The image compression model used in SD is not evenly (in a spatial sense) compressing the images
† As in, move a random vertical stripe of the image from the right to the left, and a random horizontal portion from the top to the bottom. Or, if that introduces unacceptable edge effects, simply slice the space into 4 randomly sized spaces (although that might encourage smuggling in all of the corners at once.)
Is that what KL divergence does?
I thought it was supposed to (when combined with reconstruction loss) “smooth” the latent space out so that you could interpolate over it.
Doesn’t increasing the weight of the KL term just result in random output in the latent; eg. What you get if you opt purely for KL divergence?
I honestly have no idea at all what the OP has found or what it means, but it doesnt seem that surprising that modifying the latent results in global changes in the output.
Is manually editing latents a thing?
Surely you would interpolate from another latent…? And if the result is chaos, you dont have well clustered latents? (Which is what happens from too much KL, not too little right?)
I'd feel a lot more 'across' this if the OP had demonstrated it on a trivial MNIST vae with both the issue, the result and quantitatively what fixing it does.
> What are the implications?
> Somewhat subtle, but significant.
Mm. I have to say I don't really get it.
I enjoyed the write up.
At the core of a latent diffusion model is a de-noising process. It takes a noisy image and predicts what is noise vs what is the real image without noise. You use this to remove a bit of noise from the image and repeat to iteratively denoise an image.
You can use this to generate entirely new images by just starting with complete random noise and denoising til you get a 'proper' image. Obviously this would not give you any control over what you generated. So you incorporate 'guidance' which controls how the denoise works. For stable diffusion this guidance comes from a different neural network called CLIP (https://openai.com/research/clip) which can take some text and produce a numerical representation of it that can be correlated to an image of what the text describes (I won't go into more detail here as it's not really relevant to the VAE).
The problem you have with the denoising process is the larger the image you want to denoise the bigger the model you need, and even at a modest 512x512 (the native resolution of stable diffusion) training the model is far too expensive.
This is where the latent bit comes in. Rather than train your model on a 512x512x3 representation (3 channels R,G,B per pixel) use a compressed representation that is 64x64x4, significantly smaller than the uncompressed image and thus requiring a significantly smaller denoising model. This 64x64x4 representation is known as the 'latent' and it is said to be in a 'latent space'.
How do we produce the latent representation? A VAE, a variational autoencoder, yet another neural network. You train an encoder and decoder together to encode an image to the 64x64x4 space and decode it back to 512x512x3 with as little loss as possible.
The issue pointed out here is the VAE for stable diffusion has a flaw, it seems to put global information in a particular point of the image (to a crude approximation it might store information like 'green is the dominant colour of this image' in that point). So if you touch that point in the latent you effect the entire image.
This is bad because the denoising network is constructed in such a way that it expects that points close in the latent only effect other points close in the latent. When that's not the case it ends up 'wasting' a bunch of the network on extracting that global data from that point and fanning it out to the rest of the image (as the entire image needs to know it to denoise correctly).
So without this flaw it may be the stable diffusion denoising model could be more effective as it doesn't need to work hard to work around the flaw.
Edit: Pressed enter too early, post is now complete.
Definitely a fascinating write-up. I have been curious about these differences for a while, though I had never considered this a "problem" per se.
> Is that what KL divergence does?
KL divergence is basically a distance "metric" in the space of probability distributions. If you have two probability distributions A and B, you can ask how similar they are. "Metric" is in scare quotes because you can't actually get a distance function in the usual sense. For example, dist(A,B) != dist(B,A).
If you think about the distribution as giving information about things, then the distance function should say two things are close if they provide similar information and are distant if one provides more information about something than the other.
The comment claims (and I assume they know what they're talking about) that after training we want the KL divergence to be close to a standard Gaussian. So that would mean that our statistical distribution gives roughly the same information as a standard Gaussian. It sounds like this distribution has a whole lot of information in one heavily localized area though (or maybe too little information in that area, I'm not sure which way it goes).
It only happens in one specific spot: https://i.imgur.com/8DSJYPP.png and https://i.imgur.com/WJsWG78.png. The fact that a single spot in the latent has such a huge impact on the whole image is not a good thing, because the diffusion model will treat that area as equal to the rest of the latent, without giving it more importance. The loss of the diffusion model is applied at the latent level, not the pixel level, so that you don't have to propagate the gradient of the VAE decoder during the training of the diffusion model, so it's unaware of the importance of that spot in the resulting image.
A few I’ve seen are:
- The goal should be to have latent outputs as closely resemble gaussian distributed terms between -1 and 1 with a variance of 1, but the outputs are unbounded (you could easily clamp or apply tanh to force them to be between -1 and 1), and the KL loss weight is too low, hence why the latents are weighed by a magic number to more closely fit the -1 to 1 range before being invested by the diffusion model.
- To decrease the computational load of the diffusion model, you should reduce the spatial dimensions of the input - having a low number of channels is irrelevant. The SD VAE turns each 8x8x3 block into a 1x1x4 block when it could be turning it into a 1x1x8 (or even higher) block and preserve much more detail at basically 0 computational cost, since the first operation the diffusion model does is apply a convolution to greatly increase the number of channels.
- The discriminator is based on a tiny PatchGAN, which is an ancient model by modern standards. You can have much better results by applying some of the GAN research of the last few years, or of course using a diffusion decoder which is then distilled either with consistency or adversarial distillation.
- KL divergence in general is not even the most optimal way to achieve the goals of a latent diffusion model’s VAE, which is to decrease the spatial dimensions of the input images and have a latent space that’s robust to noise and local perturbations. I’ve had better results with a vanilla AE, clamping the outputs, having a variance loss term and applying various perturbations to the latents before they are ingested by the decoder.
"Nice post, you'd be surprised at the number of errors like this that pop up and persist.
This is one reason we have multiple teams working on stuff..
But you still get them"
I'm curious why 4? Is this just what works in practice, or do the 4 channels have known interpretations?
Some background reading on generic VAE https://towardsdatascience.com/intuitively-understanding-var..., see "Optimizing using pure KL divergence loss".
Perhaps the SD 'VAE' uses a different architecture to a normal vae...
It's not uncommon to find major problems with these systems, I remember inspecting the VQGAN used by Dalle Mega (the largest version of Dalle Mini) and discovering that the vast majority of entries in the codebook had a magnitude very close to zero, making them completely unusable by the model.
Here, the target distribution is defined as the unit gaussian and this is defined as the point of zero information (the prior). The KL between the output of the encoder and the prior is telling us how much information can flow from the encoder to the decoder. You don't want the KL to be zero, but usually fairly close to zero.
You can think of the KL as the number of bits you would like to compress your image into.
There's no question the OP found a legit issue. The questions are more like:
1) What caused it?
2) How do you fix it?
3) What result would fixing it actually have?
That's just hilarious
I think you are radically overstating how obvious some of these things are.
What you call "just threw the VAE in there using the default options from the original VAE paper" is what another person might call "used a proven reference implementation, with the settings recommended by its creator"
Sure, there are design flaws with SD1.0 which feel obvious today - they've published SDXL and having read the paper, I wouldn't even consider going about such a project without "Conditioning the Model on Cropping Parameters". But the truth is this stuff is only obvious to me because someone else figured it out and told me.
https://twitter.com/Ethan_smith_20/status/175306260429219874...
I think what would happen if this problem was fixed is that the VAE would produce less appealing more blurry images. This is a classic problem with VAEs. So, more mathematically correct, but less visually appealing.
n.b. clarifying because most of the top comments currently are recommending this person is hired / inquiring if anyones begun work to leverage their insights: they're discussing known issues in a 2 year old model as if it was newly discovered issues in a recent model. (TFA points this out as well)
https://twitter.com/MosaicML/status/1617944401744957443?lang...
This probably got even better and cheaper.
IMO the ability for a NN to compensate for bugs and unfounded assumptions in the model isn't a Good Thing in the slightest. Building latent-space diagnostics that can determine whether a network is wasting time working around bugs sounds like a worthwhile research topic in itself (and probably already is.)
The only thing that is scary is the hype, because this will make people sloppily use deep learning architectures for problems that do not need that level of expressive power, and because deep learning is challenging and not theoretically well understood, there will be little to no attempts made to ensure safe operation/quality assurance of the implemented solution.
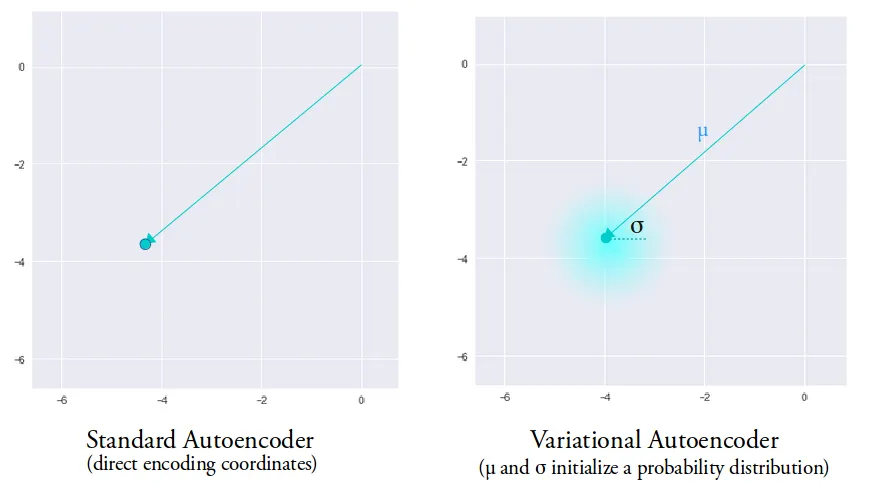
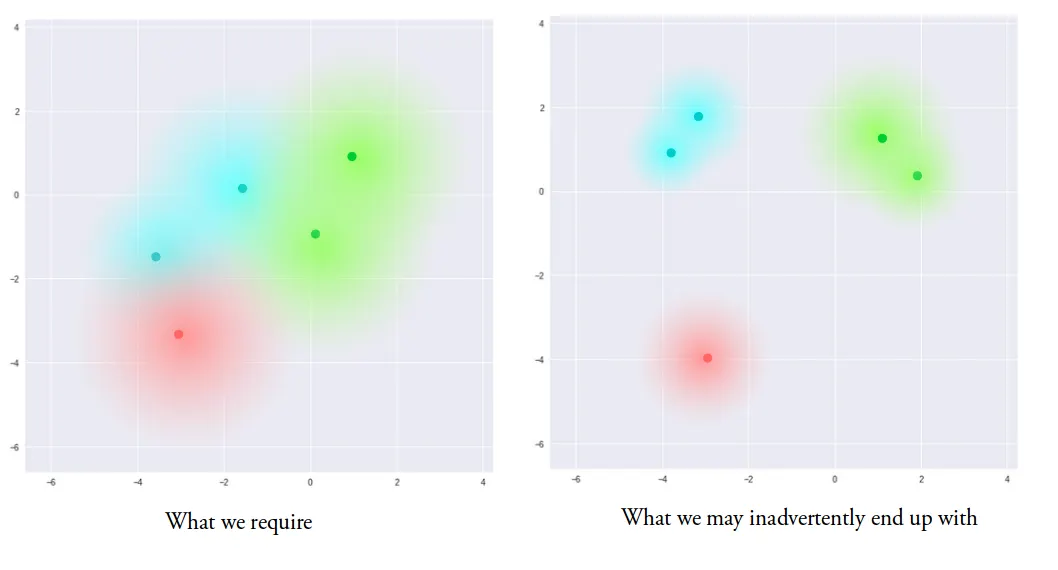
But based on the link you sent, it looks like what we're doing is creating multiple distributions each of which we want patterned on the standard normal. The key diagrams are https://miro.medium.com/v2/resize:fit:1400/format:webp/1*96h... and https://miro.medium.com/v2/resize:fit:1400/format:webp/1*xCj.... You want the little clouds around each dot to be roughly the same shape. Intuitively, it seems like we want to add noise in various places, and we want that noise to be Gaussian noise. So to achieve that we measure the "distance" of each of these distributions from the standard Gaussian using KL divergence.
To me, it seems like one way to look at this is that the KL divergence is essentially a penalty term and it's the reconstruction loss we really want to optimize. The KL penalty term is there to serve essentially as a model of smoothness so that we don't veer too far away from continuity.
This might be similar to how you might try to optimize a model for, say, minimizing the cost of a car, but you want to make sure the car has 4 wheels and a steering wheel. So you might minimize the production cost while adding penalty terms for designs that have 3 or 5 wheels, etc.
But again I really want to emphasize that I don't know this field and I don't know what I'm talking about here. I'm just taking a stab.
> To this end, we train the same autoencoder architecture used for the original Stable Diffusion at a larger batch-size (256 vs 9) and additionally track the weights with an exponential moving average. The resulting autoencoder outperforms the original model in all evaluated reconstruction metrics
And if you look at the SD-XL VAE config file, it has a scaling factor of 0.13025 while the original SD VAE had one of 0.18215 - so meaning it was also trained with an unbounded output. The architecture is also the exact same if you inspect the model file.
But if you have any details about the training procedure of the new VAE that they didn’t include in the paper, feel free to link to them, I’d love to take a look.
With the appropriate GAN loss, you will instead get a plausible sharp image that differs more and more from the original the more you weigh the KL loss term. A classic GAN that samples from the normal distribution in fact has the best possible KL divergence loss and none of the blurriness from a VAE’s pixel based loss.
https://www.youtube.com/watch?v=vJo7hiMxbQ8 autoencoders
https://www.youtube.com/watch?v=x6T1zMSE4Ts NVAE: A Deep Hierarchical Variational Autoencoder
https://www.youtube.com/watch?v=eyxmSmjmNS0 GAN paper
and then of course you need to check the Stable Diffusion architecture.
oh, also lurking on Reddit to simply see the enormous breadth of ML theory: https://old.reddit.com/r/MachineLearning/search?q=VAE&restri...
and then of course, maybe if someone's nickname has fourier in it, they probably have a sizeable headstart when it comes to math/theory heavy stuff :)
and some hands-on tinkering never hurts! https://towardsdatascience.com/variational-autoencoder-demys...
In regular terms he's saying the outputs aren't coming out in the same dimensions that the next stages cn work with properly. It wants values between -1 and +1 and it isn't guaranteeing it. Then he's saying you can make it quicker to process by putting the data into a more compact structure for the next stage.
The discriminator could be improved. i.e we could capture better input
KL Diversion is not an accurate tool for manipulating the data, and we have better.
ML is a huge pot of turning regular computer science and maths into intelligible papers. If you'd like assurance, look up something like MinMax functions and Sigmoids. You've likely worked with these since you progressed from HelloWorld.cpp but wouldn't care to shout about them in public
* multiple sources including OP:
"The SDXL VAE of the same architecture doesn't have this problem,"
"If future models using KL autoencoders do not use the pretrained CompVis checkpoints and use one like SDXL's that is trained properly, they'll be fine."
"SDXL is not subject to this issue because it has its own VAE, which as far as I can tell is trained correctly and does not exhibit the same issues."
It's been a few years since I worked on any program using boost asio, but at least back then if you straced it you'd find it constantly attempting to malloc hundreds of TB of ram, failing harmlessly, then continuing on with its life. (bet that will be fun when someone tries to run it on a system that supports that much virtual address space)
Similarly anything with any kind of feedback correction. PID controllers, codecs that code residuals-- you can get things horribly wrong and the later steps will paper it over.
Taking a step back you can even say that common software development practices-- a kind of meta program-- have the issue: A drunk squirrel sends you a patch full of errors, your test suite flags some which you fix. Then you ship all the bugs you didn't catch, because the test suite caused you to fix some issues but didn't change the fact that you were accepting code from a dubious source.
So I would say that the ML world is only special in that they exist almost entirely of self-correcting mechanisms and that inconsistent performance is broadly expected to a vastly greater degree, so when errors leak through you still may not react. If a calculator app told you that 2+2=5 you'd immediately be sure that something is actually broken, while if some LLM does it, it could just be an expected limitation (or even just sampling bad luck).
- Bounding the outputs to -1, 1 and optimising the variance directly to make it approach 1
- Increasing the number of channels to 8, as the spatial resolution reduction is most important for latent diffusion
- Using a more modern discriminator architecture instead of PatchGAN’s
- Using a vanilla AE with various perturbations instead of KL divergence
Now SD-XL’s VAE is very good and superior to its predecessor, on account of an improved training procedure, but it didn’t use any of the above tricks. It may even be the case that they would have made no difference in the end - they were useful to me in the context of training models with limited compute.
- Although the best results for a stand-alone VAE might require increasing the KL loss weight as high as you can to reach an isotropic gaussian latent space without compromising reconstruction quality, beyond a certain point this actually substantially decreases the ability of the diffusion model to properly interpret the latent space and degrades generation quality. The motivation behind constraining the KL loss weight is to ensure the VAE only provides _perceptual_ compression, which VAEs are quite good at, not _semantic_ compression, for which VAEs are a poor generative model compared to diffusion. This is explained in the original latent diffusion paper on which Stable Diffusion was based: https://arxiv.org/pdf/2112.10752.pdf
- You're correct that trading dimensions for channels is a very easy way to increase reconstruction quality of a stand-alone VAE, but it is a very poor choice when the latents are going into a diffusion model. This again makes the latent space harder for the diffusion model to interpret, and again isn't needed if the VAE is strictly operating in the perceptual compression regime as opposed to the semantic compression regime. The underlying reason is channel-wise degrees of freedom have no inherent structure imposed by the underlying convolutional network; in the limit where you hypothetically compress dimensions to a single point with a large number of channels the latent space is completely unstructured and the entropy of the latents is fully maximized; there are no patterns left whatsoever for the diffusion model to work with.
TLDR: Designing VAEs for latent diffusion has a different set of design constraints than designing a VAE as a stand-alone generative model.
{kind=link}
{kind=link}
{kind=link}
{kind=link}