I wonder what he will be working on?
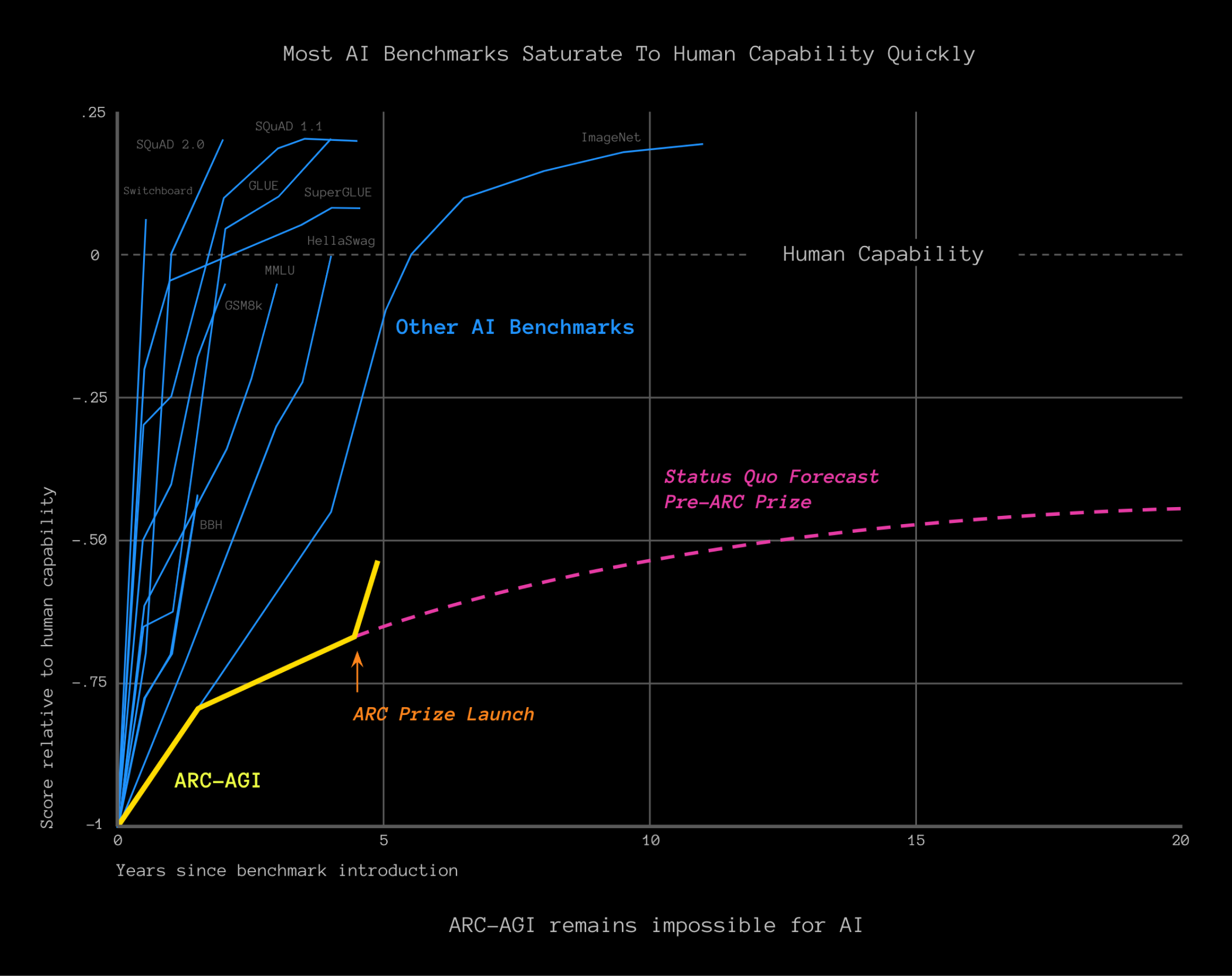
Maybe he figured out a model that beats ARC-AGI by 85%?
replies(1):
Maybe he figured out a model that beats ARC-AGI by 85%?
People have, I think.
One of the published approaches (BARC) uses GPT-4o to generate a lot more training data.
The approach is scaling really well so far [1], and whether you expect linear scaling or exponential one [2], the 85% threshold can be reached, using the "transduction" model alone, after generating under 2 million tasks ($20K in OpenAI credits).
Perhaps for 2025, the organizers will redesign ARC-AGI to be more resistant to this sort of approach, somehow.
---
[1] https://www.kaggle.com/competitions/arc-prize-2024/discussio...
[2] If you are "throwing darts at a board", you get exponential scaling (the probability of not hitting bullseye at least once reduces exponentially with the number of throws). If you deliberately design your synthetic dataset to be non-redundant, you might get something akin to linear scaling (until you hit perfect accuracy, of course).
If the ARC-AGI challenge did not actually follow their expected graph[1], I see no reason to believe that any benchmark can be designed in a way where it cannot be gamed. Rather, it seems that the existing SOTA models just weren't well-optimized for that one task.
The only way to measure "AGI" is in however you define the "G". If your model can only do one thing, it is not AGI and doesn't really indicate you are closer, even if you very carefully designed your challenge.
There is no reason to believe that technique would not work for any particular problem. After all, this problem was the best attempt the (very intelligent) challenge designers could come up with, as evidenced by putting $1m on the line.
In fairness, their approach is non-trivial. Simply asking GPT-4o to fantasize more examples wouldn't have worked very well. Instead, they have it fantasize inputs and programs, and then run the programs on the inputs to compute the outputs.
I think it's a great contribution (although I'm surprised they didn't try making an even bigger dataset -- perhaps they ran out of time or funding)
{kind=link}