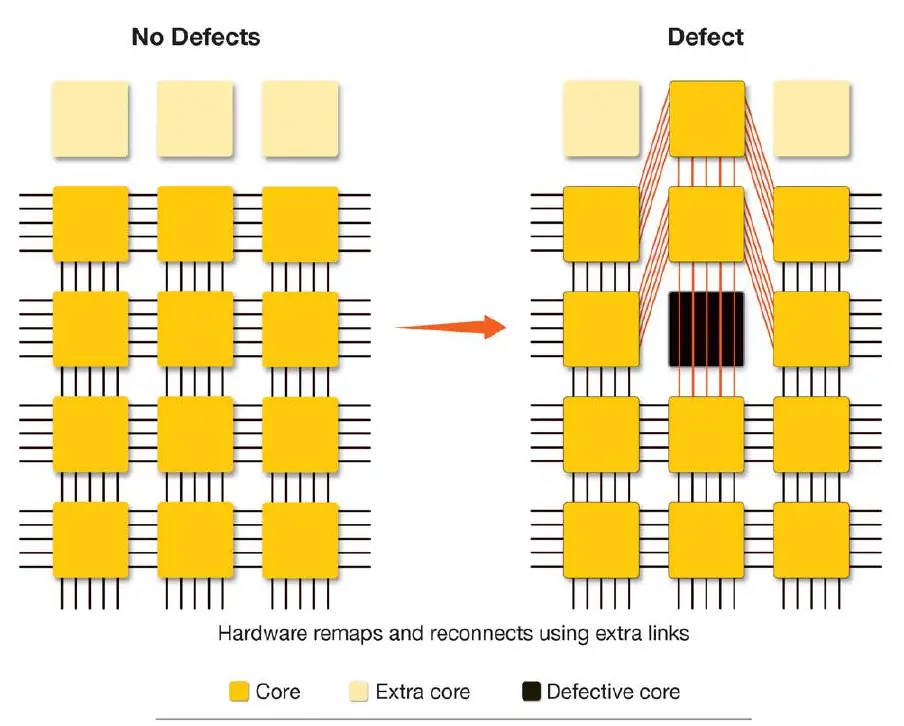
The fabric can effectively route signals diagonally to work around an individual defective core, with a displacement of one position for cores in the same row from that defect over to the nearest spare core. That's how they get away with a claimed "1–1.5%" of spare cores.
Cooling might be a challenge. The H100 has a heatsink designed to make use of the case fans. So you need a fairly high airflow through a part which is itself passive.
On a server this isn't too big a problem, you have fans in one end and GPU's blocking the exit on the other end, but in a desktop you probably need to get creative with cardboard/3d printed shrouds to force enough air through it.
Which is why they throttle your requests
What I take away from this is: we are just getting started. I remember in 2023 begging OpenAI to give us more than 7 tokens/second on GPT-4.
Ilya Sutskever to Elon Musk, Sam Altman, (cc: Greg Brockman, Sam Teller, Shivon Zilis) - Sep 20, 2017 2:08 PM
> In the event we decide to buy Cerebras, my strong sense is that it'll be done through Tesla. But why do it this way if we could also do it from within OpenAI?
Cost reduction for cutting-edge products in the semiconductor industry has historically been driven by 1) reducing transistor size (by following the Dennard scaling laws), and 2) a variety of techniques (e.g. high-k dielectrics and strained silicon, or FinFETs and now GAAFETs) to improve transistor performance further. These techniques added more steps during manufacturing, but they were inexpensive enough that they allowed to reduce $/transistor still. In the last few years, we've had to pull off ever more expensive tricks which stopped the $/transistor progress. This is why the phrase "Moore's law is dead" has been circulating for a while.
In any case, higher performance transistors means that you can get the same functionality for less power and a smaller area, meaning that iso-functionality chips are cheaper to build in bulk. This is especially true for older nodes, e.g. look at the absurdly low price of most microcontrollers.
On the other hand, $/wafer is mostly a volume-related metric based on less scalable technology and more conventional manufacturing (relatively speaking). Cerebra's innovation was in making a wafer-scale chip possible, which is conventionally hard due to unavoidable manufacturing defects. But crucially, such a product (by definition) cannot scale like any other circuit produced so far.
It may for sure drop in price in the future, especially once it gets obsolete. But I don't expect it to ever reach consumer level prices.
I don't know if we can extrapolate, but I can imagine AI inference on our desktops for $500 in a few years...
I assume they're using SRAM only to achieve this speed and not HBM.
Hence why you see AMD's MI325x coming out with 256GB HBM3e, but it is the same FLOPs as a 300x. 6TB/s too, which outperforms H200's, by a lot.
You can see the direction AMD is going with this...
https://www.amd.com/en/products/accelerators/instinct/mi300/...
I love to see the development and activity, but companies like Cerebras are trying to compete on a single usecase and doing a poor job of it because they can only offer a tightly controlled API.
Ask yourself how much capex + power/space/cooling (opex) it requires to run that model (and how many people it can really serve) and then compare that against what AMD is offering.
[0] https://www.amd.com/en/products/accelerators/instinct/mi300/...
The main reason why Cerebras has succeeded and the previous attempts have failed is not technical, but the existence of market demand.
Before ML/AI training and inference, there has been no application where wafer-scale chips could provide enough additional performance to make their high cost worthwhile.
I think that math is only valid for batch size = 1. When these 969 tokens/second come from multiple sessions of the same batch, loaded model tensor elements are reused to compute many tokens for the entire batch. With large enough batches, you can even saturate compute throughput of the GPU instead of bottlenecking on memory bandwidth.
They are inherently parallel, so you might be able to get a token per clock cycle. A billion tokens per second opens quite a few possibilities.
It could also eliminate all of the multiplication or addition of bits that are 0 from the design, making each multiply smaller by 50 percent silicon area, on average.
However, an ASIC is a speculation that all the design tools work. It may require multiple rounds to get it right.
Looks like other folks get 80 tok/s with max batch size, that's surprising to me but vLLM is definitely more optimized than my implementation.
As for retail pricing being $2.5 million, I read $2 million in a news article earlier this year. $2.5 million makes it sound even worse.
By the way, I am a software developer, so you will not see me challenging their patent. I am just curious.
https://x.com/draecomino/status/1858998347090325846
That said, they appear to be giving the per user performance.
I have some local code running llama 3 8B and matrix multiplications in it are being done by 2D matrices with dimensions ranging from 1024 to 4096. Let’s just go with a nice 1024x1024 matrix and do matrix-vector multiplication, which is the minimum needed to implement llama3. That is 1048576 elements. If you try to do matrix-vector multiplication in 1 cycle, you will need 1048576 fmadd units.
I am by no means a chip designer, so I asked ChatGPT to estimate how many transistors are needed for a bf16 fmadd unit. It said 100,000 to 200,000. Let’s go with 100,000 transistors per unit. Thus to implement a single matrix multiplication according to your idea, we would need over 100 billion transistors, and this is only a small part of the llama 3 8b model’s calculations. You would probably be well into the trillions of transistors if you implemented all of it in an ASIC and did 1 layer per cycle (don’t even think of 1 token per cycle). For reference, Nvidia’s H100 has 80 billion transistors. The CSE-3 has 4 trillion transistors and I am not sure if even that would be enough.
It is a nice idea, but I do not think it is feasible with current technology. That said, I do like your out of box thinking. This might be a bit too far out of the box, but there is probably a middle ground somewhere.
Or is the rulebook a simple rollback?
The key to this, in my view, is to give up on the idea of trying to get the latency as low as possible for a given piece of computation, as it typically done, and instead try to make reliable small cells that are clocked so that you don't have to worry about getting data far or fast. Taking this idea to its limits has a completely homogeneous systolic array that operates on 4 bits at a time, using look up tables to do everything. No dedicated switching fabric, multipliers, or anything else.
It's the same tradeoff von Neumann made with the ENIAC, which slowed it down by a factor of 6 (according to wikipedia), but eliminating multiple weeks of human labor in setup by instead loading stored programs effectively instantly.
To multiply numbers, you don't have to do all of it at the same time, you just have to pipeline the steps so that all of them are taking place for part of the data, and it all stays synced (which the clocking again helps)
Since I'm working alone, right now I'm just trying to get something that other people can grok, and play with.
Ideally, I'd have chips with multiple channels of LVDS interfaces running at 10 Gbps or more each to allow meshing the chips. Mostly, they'd be vast strings of D flip flops and 16:1 multiplexers.
I'm well aware of the fact that I've made arbitrary choices, and they might not be optimal for real world hardware. I do remain steadfast in my opinion that providing a better impedance match between the computing substrate and the code that runs on it could allow multiple orders improvement in efficiency. Not to mention the ability to run the exact same code on everything from an emulator to every successive version/size of the chip, without recompilation.
Not to mention being able to route around bad cells, actually build "walls" around code with sensitive info, etc.
> Memory bandwidth for inferencing does not scale with the number of GPU
It does
Inferencing is memory bandwidth bound. Add more GPUs on a batch size 1 inference problem and watch it run no faster than the memory bandwidth of a single GPU. It does not scale across the number of GPUs. If it could, you would see clusters of Nvidia hardware outperforming Cerebras’ hardware. That is currently a fantasy.
https://github.com/lyogavin/airllm
However, it will be far slower as you said.
[1]: https://lmsys.org/blog/2024-07-25-sglang-llama3/?ref=blog.ru...
[2]: https://www.snowflake.com/engineering-blog/optimize-llms-wit...
{kind=link}
{kind=link}